In the 126th reading group meeting, we continued talking about the reliability of large distributed systems. This time, we read the “Method Overloading the Circuit” SoCC’22 paper by Christopher Meiklejohn, Lydia Stark, Cesare Celozzi, Matt Ranney, and Heather Miller. This paper does an excellent job summarizing a concept of a circuit breaker in microservice applications. The authors discuss several potential problems with circuit breakers, present a taxonomy of circuit breakers, and most importantly, talk about improving circuit breakers and their usage.
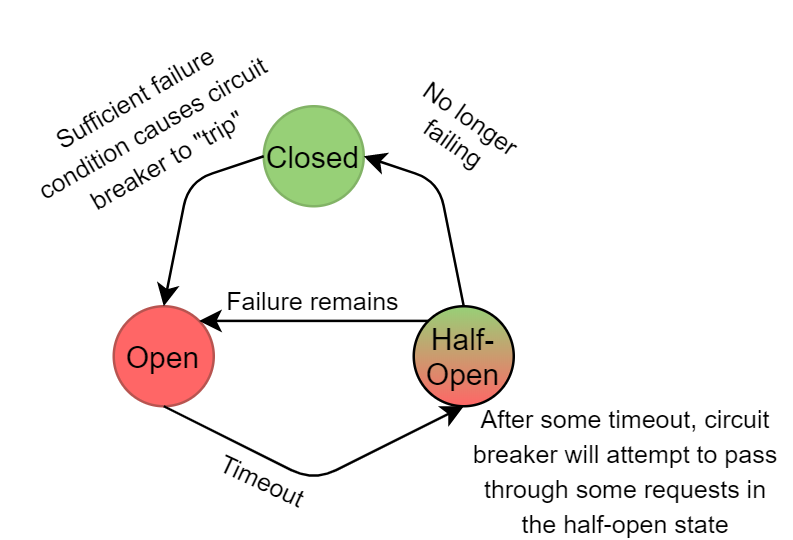
Circuit breakers are mechanisms to stop system overload in the presence of some failures. This is the same task circuit breakers do in the electrical circuits, so CS folks borrowed the name. The idea is to monitor the flow of requests/RPC calls through the system, and if errors start happening along some specific flow, to “break the circuit” and stop the request flow. As such, circuit breakers minimize further damage after the initial failure by dropping potentially problematic work. Naturally, if no requests flow through the system, the application will never learn whether the problem has been rectified. So, to allow recovery, circuit breakers must occasionally go into a “half-open” state and let some requests through. Usually, this happens after a timeout period. If the failure persists, the circuit breaker falls to the open state and continues to shed the problematic work.
The paper presents a motivating example for circuit breakers — some API endpoint is malfunctioning, causing users/client applications to retry. The retries create even more faulty requests, making the failure worse by overloading the system. This example is a Metastable failure with load amplification caused by retries, and as we know, load shedding is a primary mechanism for both preventing metastable failures and recovering from them.
What makes circuit breakers special is the ability to shed load selectively along specific faulty execution paths through the system or for some specific type of request. Going back to the example, dropping only requests that trigger the malfunctioning endpoint in a service allows the system to remain operational for other unaffected path/request flows. Unfortunately, this is not only a strength of circuit breakers but also their weakness — high specificity/selectivity makes them harder to use correctly.
Consider a situation when one API of a service fails. If we use the same circuit breaker for all calls to that service, then this circuit breaker may start seeing an elevated error rate and trip, causing all requests to the service to drop, including the ones that were bound for correctly functioning APIs. Similarly, in the case of one API endpoint, it may be possible that some requests work fine while others do not (for example, requests for some, but not all, users work fine), necessitating a circuit breaker that can distinguish between problematic and ok requests to the same endpoint.
