For the 87th DistSys paper, we looked at “Log-structured Protocols in Delos” by Mahesh Balakrishnan, Chen Shen, Ahmed Jafri, Suyog Mapara, David Geraghty, Jason Flinn Vidhya Venkat, Ivailo Nedelchev, Santosh Ghosh, Mihir Dharamshi, Jingming Liu, Filip Gruszczynski, Jun Li Rounak Tibrewal, Ali Zaveri, Rajeev Nagar, Ahmed Yossef, Francois Richard, Yee Jiun Song. The paper appeared at SOSP’21. This is a second Delos paper; the first one was “Virtual Consensus in Delos,” and we covered it in the 40th DistSys meeting.
The first Delos paper looked at building the replication/consensus layer to support strongly consistent use-cases on top. The system created a virtual log made from many log pieces or Loglets. Each Loglet is independent of other Loglets and may have a different configuration or even a different implementation. Needless to say, all these differences between Loglets are transparent to the applications relying on the virtual log.
With the replication/consensus covered by virtual log and Loglets, this new paper focuses on creating modular architecture on top of the virtual log to support different replicated applications with different user requirements. In my mind, the idea of the Log-structured protocol expressed in the paper is all about using this universal log in the most modular and clean way possible. One can build a large application interacting with the log (reading and writing) without too many thoughts into the design and code reusability. After all, we have been building ad-hoc log-based systems all the time! On the Facebook scale, things are different — it is not ideal for every team/product to reinvent the wheel. Instead, having a smarter reusable architecture can go a long way in saving time and money to build better systems.
Anyway, imagine a system that largely communicates through the shared log. Such a system can create new log items or read the existing ones. In a sense, each log item is like a message delivered from one place to one or several other locations. With message transmission handled by the virtual log, the Delos application simply needs to handle encoding and decoding these “log-item-messages.”
Fortunately, we already have a good idea about encoding and decoding messages while providing services along the encoding/decoding path. Of course, I am thinking of common network stacks, such as TCP, or even more broadly, the OSI model. Delos operates in a very similar way, but also with a great focus on the reusability and composability of layers. When a client needs to write some data to the log, it can form its client-specific message and pass it down the stack. Lower layers can do some additional services, such as ensuring session guarantees or batching the messages. Each layer of the stack wraps the message it received with its own headers and information needed for decoding on the consumer side. Delos calls each layer in the stack an engine. The propagation down through layers continues until the message hits the lowest layer in the stack — the base engine. The job of the base engine is to interact with the log system.
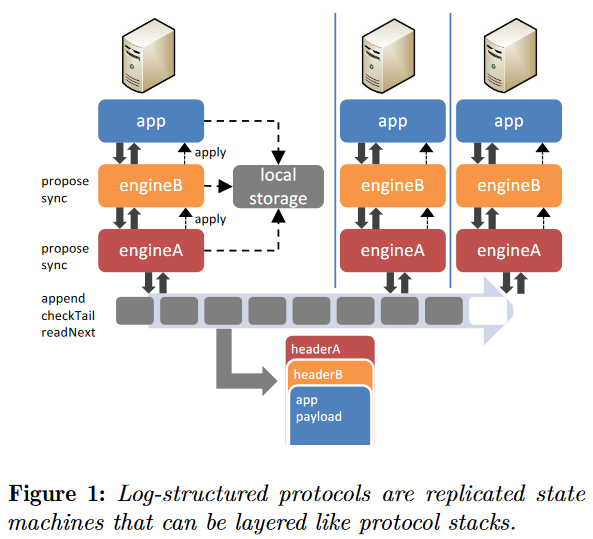
Similarly, when a system reads the message from the log, the log item travels up the stack through all of the same layers/engines, with each engine decoding it and ensuring the properties specific to that engine before passing it up. An imperfect real-world analogy for this process is sending a paper mail. First, you write the letter; this is the highest layer/engine close to the application. Then you put it in the envelope — now the letter is protected from others seeing it. Then goes the stamp — it is ready to be sent, then goes the mailbox — client batching, then post office — server-side batching, then transmission, and then the process starts to get undone from the bottom up.
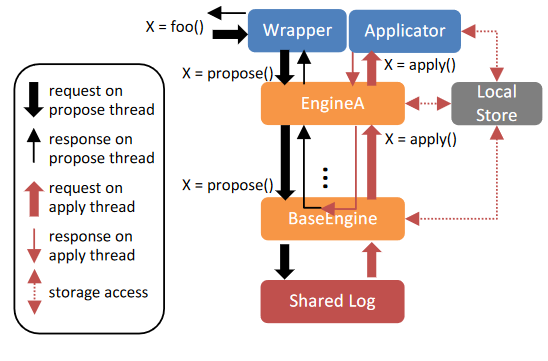
Of course, I oversimplified things a bit here, but such message encapsulation is a pretty straightforward abstraction to use. Delos uses it to implement custom Replicated State Machines (RSMs) with different functionality. Building these RSMs requires a bit more functionality than just pushing messages up and down the engines. Luckily, Delos provides a more extensive API with required features. For example, all engines have access to the shared local storage. Also, moving items up or down the stack is not done in a fire-and-forget manner, as responses can flow between engines to know when the call/request gets completed. Furthermore, it is possible to have more than one engine sitting at the same layer. For instance, one engine can be responsible for serializing the data and pushing it down, and another engine can receive the item from an engine below, deserialize and apply it to RSM. The figure illustrates these capabilities.
