For the 80th paper in the reading group, we picked “UniStore: A fault-tolerant marriage of causal and strong consistency” by Manuel Bravo, Alexey Gotsman, Borja de Régil, and Hengfeng Wei. This ATC’21 paper adapts the Partial Order-Restrictions consistency (PoR) into a transactional model. UniStore uses PoR to reduce coordination efforts and execute as many transactions as possible under the causal consistency model while resorting to strong consistency in cases that require ordering concurrent conflicting transactions. The PoR consistency itself is an extension of RedBlue consistency that allows mixing eventually consistent and strongly consistent operations.
UniStore operates in a geo-replicated model, where each region/data center (I use region and data center interchangeably in this post) stores the entirety of the database. The regions are complete replicas of each other. Naturally, requiring strong consistency is expensive due to cross-region synchronization. Instead, UniStore allows the developers to choose running transactions as causally or strongly consistent. Causal consistency preserves the cause-and-effect notion between events — if some event e1 has resulted in event e2, then an observer seeing e2 must see the e1 as well. Naturally, if two events are concurrent, then they are not causally dependent. This independence gives us the freedom to apply these events (i.e., execute against the store) in any order. For instance, this approach provides good performance for events that may touch disjoint data concurrently. However, if these two events are concurrent and operate on the same data, then the events either need to be commutative or be partly ordered. UniStore does both of these — it implements CRDTs to ensure commutativity, but it also allows to declare a transaction as strongly consistent for cases that require ordering. As such, strong consistency becomes handy when the commutativity alone is not sufficient for the safety of the application. For example, when a transaction does a compare-and-set operation, the system must ensure that all replicas execute these compare-and-set operations in the same order.
So, in short, causal consistency is great when an application can execute complex logic in causal steps — event e1 completes, then observing the results of e1 can cause some other change e2, and so on. Strong consistency comes in handy when step-by-step non-atomic logic is not an option, and there is a need to ensure the execution order of conflicting concurrent operations. In both cases, the systems need to keep track of dependencies. For causal transactions, the dependencies are other transactions that have already finished and were made visible. For strongly consistent transactions, the dependencies also include other concurrent, conflicting, strongly consistent transactions.
So, how does UniStore work? I actually do not want to get into the details too deep. It is a complicated paper (maybe unnecessarily complicated!), and I am not that smart to understand all of it. But I will try to get the gist of it.
The system more-or-less runs a two-phase commit protocol with optimistic concurrency control. Causal transactions commit in the local data center before returning to the client. However, these causal transactions are not visible to other transactions (and hence other clients/users) just yet. Remember, this causal transaction has not been replicated to other data centers yet, and a single region failure can cause some problems. In fact, if a strongly consistent transaction somehow takes such a non-fully replicated causal transaction as a dependency, then the whole system can get stuck if the dependent causal transaction gets lost due to some minority regions failing.
UniStore avoids these issues by making sure the causal transactions are replicated to enough regions before these causal transactions are made visible. This replication happens asynchronously in the background, sparing the cost of synchronization for non-strongly consistent transactions (that is, of course, if clients/users are ok with a remote possibility of losing transactions they thought were committed).
Strongly consistent transactions are a different beast. They still optimistically run in their local data centers but no longer commit in one region to ensure the ordering between other strongly consistent transactions. UniStore uses a two-phase commit here as well, but this time the commitment protocol goes across all healthy regions. First, the coordinator waits for enough data centers to be sufficiently up-to-date. This waiting is crucial for liveness; it ensures that no dependent transaction may get forgotten in the case of data center outages. After the waiting, the actual two-phase commit begins, with all (alive?) regions certifying the transaction.
To implement this waiting and only expose the durable and geo-replicated state to transactions, UniStore has a complicated system of version tracking using a bunch of vector clocks and version vectors. Each of these vectors has a time component for each data center and an additional “strong” counter for keeping track of strongly consistent transactions. Each transaction has a couple of important version vectors.
The snapshot vector snapVec describes the consistent snapshot against which the transaction runs. The commit vector commitVec tells the commit version of a transaction used for ordering.
Each replica keeps two different version vectors representing the version of the most recent transaction known to itself and its data center. Since the system relies on FIFO order of communication and message handling, knowing the version of the most recent transaction implies the knowledge of all lower-versioned transactions as well. This information is then exchanged between data centers to compute yet another version vector to represent the latest transaction replicated to at least some majority of data centers. This, again, implies that all lower-versioned transactions have been replicated as well. This last version vector allows strongly consistent transactions to wait for their dependencies to become globally durable to ensure liveness.
So here is where I lose understanding of the paper, so read on with a pinch of salt, as my skepticism may be completely unwarranted. It makes sense to me to use version vectors to keep track of progress and order causal transactions. Each region computes the region’s known progress, exchanges it with other regions, and calculates the global “transaction frontier” — all transactions that have been replicated to a sufficient number of data centers. This exchange of known progress between regions happens asynchronously. I am not entirely sure how these progress vectors help with ordering the conflicting transactions. Somehow the “strong” counter should help, but this counter seems to be based on the regions’ knowledge of progress and not the global one. I suspect that these vectors help identify the concurrent conflicting transactions. The progress known in the data center ends up in a snapVec and represents the snapshot on which the transaction operates. The strongly consistent transactions use a certification procedure (i.e., a two-phase commit) to decide whether to abort or commit. The paper mentions that the certification process assigns the commitVec, which actually prescribes the order. At this point, I hope that conflicting transactions are caught in this Paxos-based transaction certification procedure and ordered there or at least aborted as needed. Also worth mentioning that the extended technical report may have more details that I was lazy to follow through.
