
I have a “pile” of papers that continuously get rejected from any conference. All these papers, according to the reviews, “lack novelty,” and therefore are deemed “not interesting” by the reviewing experts. There are some things in common in these papers — they are either observational or rely on old and proven techniques to solve a problem or improve a system/algorithm. Jokingly, I call this set of papers the “pile of eternal rejections.” Recently, the pile shrunk, as our observation of cloud latency will finally get a home soon.
Today, however, I want to talk about another eternal rejection — our experience building a state machine replication in different languages, focusing on the comparison between garbage-collected languages and the ones with more manual memory management. The short story is predictable, as manual memory management allows for better performance, especially with regard to tail latency. The long story is much more nuanced. This work was done by Zhiying Liang, Vahab Jabrayilov, Abutalib Aghayev and I.
Our initial idea was to take the MultiPaxos algorithm and design a state machine replication (SMR) system around it. Then we translate the design of Replicant, our MultiPaxos-based SMR, into pseudocode. From this pseudocode, we can implement Replicant in various languages. This approach ensures that implementations in different languages are as uniform as possible, except for some language-specific deviations. From the start, we decided to test four languages: Java, C++, Go, and Rust. Java and C++ represent “legacy” languages, still popular with many older distributed systems. The Go and Rust are the “new kids on the block.”
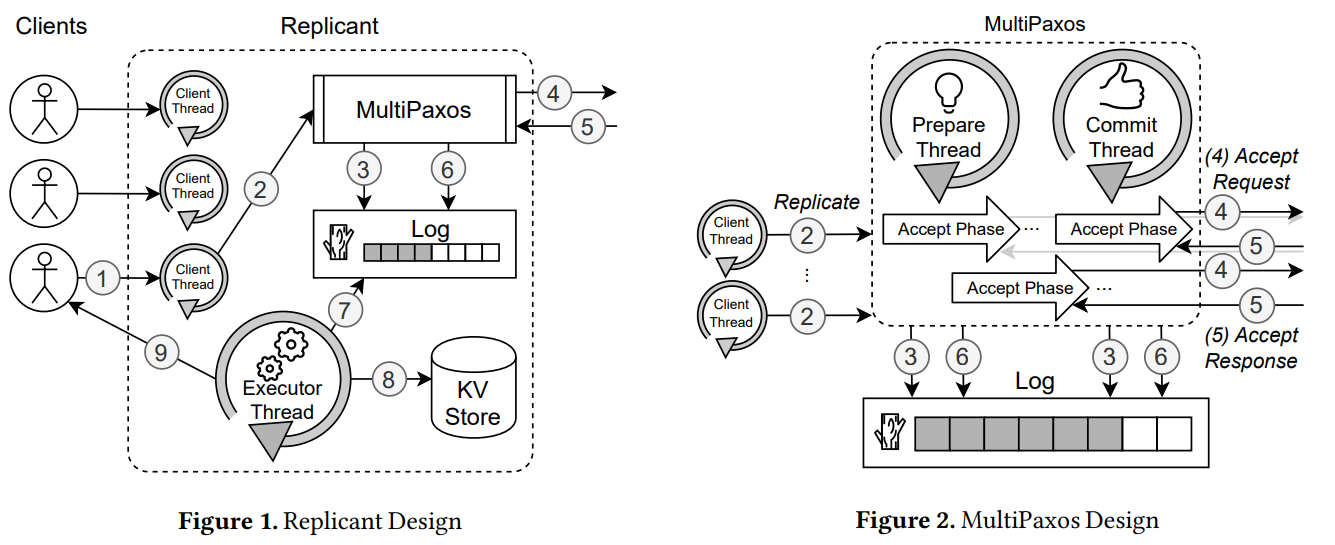
(1) a client issues a command to Replicant; (2) a client handler thread passes the command to MultiPaxos; (3) MultiPaxos creates an instance consisting of the command, index of the instance in Log, ballot number, and client-id, and appends the instance to Log; (4) MultiPaxos sends the accept message with the instance to all other peers, and (5) once it receives an acceptance from the majority of peers, (6) it commits the instance in Log; finally, when an instance is committed in Log, the Executor Thread (7) extracts the command and the client id from the committed instance, (8) executes the command on KVStore, uses the client id to find the corresponding socket descriptor, and (9) writes the response to the client.
Java and Go are garbage-collected languages, while C++ and Rust are not. There are a few other prominent differences in concurrency and networking support. Go’s concurrency model relies on user-mode “goroutines” scheduled by Go’s runtime. While similar lightweight abstractions are available for other languages, some, like Java’s Project Loom, did not perform well in our initial tests. As such, we decided to use OS-level threads and thread pools for Java and C++ and keep the lightweight concurrency primitives for Go and Rust (Tokio).