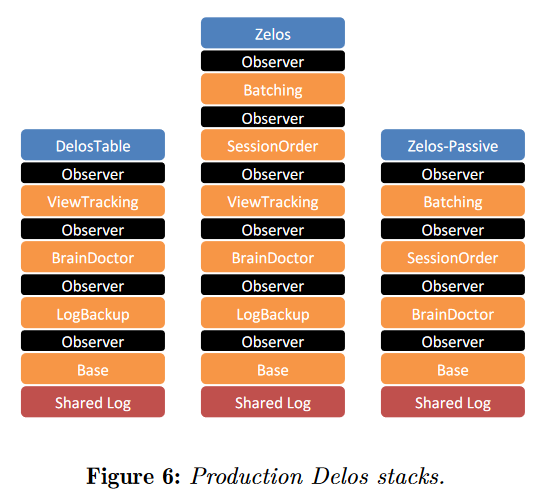
This tiered modular approach allows Delos to reuse layers across applications or even compose some layers in different order. So when one application or use-case needs batching, that engineering team does not need to reinvent the batching from scratch. Instead, they can take an existing batching layer and add it to their stack in the appropriate location. The flexibility and reusability allowed Facebook engineers to implement two different control-plane databases with Delos. One datastore, called DelosTable, uses a table API, while another system, called Zelos, implements a ZooKeeper compatible service.
I think I will stop my summary here. The paper goes into more detail about the history of the project and the rationale for making certain decisions. It also describes many practical aspects of using Delos. The main lesson I learned from this paper is about the overall modular layered design of large RSM-based systems. I think we all know the benefits but may often step aside from following a clean, modular design as the projects get bigger and pressure builds up to deliver faster. But then, what do I know about production-grade systems in academia? Nevertheless, I’d love to see a follow-up paper when more systems are built using Delos.
As usual, we had our presentation. This time Micah Lerner delivered a concise but very nice explanation of the paper:
Discussion.
1) Architecture. This paper presents a clean and modular architecture. I do not think there is anything majorly new & novel here, so I view this paper more like an experience report on the benefits of good design at a large company. I think there is quite a bit of educational value in this paper.
In the group, we also discussed the possibility of applying similar modular approaches to more traditional systems. For instance, we looked at MongoDB Raft in the group before. Nothing should preclude a similar design based on a Raft-provided log in a distributed database. In fact, similar benefits can be achieved — multiple client API, optional and configurable batching functionality, etc. That being said, for a system designed with one purpose, it is easy to start designing layers/modules that are more coupled/interconnected and dependent on each other.
We had another similar observation in the group that mentioned a somewhat similarly designed internal application a while back, but again with a less clear separation between modules/layers.
2) Performance. A performance impact is a natural question to wonder about in such a layered/modular system. The paper spends a bit of time in the evaluation explaining and showing how layers and propagation between them add very little overheads. What is not clear is whether a less generic, more purpose-built solution could have been faster. This is a tough question to answer, as comparing different architectures is not trivial — sometimes it can be hard to tell whether the difference comes from design choices or implementation differences and nuances.
3) Read cost & Virtual Log. This part of the discussion goes back quite a bit to the first Delos paper. With a native Loglet, Delos assumes a quorum-based operation for Loglets, which may have less than ideal read performance. This is because NativeLoglet uses a sequencer to write, but requires on quorum read and waits for reads with the checkTail operation. So a client will read from the quorum, and assuming the Loglet is not sealed (i.e., closed for writes), the client must wait for its knowledge of the globalTail (i.e., globally committed slot) to catch up with the highest locally committed slot it observed earlier. This process is similar to a PQR read! Naturally, it may have higher read latency, which will largely depend on how fast the client’s knowledge of globally committed slot catches up. In the PQR paper, we also describe a few optimizations to cut down on latency, and I wonder if they can apply here.
Moreover, a client does not need to perform an expensive operation for all reads — if a client is reading something in the past known to exist, it can use a cheaper readNext API, practically allowing a local read from its collocates LogServer.
4) Engineering costs. This discussion stemmed from the performance discussion. While large companies care a lot about performance and efficiency (even a fraction of % of CPU usage means a lot of money!), the engineering costs matter a lot too. Not having to redo the same things for different products in different teams can translate into a lot of engineering savings! Not to mention this can allow engineers to focus on new features instead of re-writing the same things all over again. Another point is maintenance — cleaner and better-designed systems will likely be cheaper to maintain as well.
5) Non-control plane applications? The paper talks about using Delos in two control-plane applications. These often have some more specific and unique requirements, such as zero external dependencies, and stronger consistency. The paper also mentions other possible control plane use cases, so it does not appear like Delos is done here.
At the same time, we were wondering if/how/when Delos can be used outside of the control plane. For Facebook, there may not be too much need for strongly consistent replication for many of their user-facing apps. In fact, it seems like read-your-write consistency is enough for Facebook, so deploying Delos may not be needed. At the same time, user-facing apps can take on more dependencies and external dependencies, achieving some code reuse this way.
Another point made during the discussion is about making a more general and flexible replication framework that can support strongly-consistent cases and higher-throughput weaker consistency applications. We would not be surprised if Delos or its successors will one day support at least some stronger-consistency user-facing applications.