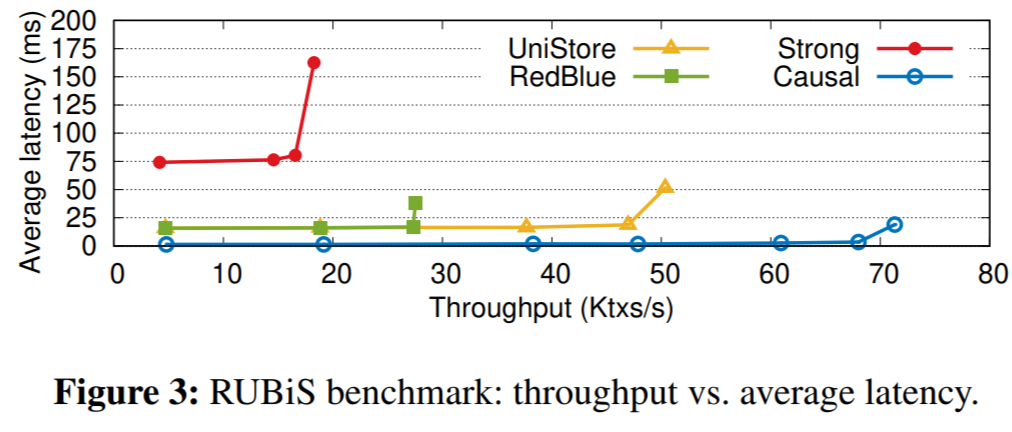
Now a few words about the evaluation. The authors focus on comparing UniStore against both casual and strongly consistent data stores. Naturally, it sits somewhere in the middle of these two extremes. My bigger concern with their implementation is how well it scales with the number of partitions and number of data centers. The paper provides both of these evaluations, but not nearly to the convincing scale. They go up to 5 data centers and up to 64 partitions. See, with all the vectors and tables of vectors whose size depends on the number of regions, UniStore may have some issues growing to “cloud-scale,” so it would be nice to see how it does at 10 data centers or even 20. Cloud vendors have many regions and even more data centers; Azure, for example, has 60+ regions with multiple availability zones.
Our groups persentation by Rohan Puri is on YouTube:
Discussion
1) Novelty. So the paper works with a rather interesting consistency model that combines weaker consistency with strong on a declarative per-operation basis. This model, of course, is not new, and the paper describes and even compares against some predecessors. So we had the question about the novelty of UniStore since it is not the first one to do this kind of consistency mix-and-match. It appears that the transactional nature of UniStore is what separates it from other such solutions. In fact, the bulk of the paper talks about the transactions and ensuring liveness in the face of data center outages, so this is nice. Many real-world databases are transactional, and having a system like this is a step closer to a practical solution.
2) Liveness in the presence of data center failures. Quite a lot of the paper’s motivation goes around the inability to simply run OCC + 2PC in the PoR consistency model and maintain liveness. One problem occurs when a causal transaction takes a dependency on another transaction that did not make it to the majority of regions. If such a transaction is lost, it may stall the system. Of course, any region that takes a dependency on some transaction must see it first. Anyway, it is hard to see the novelty in “transaction forwarding” when pretty much any system recovers the partly replicated data by “forwarding” it from the nodes that have it.
However, the bigger motivational issue is with strongly consistent transactions. See, the authors say that the system may lose liveness when a strongly consistent transaction commits with a dependency on a causal one that has not been sufficiently replicated, and that causal transaction gets lost in a void due to a region failure. However, to me, this seems paradoxical — how can all (healthy) regions accept a transaction without having all the dependencies first? It seems like a proper implementation of the commit protocol will abort when some parties cannot process the transaction due to the lack of dependencies. Anyway, this whole liveness thing is not real and appears to be just a way to make the problem look more serious.
That said, I do think there is a major problem to be solved. Doing this more proper commit protocol may hurt the performance by either having a higher abort rate or replicating dependencies along with the strongly consistent transaction. We’d like to see how much better UniStore is compared to the simpler 2PC-based solution that actually aborts transactions when it cannot run them.
3) Evaluation. The evaluation largely compares against itself, but in different modes — causal and strong. This is ok, but how about some other competition? Take a handful of other transactional approaches and see what happens? The current evaluation tells us that the PoR model provides better performance than strong and worse than causal consistency. But this was known before. Now we also know that this same behavior translates to a transactional world. But we do not know how the cost of the protocol fares against other transactional systems that do not have PoR and are not based on UniStore with features disabled.
Also interesting to see is how expressive the transactional PoR consistency model is. For example, let’s take MongoDB. It can be strongly consistent within a partition and causal across the partitions (and within the partition, users can manipulate the read and write consistency on a per-operation basis). What kind of applications can we have with Mongo’s simpler model? And what kind of apps need UniStore’s model with on-demand strong consistency across the partitions?
4) Complicated solution??? I have already mentioned this in the summary, but UniStore is complicated and relies on many moving parts. The paper completely omits the within-datacenter replication for “simplicity,” but it does not really make the paper simple. We have vectors that track progress, order, and snapshots, and then we have tables of vectors, and all these multiple kinds of vectors are exchanged back-and-forth to compute more vectors only to find out when it is ok to make some transactions visible or unblock some strongly consistent transactions. How come other systems (MongoDB again?) implement causal consistency with just one number for versioning (HLC) and still allow to specify stronger guarantees when needed? Yeah, they may not implement the PoR consistency model but it just seems too complicated. As a side question… what happens in Mongo when we start changing consistency between causal and strong on a per-request basis?