On the networking side, we initially planned to use gRPC in all four languages. However, Tonic, the gRPC library for Rust did not perform well. We spent quite a bit of time debugging the issue only to realize the problem was in one of the Tonic’s dependencies that uses a global lock to manage HTTP2 streams (RPCs in gRPC correspond to HTTP2 streams), limiting the scalability of Tonic. Anyway, with the concurrency and networking quirks, we got to the final implementation configuration for all four languages. We have two language groups—legacy (Java and C++) and newer (Go and Rust) languages. The legacy group uses system threads and thread pools and gRPC for networking, while the “new” languages rely on a lightweight threading model and TCP sockets for communication.
Our initial implementation of Replicant in Rust with gRPC performed poorly, delivering roughly a third of the performance of Replicant in Go, forcing us to ditch gRPC and create TCP implementations in Rust and Go.
We ran all experiments on a 3-server setup with each server running Replicant on an m5.2xlarge instance(8 vCPUs, 32 GiB RAM) on AWS. We use Clang C++ compiler v14.0.6, OpenJDK v19.0.1, Go v1.19.1, and Rust v1.64.0. As a benchmark, we run YCSB on a separate m5.2xlarge instance with a variable number of client threads. We choose key and value sizes of 23 and 500 bytes, respectively. For Go and Rust implementations, we also disabled Nagle’s algorithm by setting the TCP_NODELAY option on a socket.
In our experiments, we measured the maximum “practical” throughput of each implementation. The “practical” part is important here — instead of squeezing every last bit of throughput, we went for the maximum throughput a system can deliver before blowing through the 99th percentile latency threshold of 20 ms. In other words, the throughput we show has a latency constraint of a system not exceeding 20 ms, a mark that we thought was acceptable for many practical scenarios.
We have two main experiments. In the first one, we show how a language behaves in a memory-constrained environment as the available memory decreases from 32GB all the way down to 5 GB (our system is in memory, and the dataset is roughly 4GB). The second experiment uses a full 32GB of RAM but constraints the number of vCPUs from 8 all the way down to 2 (which corresponds to one physical core). For the brevity of this post, I will focus on YCSB workload A with 50% reads. Our report also includes data for a more read-heavy workload B.
Legacy Languages (Java vs C++)
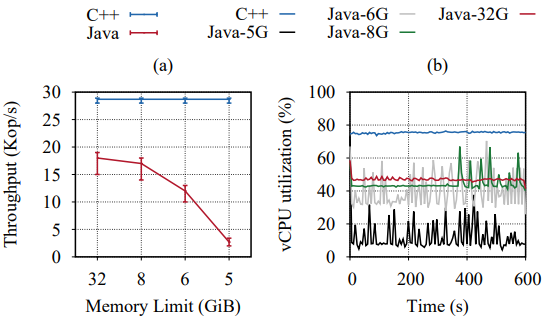
(a) Maximum achievable throughput of C++ and Java with 99th percentile latency of 20 ms under workload A with 8 vCPUs. C++ remains constant at around 28.7 Kops/s while Java drops from 18 Kops/s to 3 Kops/s when the memory decreases from 32 GiB to 5 GiB.
(b) The aggregate vCPU utilization of C++ and Java on a Replicant leader during the same experiments; the vCPU utilization of C++ stays the same across experiments. (Java-5G corresponds to vCPU utilization when using 5 GiB memory size).
The figure above shows the relative performance of Replicant in Java and C++, the two legacy languages we picked with threads as the concurrency model. In Figure (a), we can see the impact of reduced memory on the performance of the Java version. With ample memory, it delivers roughly two-thirds of C++’s throughput under the 20-ms tail latency constraint. With significant memory reduction, Java’s performance tanks, while C++ remains the same. This is an indirect observation of the cost of garbage collection. Figure (b) shows the CPU usage. Without ample memory, the average CPU utilization of Java’s version goes down but the variance in CPU consumption goes up — another indirect indication of GC cost, as Java needs to spend more time doing GC when under memory pressure (in our implementation, used log entries are retired and can be easily garbage collected).
It is also worth pointing out that Java uses less CPU and delivers less throughput. One may speculate that this is a bug in the implementation, causing the system to leave unused CPU “on the table.” However, this is actually an artifact of the resolution at which we measure the CPU utilization. See, even with ample memory, when Java runs GC, the CPU usage goes up for a super brief amount of time. These micro-spikes are enough to create a stutter and drive tail latency higher without significantly registering on our CPU usage monitoring script. As a result, Java’s throughput in our tests is not limited by the lack of raw available CPU; instead, we need plenty of unused CPU to avoid queuing effects when the GC kicks in, even for a few milliseconds. We can also see this effect in the figure below. As we cut the available CPU in half, from 8 vCPUs down to 4, the throughput of memory-unconstrained Java also goes down — the system needs to have enough idle CPU to avoid CG-induced queuing effects and associated tail latency.

(a) Maximum achievable throughput of C++ and Java with 99th percentile latency of 20 ms under workload A with different vCPU configurations and 32 GiB of memory.
