transactions
-
Reading Group. Chardonnay: Fast and General Datacenter Transactions for On-Disk Databases
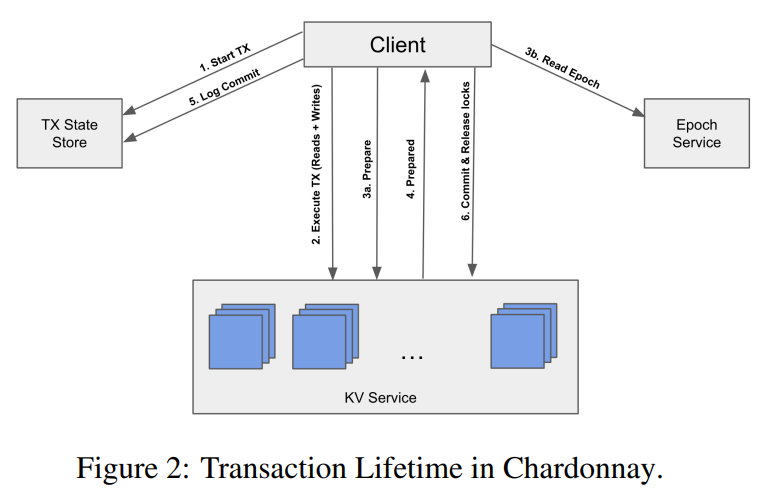
Last week, we looked at the “Chardonnay: Fast and General Datacenter Transactions for On-Disk Databases” OSDI’23 paper by Tamer Eldeeb, Xincheng Xie, Philip A. Bernstein, Asaf Cidon, Junfeng Yang. The paper presents a transactional database built on the assumption of having a very fast two-phase commit protocol. Coordination, like a two-phase commit (2PC), usually has…
-
Reading Group Paper. Take Out the TraChe: Maximizing (Tra)nsactional Ca(che) Hit Rate
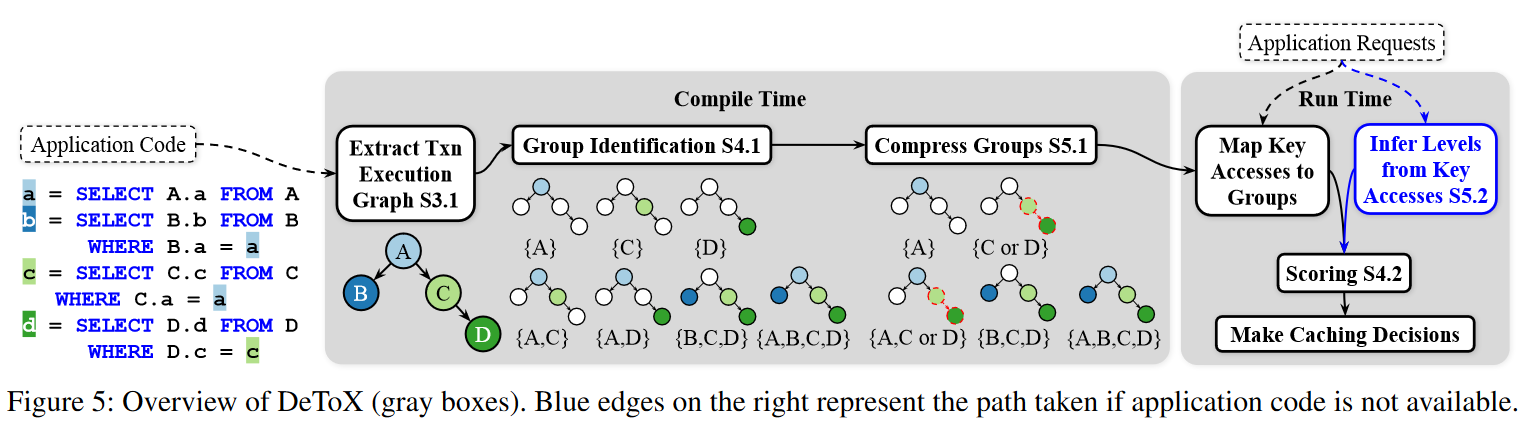
In this week’s reading group, we discussed the “Take Out the TraChe: Maximizing (Tra)nsactional Ca(che) Hit Rate” OSDI’23 paper by Audrey Cheng, David Chu, Terrance Li, Jason Chan, Natacha Crooks, Joseph M. Hellerstein, Ion Stoica, Xiangyao Yu. This paper argues against optimizing for object hit rate in caches for transactional databases. The main logic behind…
-
Reading Group. ByShard: Sharding in a Byzantine Environment
Our 93rd paper in the reading group was “ByShard: Sharding in a Byzantine Environment” by Jelle Hellings, Mohammad Sadoghi. This VLDB’21 paper talks about sharded byzantine systems and proposes an approach that can implement 18 different multi-shard transaction algorithms. More specifically, the paper discusses two-phase commit (2PC) and two-phase locking (2PL) in a byzantine environment.…
-
Reading Group. Basil: Breaking up BFT with ACID (transactions)
Our 89th paper in the reading group was “Basil: Breaking up BFT with ACID (transactions)” from SOSP’21 by Florian Suri-Payer, Matthew Burke, Zheng Wang, Yunhao Zhang, Lorenzo Alvisi, and Natacha Crooks. I will make this summary short. We had a quick and improvised presentation as well. Unfortunately, this time around, it was not recorded. The…
-
Reading Group Special Session: Fast General Purpose Transactions in Apache Cassandra
Modern distributed databases employ leader-based consensus protocols to achieve consistency, entailing certain trade-offs: typically either a scalability bottleneck or weak isolation. Leaderless protocols have been proposed to address these and other shortcomings of leader-based techniques, but these have not yet materialized into production systems. This paper outlines compromises entailed by existing leaderless protocols versus leader-based…
-
Reading Group. UniStore: A fault-tolerant marriage of causal and strong consistency
For the 80th paper in the reading group, we picked “UniStore: A fault-tolerant marriage of causal and strong consistency” by Manuel Bravo, Alexey Gotsman, Borja de Régil, and Hengfeng Wei. This ATC’21 paper adapts the Partial Order-Restrictions consistency (PoR) into a transactional model. UniStore uses PoR to reduce coordination efforts and execute as many transactions…
