In the 125th reading group meeting, we looked at the reliability of cloud services. In particular, we read the “How to fight production incidents?: an empirical study on a large-scale cloud service” SoCC’22 paper by Supriyo Ghosh, Manish Shetty, Chetan Bansal, and Suman Nath. This paper looks at 152 severe production incidents in the Microsoft Teams service. The authors looked at these incidents and distilled them into a handful of categories in terms of the root cause, mitigation type, detection, etc. And from placing the incidents into such categories/buckets, some interesting patterns started to emerge regarding the timeliness of incident mitigation, mitigation approaches, and potential areas for improvement.
I liked that the paper described their data collection methodology since the categorizations may be rather subjective. However, I will mention only one detail — the authors assigned a single root cause to each incident, even though some incidents are complex and may have more than one contributing factor. I also like that the paper cautions readers from making hasty generalizations — the study focuses on just one large service, and many of the findings may be specific to that service.
So, with the above disclaimer in mind, what have we learned from the paper? The paper’s findings can be roughly broken down into a handful of topics: root cause, detection, mitigations, and post-incident lessons learned by the team/engineers.

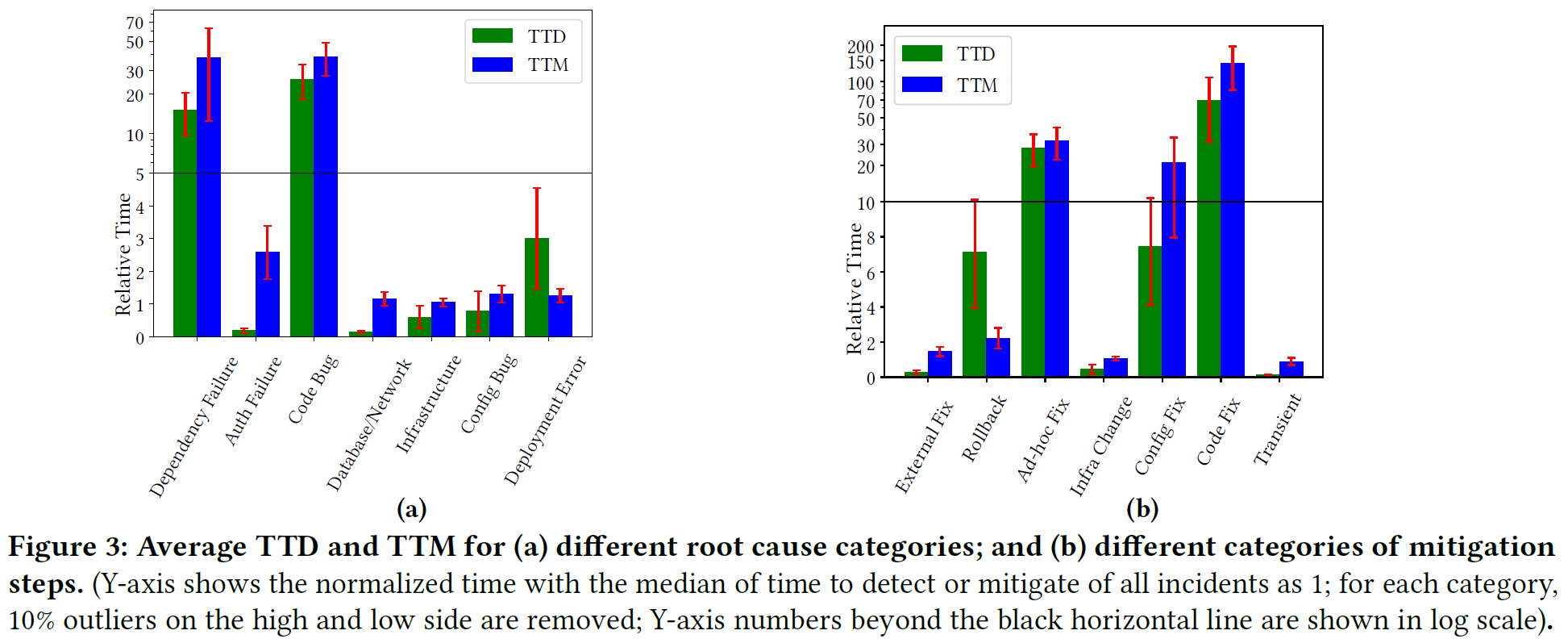
On the root cause side of things, different bugs in the service (Teams) only make up roughly 40% of the incidents (27% code bugs + 13% configuration bugs). Other categories include infrastructure failures, deployment failures, and authentication problems. On the infrastructure side of things, the paper separates infrastructure failures into three different categories. The first one, referred to as “infrastructure failures,” deals with scalability problems, like the inability to get enough nodes to run the work. The second infrastructure root cause bucket is “dependency failures.” Finally, the failures of databases & network dependencies get their own root cause category. But if we combine the three together, all infrastructure failures are around 40%.

