In the 120th DistSys meeting, we talked about “Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service” ATC’22 paper by Mostafa Elhemali, Niall Gallagher, Nicholas Gordon, Joseph Idziorek, Richard Krog, Colin Lazier, Erben Mo, Akhilesh Mritunjai, Somu Perianayagam, Tim Rath, Swami Sivasubramanian, James Christopher Sorenson III, Sroaj Sosothikul, Doug Terry, Akshat Vig.
The paper is loaded with content as it presents many different things, spanning ten years of development. None of the topics are covered in great detail, but I think it is still a great overview of such a massive project. Obviously, the authors discuss DynamoDB, its architecture, and its design. The paper also provides a brief history of the system and examines several challenges/lessons the team has learned while operating such a massive scale system.
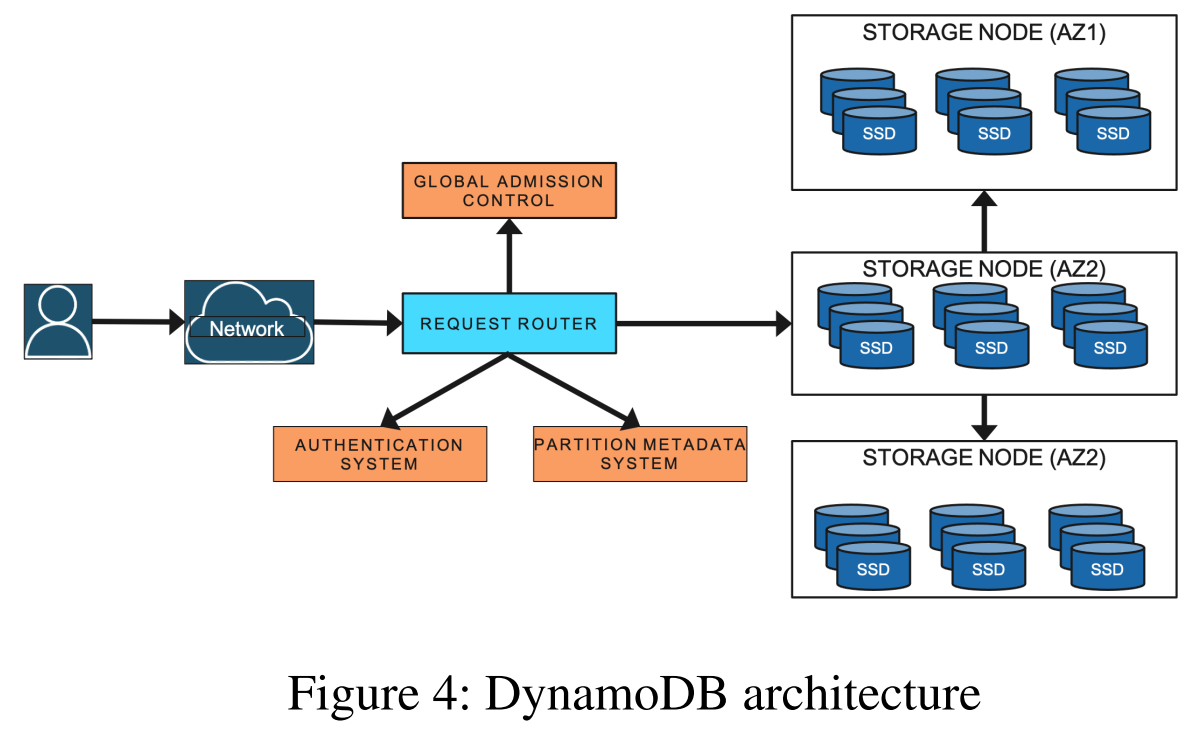
To start with the architecture, the users interact with the system by reaching out to the request router. The router can perform the authentication and admission control. Most importantly, however, the router has access to partition metadata, allowing it to, well, route the requests to proper storage nodes and replicas. A node hosts multiple replicas for different partitions.
So, speaking of partitions, each data item in DynamoDB has a unique primary key. These primary keys group items into partitions replicated with Multi-Paxos for redundancy across multiple replicas in different availability zones. The assignment of key ranges to partitions (and partitions to nodes?) constitute the metadata needed for the request router.