-
Reading Group. Prescient Data Partitioning and Migration for Deterministic Database Systems
In the 75th reading group session, we discussed the transaction locality and dynamic data partitioning through the eyes of a recent OSDI’21 paper – “Don’t Look Back, Look into the Future: Prescient Data Partitioning and Migration for Deterministic Database Systems.” This interesting paper solves the transaction locality problem in distributed, sharded deterministic databases. The deterministic…
-
Reading Group. Polyjuice: High-Performance Transactions via Learned Concurrency Control
Our 73rd reading group meeting continued with discussions on transaction execution systems. This time we looked at the “Polyjuice: High-Performance Transactions via Learned Concurrency Control” OSDI’21 paper by Jiachen Wang, Ding Ding, Huan Wang, Conrad Christensen, Zhaoguo Wang, Haibo Chen, and Jinyang Li. This paper explores single-server transaction execution. In particular, it looks at concurrency…
-
Reading Group. Meerkat: Multicore-Scalable Replicated Transactions Following the Zero-Coordination Principle
Our 72nd paper was on avoiding coordination as much as possible. We looked at the “Meerkat: Multicore-Scalable Replicated Transactions Following the Zero-Coordination Principle” EuroSys’20 paper by Adriana Szekeres, Michael Whittaker, Jialin Li, Naveen Kr. Sharma, Arvind Krishnamurthy, Dan R. K. Ports, Irene Zhang. As the name suggests, this paper discusses coordination-free distributed transaction execution. In…
-
Reading Group. FoundationDB: A Distributed Unbundled Transactional Key Value Store
Last week we discussed the “FoundationDB: A Distributed Unbundled Transactional Key Value Store” SIGMOD’21 paper. We had a rather detailed presentation by Moustafa Maher. FoundationDB is a transactional distributed key-value store meant to serve as the “foundation” or lower layer for more comprehensive solutions. FoundationDB supports point and ranged access to keys. This is a…
Search
Recent Posts
- Paper #196. The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling
- Paper #193. Databases in the Era of Memory-Centric Computing
- Paper #192. OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck
- Paper #191: Occam’s Razor for Distributed Protocols
- Spring 2025 Reading List (Papers ##191-200)
Categories
- One Page Summary (10)
- Other Thoughts (10)
- Paper Review and Summary (14)
- Pile of Eternal Rejections (2)
- Playing Around (14)
- Reading Group (103)
- RG Special Session (4)
- Teaching (2)