-
Reading Group Paper. Aggregate VM: Why Reduce or Evict VM’s Resources When You Can Borrow Them From Other Nodes?
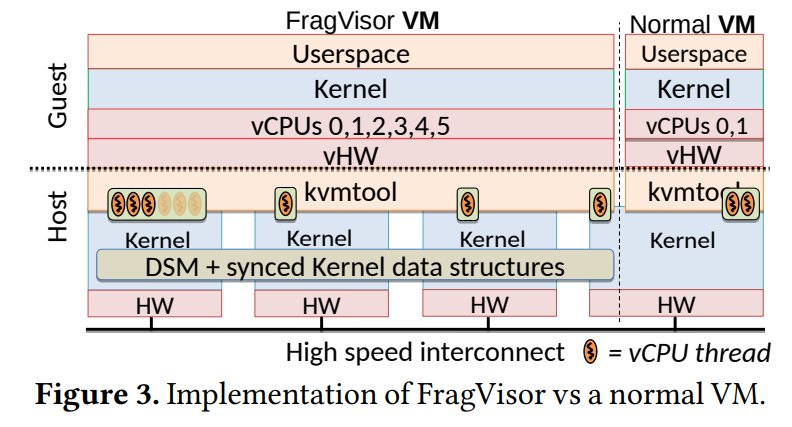
In our recent reading group meeting, we discussed “Aggregate VM: Why Reduce or Evict VM’s Resources When You Can Borrow Them From Other Nodes?” by Ho-Ren Chuang, Karim Manaouil, Tong Xing, Antonio Barbalace, Pierre Olivier, Balvansh Heerekar, Binoy Ravindran. This EuroSys’23 paper introduces the concept of Aggregate VM to allow the pooling of small unused…
-
Reading Group Paper: Hyrax: Fail-in-Place Server Operation in Cloud Platforms
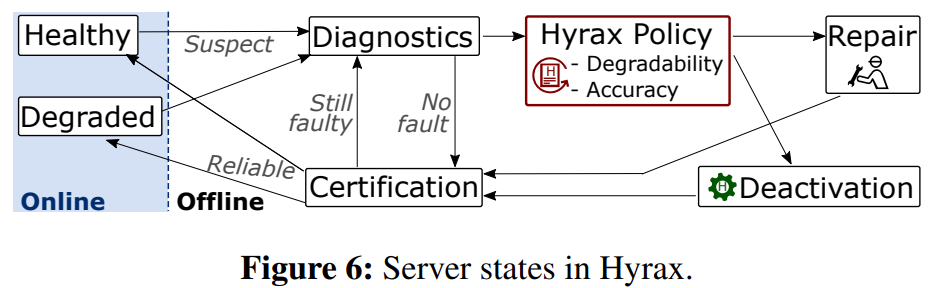
In the 142nd reading group meeting, we discussed “Hyrax: Fail-in-Place Server Operation in Cloud Platforms” OSDI’23 paper. Hyrax allows servers with certain types of hardware failures to return to service after some software-only automated mitigation steps. Traditionally, when a server malfunctions, the VMs are migrated off of it, then the server gets shut down and…
-
Fall 2023 Reading Group Papers (##141-150)

The schedule is also in our Google Calendar. Omni-Paxos: Breaking the Barriers of Partial Connectivity (EuroSys’23) Authors: Harald Ng, Seif Haridi, Paris Carbone What: Multi-Paxos flavor with better tolerance for partial network partitions When: August 30th Hyrax: Fail-in-Place Server Operation in Cloud Platforms (OSDI’23) Authors: Jialun Lyu, Marisa You, Celine Irvene, Mark Jung, Tyler Narmore,…
-
Spring Term Reading Group Papers: ##131-140
A new set of papers for spring and early summer! Transactions Make Debugging Easy [CIDR’23] Authors: Qian Li, Peter Kraft, Michael Cafarella, Çağatay Demiralp, Goetz Graefe, Christos Kozyrakis, Michael Stonebraker, Lalith Suresh, and Matei Zaharia What: Everything is a database transaction, including debugging When: April 12th Perseus: A Fail-Slow Detection Framework for Cloud Storage Systems…
-
Reading Group. DeepScaling: microservices autoscaling for stable CPU utilization in large scale cloud systems
In the 127th meeting, we discussed the “DeepScaling: microservices autoscaling for stable CPU utilization in large scale cloud systems” SoCC’22 paper by Ziliang Wang, Shiyi Zhu, Jianguo Li, Wei Jiang, K. K. Ramakrishnan, Yangfei Zheng, Meng Yan, Xiaohong Zhang, Alex X. Liu. This paper argues that current Autoscaling solutions for Microservice applications are lacking in…
-
Reading Group. Method Overloading the Circuit
In the 126th reading group meeting, we continued talking about the reliability of large distributed systems. This time, we read the “Method Overloading the Circuit” SoCC’22 paper by Christopher Meiklejohn, Lydia Stark, Cesare Celozzi, Matt Ranney, and Heather Miller. This paper does an excellent job summarizing a concept of a circuit breaker in microservice applications.…
-
Reading Group. How to fight production incidents?: an empirical study on a large-scale cloud service
In the 125th reading group meeting, we looked at the reliability of cloud services. In particular, we read the “How to fight production incidents?: an empirical study on a large-scale cloud service” SoCC’22 paper by Supriyo Ghosh, Manish Shetty, Chetan Bansal, and Suman Nath. This paper looks at 152 severe production incidents in the Microsoft…
-
Reading Group. Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service
In the 120th DistSys meeting, we talked about “Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service” ATC’22 paper by Mostafa Elhemali, Niall Gallagher, Nicholas Gordon, Joseph Idziorek, Richard Krog, Colin Lazier, Erben Mo, Akhilesh Mritunjai, Somu Perianayagam, Tim Rath, Swami Sivasubramanian, James Christopher Sorenson III, Sroaj Sosothikul, Doug Terry, Akshat Vig.…
-
Reading Group. The Case for Distributed Shared-Memory Databases with RDMA-Enabled Memory Disaggregation
In the 122nd reading group meeting, we read “The Case for Distributed Shared-Memory Databases with RDMA-Enabled Memory Disaggregation” paper by Ruihong Wang, Jianguo Wang, Stratos Idreos, M. Tamer Özsu, Walid G. Aref. This paper looks at the trend of resource disaggregation in the cloud and asks whether distributed shared memory databases (DSM-DBs) can benefit from…
-
Reading Group. Not that Simple: Email Delivery in the 21st Century
I haven’t been posting new reading group paper summaries lately, but I intend to fix that gap and resume writing these. Our 123rd paper was about email: “Not that Simple: Email Delivery in the 21st Century” by Florian Holzbauer, Johanna Ullrich, Martina Lindorfer, and Tobias Fiebig. This paper studies whether different emerging standards and technologies impact email delivery…
 I am an assistant professor of computer science at the University of New Hampshire. My research interests lie in distributed systems, distributed consensus, fault tolerance, reliability, and scalability.
I am an assistant professor of computer science at the University of New Hampshire. My research interests lie in distributed systems, distributed consensus, fault tolerance, reliability, and scalability.
 @AlekseyCharapko
@AlekseyCharapko
 aleksey.charapko@unh.edu
aleksey.charapko@unh.edu