Reading Group
-
Fall 2025 Reading List (##201-210)

Here is a list for the Fall 2025 semester. Please join the reading group here: https://discord.gg/VS7J4PAU58. We meet on Thursdays. The schedule is also available on our calendar.
-
Paper #196. The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling

The last paper we covered in the Distributed Systems Reading group discussed CPUs, data centers, scheduling, and carbon emissions—we read “The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling.” Below is my improvised presentation of this paper for the reading group. This paper was an educational read for me, as I learned…
-
Paper #193. Databases in the Era of Memory-Centric Computing
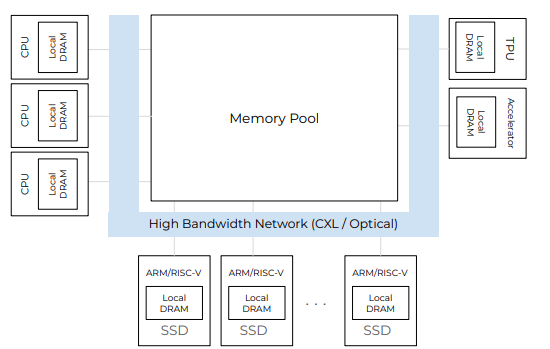
Last week, we read “Databases in the Era of Memory-Centric Computing” CIDR’25 paper in our reading group. This paper argues that the rising cost of main memory and lagging improvement in memory bandwidth do not bode well for traditional computing architectures centered around computing devices (i.e., CPUs). As CPUs get more cores, the memory bandwidth…
-
Paper #192. OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck
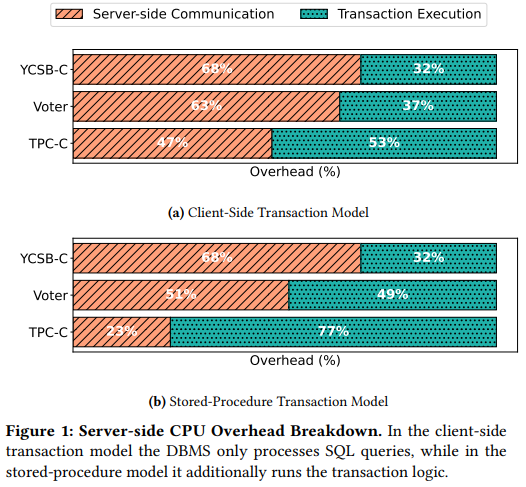
Last week we read “OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck” CIDR’25 paper by Xinjing Zhou, Viktor Leis, Xiangyao Yu, Michael Stonebraker. This paper revisits the original “OLTP Through the Looking Glass, and What We Found There” paper and examines the bottlenecks in modern OLTP databases. The new paper…
-
Paper #191: Occam’s Razor for Distributed Protocols

We have been doing a Zoom distributed systems paper reading group for 5 years and have covered around 190 papers. This semester, we should reach the milestone of 200 papers. Over the years, my commitment to the group has varied — at some point, I was writing paper reviews, and more recently, I’ve had less…
-
Spring 2025 Reading List (Papers ##191-200)

This is a list of papers for the DistSys reading group Spring 2025 term. The schedule is also available on our Google Calendar.
-
Fall 2024 Reading Group Papers (Papers ##181-190)
Without further ado, here is the list:
-
Summer 2024 Reading Group Papers (Papers ##171-180)

This is a list of papers for the DistSys reading group summer term. The schedule is also available on our Google Calendar.
-
Spring 2024 Reading Group Papers (##161-170)
Below is the reading group schedule for the upcoming winter term. The schedule is also available in our Google Calendar. Are you interested in joining the reading group? It is simple, join our Slack to get all the reading group updates and invites.
-
Reading Group #153. Deep Note: Can Acoustic Interference Damage the Availability of Hard Disk Storage in Underwater Data Centers?

For the 153rd reading group paper, we read something very different this time: “Deep Note: Can Acoustic Interference Damage the Availability of Hard Disk Storage in Underwater Data Centers?” This HotStorage short paper explores the possibility of using soundwaves to attack underwater data centers. In particular, the paper shows how magnetic disks can be disrupted…
Search
Recent Posts
- Murat and Aleksey Read Papers: “Self-Defining Systems”
- Murat and Aleksey Read Papers: “Cloudspecs: Cloud Hardware Evolution Through the Looking Glass”
- Murat and Aleksey Read Papers: “Rethinking the Cost of Distributed Caches for Datacenter Services”
- On Metastable Failures and Interactions Between Systems
- Murat and Aleksey Read Papers: “Barbarians at the Gate: How AI is Upending Systems Research”
Categories
- One Page Summary (12)
- Other Thoughts (15)
- Paper Review and Summary (16)
- Pile of Eternal Rejections (2)
- Playing Around (14)
- Reading Group (104)
- RG Special Session (4)
- Teaching (2)