The paper then taxonomizes different circuit breakers based on several criteria, such as their implementation, installation location, and whether the installation is explicit. These criteria impact the circuit breakers’ selectivity or the ability to discriminate/distinguish between different requests and their faults (the paper calls it sensitivity, but I like the word selectivity better, as whether the circuit breaker is more selective to a type of request). For instance, the installation site of circuit breakers plays a substantial role. They can be installed at the callsite, meaning that the circuit breaker installation “wraps around” the RPC call to the dependency service. If the same RPC is called in another place in the code, it will have a different callsite circuit breaker, meaning that these circuit breakers will work independently to determine the faulty conditions. A method-installed circuit breaker appears in the method that calls another service (it can be installed by some method annotations, for example). In this case, all functions calling the method that users other service’s RPC will share the circuit breaker. As you can imagine, this can lead to less sensitivity/selectivity, as many different execution paths may converge on one method that performs an RPC. A client-level circuit breaker can use one shared circuit breaker per client, potentially making it even less sensitive.
Luckily, like in many things distributed, the solution is partitioning. In the case of circuit breakers, we want to be able to partition all possible failure scenarios, execution paths, request configuration, and anything that can impact the request execution into as many separate circuit breakers so that each circuit breaker is as selective to a particular request flow or request type as possible. I think this general suggestion is much easier said than done, and in practice, achieving very good partitioning can be challenging.
Ok, I do not want to rewrite the entire paper in this summary, but there is a lot more content there, including code examples, full taxonomy, some improvements to circuit breakers, and hints at unsolved problems, so please read the paper for more!
Discussion
1) Purpose and challenges. The purpose of circuit breakers is to avoid overloading the system or some of its components by shedding work that is likely to fail. This overload can come from a few sources: (1) retries after the initial failed attempt, (2) some other mitigation and/or client-level workarounds for the failed component, and (3) overload due to expensive error handling. The circuit breakers can do well with overload sources (1) and (3).
Another way to prevent overload, at least due to retries, is to shed only the excess work. See, a circuit breaker sheds all the work that may be problematic, which may not always be a good idea. For instance, if the problem exists due to a high load on some component, stopping all load to it will appear to fix the issue, resetting the circuit breaker and causing the high load to go to the affected component again, causing errors, and tripping the circuit breaker(s) again. I am not entirely sure what is better — a cyclical failure or a persistent one. From the debugging standpoint, I think, a persistent failure may be easier to identify.
So, we may want to shed only excess or extra work, but not the work that would have come organically if there was no failure. This extra load shedding achieves several goals — for faults caused by overload, we avoid cyclical on/off behavior (especially if we can add a simple load shedder on top that can drop any excess “good” work). For non-overload-related failures, sending work through can help with intermittent problems and also speed up recovery once the issue is fixed. Of course, it is not easy to identify and shed that “extra” load under all circumstances; for example, it may be hard to control a person with an itchy “F5 finger” when they do not see a page loading quickly.
Shedding only excess work may have several additional benefits depending on the system. For example, keeping the system busy at the level of the actual organic offered load may help keep the affected/failed services from downscaling due to low load after the circuit breaker trips. Similarly, for cached components, doing work, even such “wasted” work, may keep caches warm for when the problem is fixed. Thinking about the state of the system when the initial problem gets fixed and the circuit breakers reset is important, as it needs to be ready for a quick influx of requests to components that were sitting behind the open circuit breaker for some time.
2) Implementation difficulties. Partitioning the circuit breakers may be hard to implement in large systems, as we need a lot of them to tune the system for proper sensitivity. We also need to have processes/procedures to adapt to changes in the system and make sure that over time old circuit breakers do not cause more harm than good. And finally, with many circuit breakers, there is a question of resource usage. Something has to keep track of all these circuit breakers, their timers, failure counts, etc.
3) From microservices to stateful systems. Our reading group has been gravitating toward distributed systems with the large state — databases, data stores, etc. So naturally, is there anything similar that can be done in these large systems? Metastable failures can be devastating for these, especially as scaling stateful services is a challenging and resource-intensive process that often cannot be done when the system is overloaded. The basic principles remain the same — these systems need to shed load when they are overloaded. The big question is what work to drop and where in the system to do so.
On another hand, databases do not just exist by themselves, they are used by other apps and services. Can we protect databases/stores from overload with circuit breakers on the app sitting at the database call sites? It is not that easy with the existing circuit breaker design — if the database overloads, all circuit breakers across the app may trip open. The load to the DB will fall, causing the circuit breakers to close, and the process may again repeat in a cyclical pattern. It is possible that we need a smarter “overload-specific” circuit breaker to exist somewhere to drop/prioritize load coming to the stateful components.