(b) The aggregate vCPU utilization of C++ and Java on a Replicant leader during the same experiments (Java-2 corresponds to vCPU utilization when using 2 vCPUs).
“New” Languages (Go vs Rust)
The story with new languages is very similar to the legacy one, aside from the generally higher level of performance enabled by the lightweight concurrency and TCP sockets instead of gRPCs.
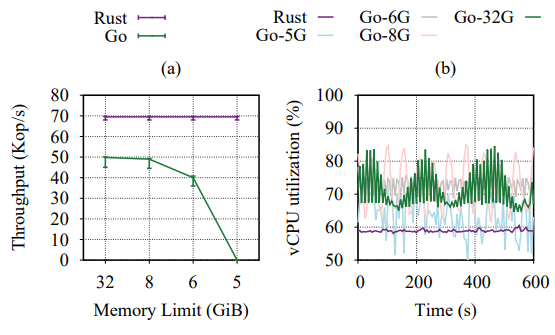
(a) Maximum achievable throughput of Rust and Go with 99th percentile latency of 20 ms under workload A with different memory configurations and 8 vCPUs.
(b) The aggregate vCPU utilization of Rust and Go on a Replicant leader during the same experiments; the vCPU utilization of Rust stays the same across experiments
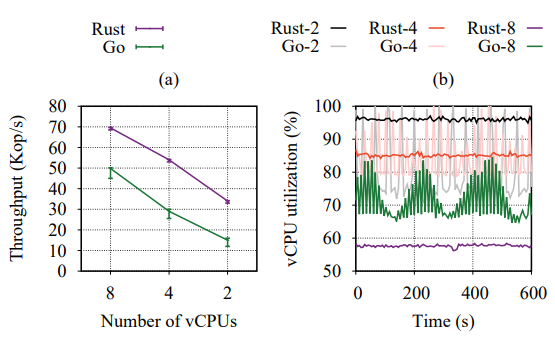
(a) Maximum achievable throughput of Rust and Go with 99th percentile latency of 20 ms under workload A with different vCPU configurations and 32 GiB of memory.
(b) The aggregate vCPU utilization of Rust and Go on a Replicant
leader during the same experiments (Go-2 corresponds to vCPU utilization when using 2 vCPUs).
In addition to the indirect observations of GC costs, we can show a more direct observation of GC activity. The figure below shows the amount of time Go spent doing GC at different levels of available RAM. In that figure, we sampled the runtime every 5 seconds and showed how many CPU seconds were used for GC during each sample. As expected, with less RAM and higher memory pressure, more and more CPU time gets allocated for garbage collection, preventing the timely completion of useful requests.
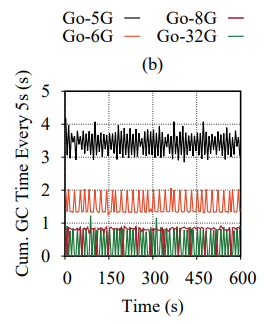
The cumulative runtime of Go’s GC activities using a 5-second window. This data reflects the aggregation of the duration of all GC activites happened within each 5-seond interval. (Go-5G corresponds to the 5 GiB memory size)
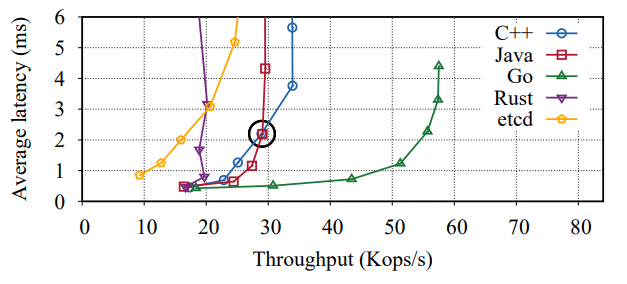
Finally, I want to reiterate that we performed these experiments under the constraint of maximum tail latency. All systems can achieve higher absolute maximum throughput if latency does not matter. For example, the figure below shows that Go can outperform (some) implementation of Replicant in Rust if we only consider average latency and throughput. In that particular experiment, the difference comes down to the memory allocator used in Rust’s version. This example also highlights the difficulties of implementing Replicant in Rust — it took months of development and debugging to get to the Go’s level of performance and even more time to finally beat it not only in the tail-latency constraint experiment but also in pure raw throughput.
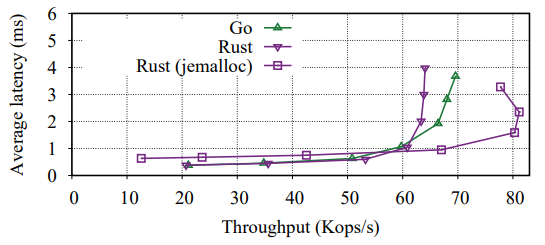
Throughput vs. average latency of Replicant implementations using TCP for inter-peer communication, under YCSB workload A with 2 million entries.
Needles to say, our paper/report has a lot more data and details about our experience building something as complex as state machine replication in four different languages.