On the detection side, the paper suggests a significant deficiency in detection and monitoring systems and practices. Almost half of all incidents had some kind of detection malfunction, with 29% of incidents reported by external users and another 10% reported by internal users! If we look at the automated detection issues, many are due to bugs, lack of automated monitors, or lack of telemetry.
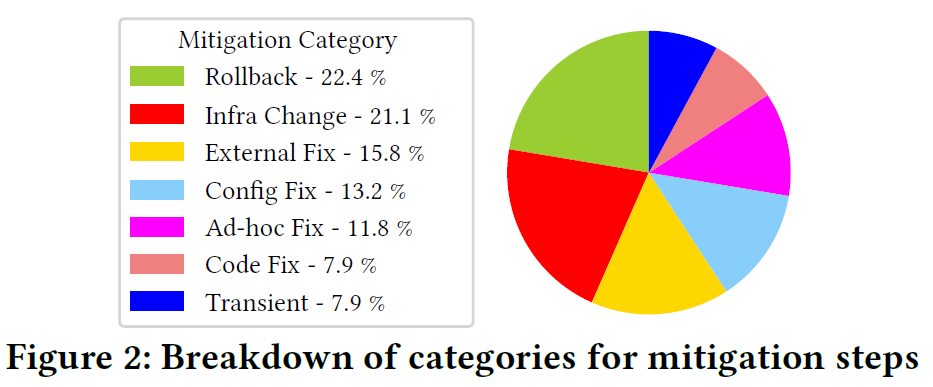
For incident mitigations, the authors discuss the common types of mitigations and the reasons for some of these mitigations requiring more time to address the problem. While around 40% of issues were due to bugs, only 21% of all mitigations required a bug fix (8% for fixing code and 13% for fixing config). Additionally, 11% of issues relied on some “ad-hoc” fixes, which the authors describe as “hot-fixes.” The paper conjectures that it takes substantial time to go through the process of fixing bugs during mitigation. Instead, a faster way to recover is to initiate a rollback (22% of cases) or perform an “infrastructure change” (another 22% of incidents). By “infrastructure change” the authors mean scaling the system to take on more nodes/CPU.
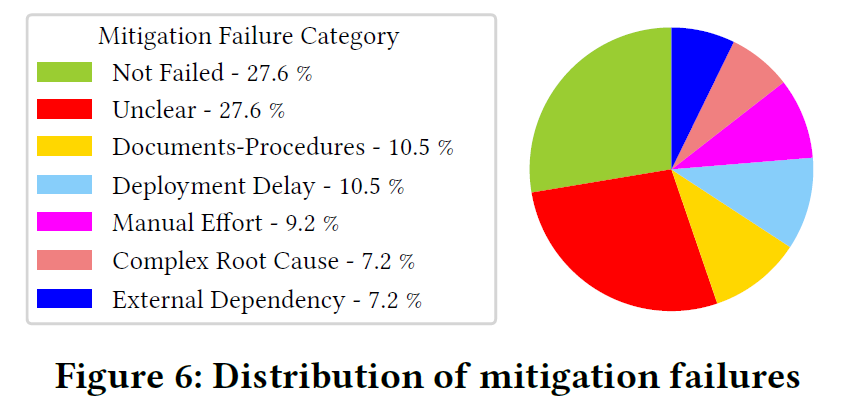
As for mitigation delay reasons (the paper calls them mitigation failures, although the mitigations themselves did not fail but instead took longer), the authors describe several common causes. Inadequate documentation and procedures are at the top of the list. Another common one is deployment delay which occurs when it takes a lot of time to deploy the fix.
