replication
-
HoliPaxos: Towards More Predictable Performance in State Machine Replication

I will be presenting our new paper, “HoliPaxos: Towards More Predictable Performance in State Machine Replication,” at the VLDB’25. Feel free to ping me if you are there and want to chat! This paper explores several orthogonal optimizations to the classical MultiPaxos state machine replication protocol to improve its performance stability in the presence of
-
Pile of Eternal Rejections: The Cost of Garbage Collection for State Machine Replication

I have a “pile” of papers that continuously get rejected from any conference. All these papers, according to the reviews, “lack novelty,” and therefore are deemed “not interesting” by the reviewing experts. There are some things in common in these papers — they are either observational or rely on old and proven techniques to solve a problem or improve a system/algorithm. Jokingly, I call this set of papers the “pile of
-
Reading Group. Log-structured Protocols in Delos
For the 87th DistSys paper, we looked at “Log-structured Protocols in Delos” by Mahesh Balakrishnan, Chen Shen, Ahmed Jafri, Suyog Mapara, David Geraghty, Jason Flinn Vidhya Venkat, Ivailo Nedelchev, Santosh Ghosh, Mihir Dharamshi, Jingming Liu, Filip Gruszczynski, Jun Li Rounak Tibrewal, Ali Zaveri, Rajeev Nagar, Ahmed Yossef, Francois Richard, Yee Jiun Song. The paper appeared
-
Reading Group. NrOS: Effective Replication and Sharing in an Operating System
The 77thth paper discussion in our reading group was “NrOS: Effective Replication and Sharing in an Operating System” from OSDI’21. While not a distributed systems paper, it borrows high-level distributed systems ideas (namely, state machine replication) to create a new NUMA-optimized sequential kernel. See, all modern machines have many CPU cores. OS kernels must be
-
Reading Group. Avocado: A Secure In-Memory Distributed Storage System
Our 76th reading group meeting covered “Avocado: A Secure In-Memory Distributed Storage System” ATC’21 paper. Unfortunately, the original presenter of the paper could not make it to the discussion, and I had to improvise the presentation on the fly: So, the Avocado paper builds a distributed in-memory key-value database with a traditional complement of operations:
-
Reading Group. Viewstamped Replication Revisited
Our 74th paper was a foundational one — we looked at Viestamped Replication protocol through the lens of the “Viewstamped Replication Revisited” paper. Joran Dirk Greef presented the protocol along with bits of his engineering experience using the protocol in practice. Viestamped Replication (VR) solves the problem of state machine replication in a crash fault
-
Reading Group. Meerkat: Multicore-Scalable Replicated Transactions Following the Zero-Coordination Principle
Our 72nd paper was on avoiding coordination as much as possible. We looked at the “Meerkat: Multicore-Scalable Replicated Transactions Following the Zero-Coordination Principle” EuroSys’20 paper by Adriana Szekeres, Michael Whittaker, Jialin Li, Naveen Kr. Sharma, Arvind Krishnamurthy, Dan R. K. Ports, Irene Zhang. As the name suggests, this paper discusses coordination-free distributed transaction execution. In
-
Reading Group. Fault-Tolerant Replication with Pull-Based Consensus in MongoDB
In the last reading group meeting, we discussed MongoDB‘s replication protocol, as described in the “Fault-Tolerant Replication with Pull-Based Consensus in MongoDB” NSDI’21 paper. Our reading group has a few regular members from MongoDB, and this time around, Siyuan Zhou, one of the paper authors, attended the discussion, so we had a perfect opportunity to
-
Scalable but Wasteful or Why Fast Replication Protocols are Actually Slow
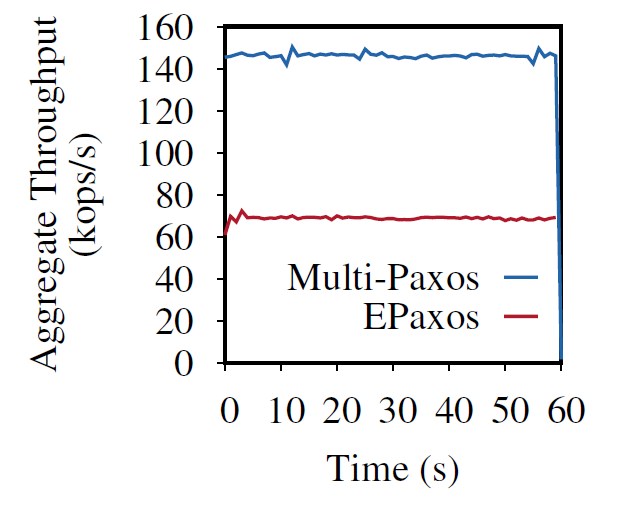
In the last decade or so, quite a few new state machine replication protocols emerged in the literature and the internet. I am “guilty” of this myself, with the PigPaxos appearing in this year’s SIGMOD and the PQR paper at HotStorage’19. There are better-known examples as well — EPaxos inspired a lot of development in
-
Reading Group. Strong and Efficient Consistency with Consistency-Aware Durability
In the 62nd reading group session, we covered the “Strong and Efficient Consistency with Consistency-Aware Durability” paper from FAST’20. Jesse did an excellent presentation for the group that explains the core of the paper rather well: This paper describes a problem with many leader-based replication protocols. It specifically focuses on ZooKeper and Zab, but similar
Search
Recent Posts
- Metastability in Recovery: Cascading Recovery with a Loop
- Murat and Aleksey Read Papers: “Self-Defining Systems”
- Murat and Aleksey Read Papers: “Cloudspecs: Cloud Hardware Evolution Through the Looking Glass”
- Murat and Aleksey Read Papers: “Rethinking the Cost of Distributed Caches for Datacenter Services”
- On Metastable Failures and Interactions Between Systems
Categories
- One Page Summary (12)
- Other Thoughts (16)
- Paper Review and Summary (16)
- Pile of Eternal Rejections (2)
- Playing Around (14)
- Reading Group (104)
- RG Special Session (4)
- Teaching (2)