The 77thth paper discussion in our reading group was “NrOS: Effective Replication and Sharing in an Operating System” from OSDI’21. While not a distributed systems paper, it borrows high-level distributed systems ideas (namely, state machine replication) to create a new NUMA-optimized sequential kernel.
See, all modern machines have many CPU cores. OS kernels must be able to utilize that multi-core hardware to achieve good performance. Doing so implies synchronization between threads/cores for access to shared kernel data structures. Typically, OSes go for a fine-grained synchronization to unlock as much concurrency as possible, making kernels very complex and prone to concurrency bugs. To complicate things further, servers often feature multiple CPUs in multiple different sockets. Each CPU has its own memory controller and can “talk” faster and more efficiently to its share of memory connected to that controller while accessing other CPU’s memory requires communication and extra latency. This phenomenon exists in certain single-socket systems as well. The nonuniformity in memory access (hence Non-Uniform Memory Acess or NUMA) creates additional problems and slowdowns when managing locks.
NrOS, with its NRkernel, differs from other kernels in the way it manages concurrency. Instead of a fine-grained approach, NrOS relies on more coarse-grained concurrency access, as it is a simple sequential kernel that protects the data structures with a simple coarse lock. Such coarse-grained locking can be rather bad for high-core systems with lots of contention. However, not all threads/cores compete for this lock for scalability reasons. To start, NRkernel replicates the shared data structures across NUMA nodes. So now cores on different CPUs/NUMA nodes can access a copy of the shared structure from their local memory. There is one little problem, though. We need to make sure all these copies are in sync so that no core/thread can read stale data structure.
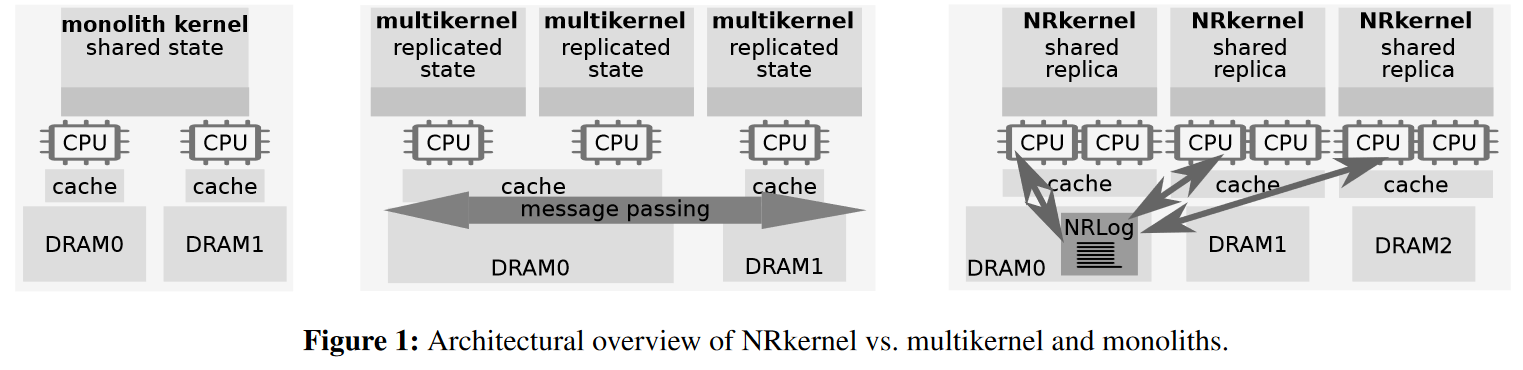
NRKernel solves this using a shared log. All of the copies share a single log structure from which they get their updates. When some thread needs to update a data structure, it tries to acquire a lock to the log to write an update. To reduce the contention of accessing the log, the NRKernel ensures that only one thread per NUMA node can acquire a lock. The kernel achieves that using a flat combining technique where multiple threads can try to access the shared structure, but only one can get the lock. This “lucky” thread becomes the combiner, and in addition to its own access, carries out the operations on behalf of other “not-so-lucky” threads in need of the shared object. Flat combining reduces the lock contention and acts as a batching mechanism where one thread applies operations of all other threads.
The log helps order all updates to the shared data structures, but we still need to make sure reading the replicas is linearizable. The flat combining approach helps us here as well. If a combiner exists for a replica, then the read-thread looks at the current tail of the log and waits for the existing combiner to finish updating the replica up to that tail position. In a sense, such waiting ensures that the read operation is carried out with the freshest update at the time of the read initiation. If no combiner currently exists, the reading thread gets a lock and becomes the combiner, ensuring the local replica is up-to-date before performing the read.
The paper goes on to explain some optimizations to this basic approach. For instance, in some cases, despite the batching and relatively few threads competing for exclusive access, the log becomes overwhelmed. In an Apache Kafka topic-esque way, the paper proposes to use multiple parallel logs for certain data structures to reduce the contention. NRkernel uses operation commutativity to place operations that can be reordered into the parallel logs and operations that have dependencies in the same log. This is similar to handling conflicts in numerous distributed systems, where we allow non-conflicting operations to run in parallel but ensure the partial order for dependant commands.
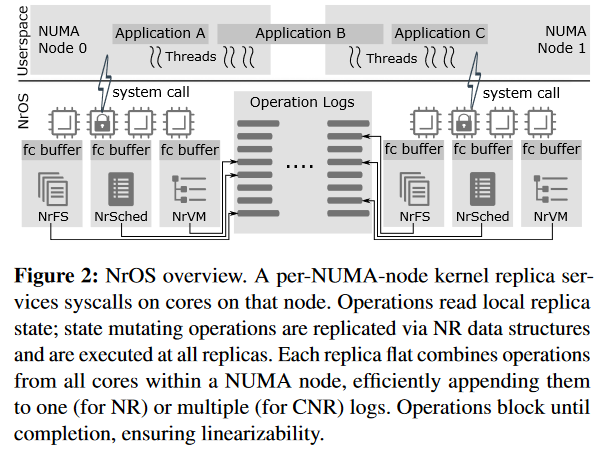
NrOS uses this style of replication across NUMA nodes to support a variety of subsystems: a virtual memory, an in-memory file system, and a scheduler. The paper evaluates these components against Linux, where it shows better performance, and a handful of other research-level operating systems, like Barrelfish, where it shows comparable or better levels of performance.
This is a second botched presentation in a row where I had to scramble and improvise:
Discussion
I will leave this one without a discussion summary. We are not OS experts in this reading group (at least among the people in attendance), and improvised presentation did not facilitate an in-depth exploration of the paper. However, this seemed like a good paper for distributed systems folks to learn about bits of the OS kernel design and make connections. It was also nice to see some real systems (LevelDB) used in the benchmark, although these were tested against an in-memory filesystem, so it is far from a normal use case. A few natural questions arise in terms of the feasibility of the approach in more mainstream OSes. It seems that a huge “philosophical” gap between the NrOS’s solution and how mainstream kernels are designed means that NRkernel is likely to remain an academic exercise.