With all of the above findings, the lessons learned by the engineers come to the following: need more automation, need more testing and need more changes within the organization (behavioral change, better documentation, better coordination). I want to focus a bit on the automation part, as it hits a bit too close to home for me. Most automation suggestions (26%) boil down to better tests, such as performance tests, chaos engineering, and better end-to-end testing. I am a bit skeptical about these numbers as testing is something we blame all the time when problems occur — it is a reflex response to say that more testing is needed. And of course, we need more testing but mind you, these same people who call for more testing when dealing with issues, write features and (inadequate?) tests when they are not on call.
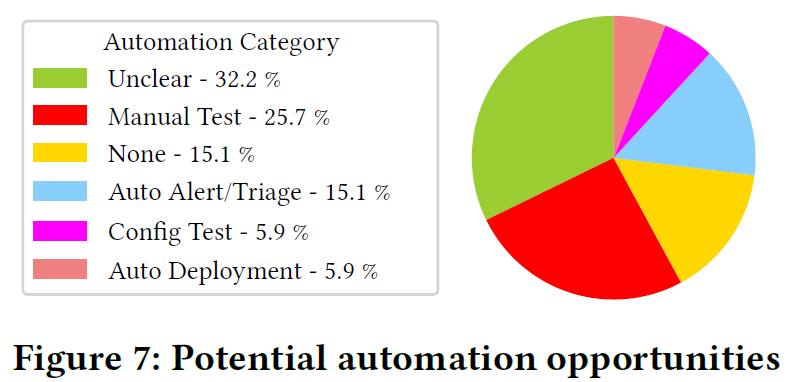
What caught my attention is the need for automated deployment. More specifically, “automated deployment” includes “automated failover.” Just the fact that this is a recurring ask from engineers puzzles me a lot. This means that at least a handful of times per year, running Microsoft Teams requires engineers to manually reconfigure the system to remove failed nodes/machines/services and switch the load to new/backup ones.
The authors discuss several more insights after doing a multidimensional analysis. I am not going to go in-depth here, and instead, just leave snippets of the paper:

Discussion
1) General Applicability of results. As mentioned in the paper, all observations are taken from one service, so your mileage may vary. Another point to note is that Microsoft is a large organization with decently mature monitoring, automation and deployment tools, which may impact the number and severity of observed incidents. It is quite possible that with a less mature set of tools, one may observe more variety of serious problems.
Another point to mention with regard to applicability is that there are many other large systems/services that are very different from Microsoft Teams. For example, if we look at systems that maintain a lot of state (i.e., databases), we may see other common root causes and mitigation patterns. For instance, a typical mitigation strategy observed in the paper is throwing more resources at the problem. This strategy works great with systems that run a lot of stateless or small-state components/microservices. Adding more resources allows scaling performance bottlenecks as long as underlying databases/storage dependencies can handle the load. Scaling stateful systems, like databases, often requires spending resources upfront to move data/state around — something a system cannot do well when overloaded.
2) Lack of concrete actionable items. The findings are interesting from an educational standpoint, but they lack clear directions for improvement. The authors give general advice, along the lines of improving testing, building better automation, etc., but there are no concrete steps/procedures that may help improve systems’ reliability. One point made in our discussion is the need to focus on the specific type of problem to find more concrete solutions for that problem.
3) Teams Outage. On the day we discussed this paper, Teams experienced an outage, likely related to some networking configuration issues.