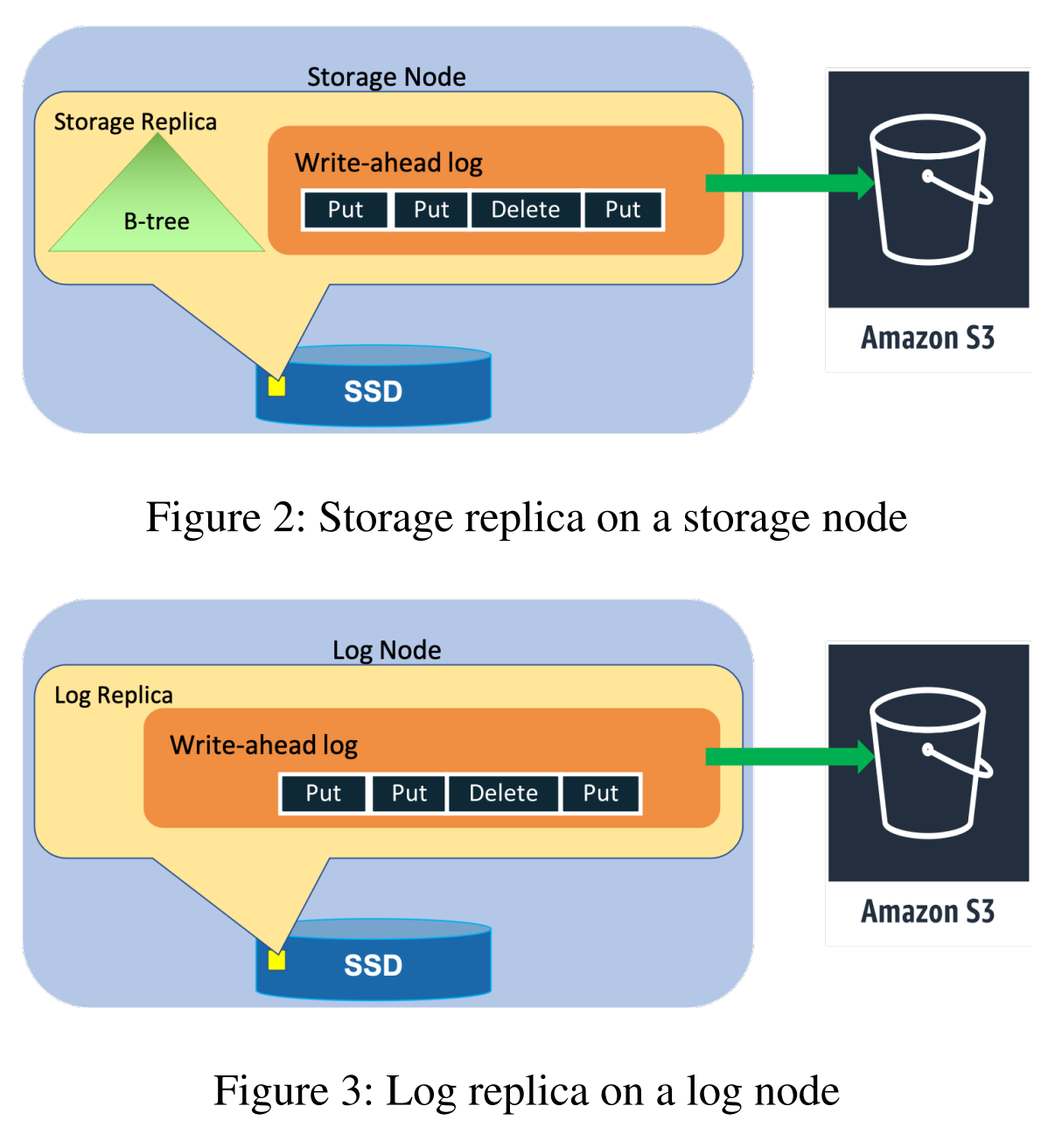
DynamoDB has two types of replicas — log and storage replicas. Log replicas only contain replication write-ahead logs. Storage replicas, in addition to having a log, also maintain a state derived from applying/executing the logged commands against the B-tree storage. Both replica types can participate in Paxos quorums, but log replicas are more lightweight and cannot serve reads/queries. The system uses log replicas to improve availability and reliability — it is easier to spin up a log replica that only needs to accept new commands than to rebuild a full storage replica with all the partition’s data. This speed becomes important under failures to restore the system to the proper degree of replication quickly.
From the historical perspective, while DynamoDB started as a pretty basic NoSQL (key-value) store, it has added many features over time, such as secondary indexes, JSON documents, encryption, transactions, and more.
Finally, a decent chunk of the paper focuses on various nuances of running large-scale NoSQL data stores. For example, the paper notes data errors and how DynamoDB verifies the data integrity with checksums for every data transfer between nodes. DynamoDB also does background data verification at rest. Another important lesson on the reliability side of things is the need to maintain enough capacity in the metadata system. While the request routers use caches for metadata to improve performance, a metastable failure in the caching system led to a rather big outage. After the fact, the caches are used only to improve the latency, and no longer offload capacity from the main metadata storage service — all requests for metadata go through to the service even if they are answered by the cache first. This ensures having adequate capacity to serve critical metadata operations regardless of the cache failures. Naturally, this is a more expensive solution for the sake of reliability.
The authors discuss plenty of other lessons and challenges, such as managing the load and balancing capacity of the system and implementing backups and improving availability.