Our 76th reading group meeting covered “Avocado: A Secure In-Memory Distributed Storage System” ATC’21 paper. Unfortunately, the original presenter of the paper could not make it to the discussion, and I had to improvise the presentation on the fly:
So, the Avocado paper builds a distributed in-memory key-value database with a traditional complement of operations: Put, Get, Delete. There is also nothing special on the replication side – the system uses ABD, a very well-known algorithm. What makes this paper special is where in memory this database resides.
Unlike the traditional systems, Avocado takes advantage of Trusted Execution Environments (TEE) or enclaves. In particular, the system relies on Intel’s version of the TEE. TEEs have some cool tricks up in their sleeves — the memory is so protected that even privileged software, such as an OS or a hypervisor, cannot access it. This protection means that both the data and the code inside the enclave are secured from malicious corruption.
The paper suggests that these secure environments were not really designed for distributed systems. The problem lies in trust or, more precisely, ensuring that the replicas can trust each other to be correct. Normally, the attestation method would rely on a CPU-vendor service; in this case, it is the Intel attestation service (IAS). IAS would ensure the integrity of code and data in an enclave to the remote party. IAS, however, has some limitations, such as high latency, but it must be used every time a system creates a secure enclave. So Avocado builds its own trust service called configuration and attestation service (CAS). CAS uses IAS for attesting Avacado’s own local attestation service (LAS), and once it is attested, LAS can be used to attest all other enclaves. This kind of builds a longer chain of trust that uses a slow service very infrequently.
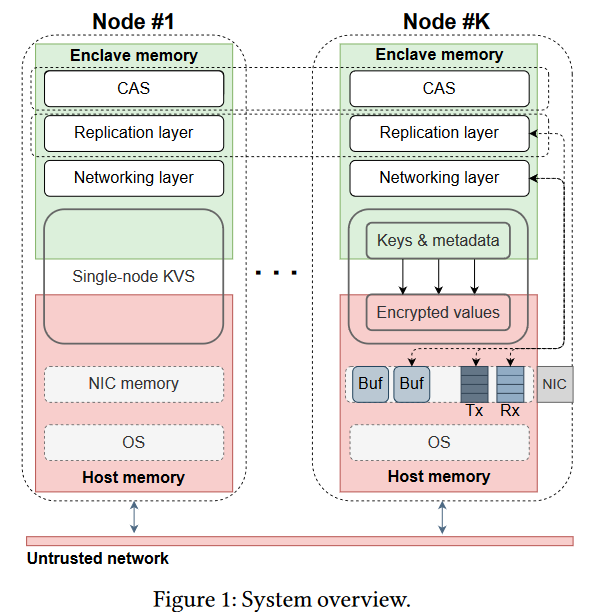
So what do we have so far? We can run code and store some information in secure enclaves. Now we need to ensure our code and our data reside in this secure memory. But things are not so easy here, as the enclaves are relatively small — 128 MB in size and have very slow paging capability if more memory is needed. So our goal is to fit the database in 128 MB of RAM. To make things more complicated, the network is still insecure. Avocado runs most of the code from within the enclave to ensure it is tamper-proof. This code includes CAS, replication protocol (ABD), and the networking stack implemented with kernel bypass, allowing Avocado to pretty much place the encrypted and signed messages straight into the network.
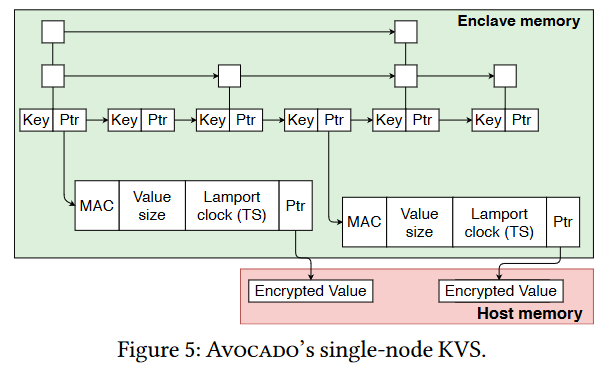
The final piece is a storage component. Naturally, it is hard to store a lot of stuff in 128 MB. Instead of using secure memory for storage, Avocado uses insecure regular host memory for the actual payloads, allowing it to pack more data into one 128 MB enclave. With paging, the system can store even more data, although at some performance cost. The secure tamper-proof enclave only stores metadata about each value, such as a version, checksum, and the pointer to regular host memory with an encrypted value. Naturally, the encryption algorithm is running from within the enclave. Even if someone tries to mess with the value in host memory (i.e., try to replace it), it will be evident from the checksum in the enclave.
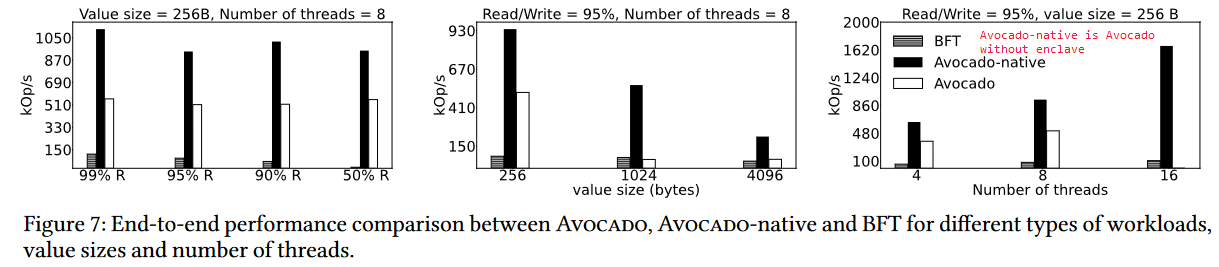
Avocado is a complicated system driven by many limitations of TEEs. Moreover, TEEs significantly hinder the performance, as Avocado running in the secure enclaves is about half as fast as the version running in regular memory.
Discussion
1) Attestation service. I think the biggest challenge for our group was understanding the attestation model. The paper lacks some details on this, and the description is a bit confusing at times. For example, when discussing CAS, the authors bring up the LAS abbreviation without first introducing the term. I think it means Local Attestation Service, but I still cannot be sure. Anyway, our group’s confusion may also come from the lack of prior knowledge, and some googling can resolve it.
2) Fault model. The authors motivate and compare Avocado against Byzantine systems. I purposefully did not mention BFT in my summary, as I think the two solve very different problems. While BFT can tolerate several nodes having corrupt data and code, Avocado operates in a different environment. See, Avocado operates in an environment where we do not trust cloud vendors that host our applications. And then, if a cloud vendor can tamper with one node’s data or code, what can prevent them from changing/corrupting all the nodes? If all nodes are corrupt unknown to the user, then the BFT solutions become rather useless. Avocado security lies in the trust that enclaves are unhackable even to cloud vendors/hosts. With the enclave, we are not building a BFT system (i.e., a system that operates even when some nodes are “out of spec), and instead, we have a system that cannot go out of spec as long as we trust the enclaves. Needless to say, we also need to trust our own code.
3) API model. The system operates on a simple key-value store, that can only put, get, and delete data. While key-value stores are useful as building blocks for many larger systems, these stores often have a more sophisticated API that allows ranged scans. Moreover, an ABD-based system cannot support transactional operations, such as compare-and-set, reducing the utility of this simple kv-store. I wonder, what would it take to make this thing run Multi-Paxos or Raft and add range operations? Is the single-node store a limitation? It uses a skip list, which should be sorted, so I’d suspect range queries should be possible.