Last week, we looked at the “Chardonnay: Fast and General Datacenter Transactions for On-Disk Databases” OSDI’23 paper by Tamer Eldeeb, Xincheng Xie, Philip A. Bernstein, Asaf Cidon, Junfeng Yang. The paper presents a transactional database built on the assumption of having a very fast two-phase commit protocol.
Coordination, like a two-phase commit (2PC), usually has some non-negligible cost as machines/participants agree to do (or not do!) something together. In the case of a 2PC algorithm, a coordinator must ensure that all participants agree to proceed with a transaction or abort the transaction otherwise. This is a chatty protocol, as the transaction first needs to be delivered to participants; the participants then check if the transaction can be accepted and reply with their status to the coordinator, who then needs to decide to commit or abort and communicate this decision back to the participants. To add more problems, making the whole thing fault-tolerant requires making all participants infallible through replication with Multi-Paxos or Raft or something similar, which adds more delays. Many 2PC implementations also make the coordinators infallible too.
This paper poses a question: does the design of transactional databases need to change if 2PC is fast? Unfortunately, in my opinion, instead of exploring the design tradeoffs more in-depth, the paper presents a system that operates in this new environment with fast 2PC without really exploring it much. But anyway, the authors assert that fast 2PC is possible, mainly with the help of kernel-bypassed networking stacks (eRCPs in this work) within the data center and fast NVME SSD storage devices to back all the transactional logs. According to the paper, the fast 2PC shifts the bottleneck from coordination to slow storage (also SSD in the paper!?).
Next, the paper shows the system that solves the “slow storage” problem. The overall approach remotely reminds me of Compartmentalized Paxos — every component exits separately from others. The system, Chardonnay, consists of Multi-Paxos replicated KV-storage, Multi-Paxos replicated Transaction-state store, Multi-Paxos replicated Epoch service, and clients who act as 2PC coordinators.
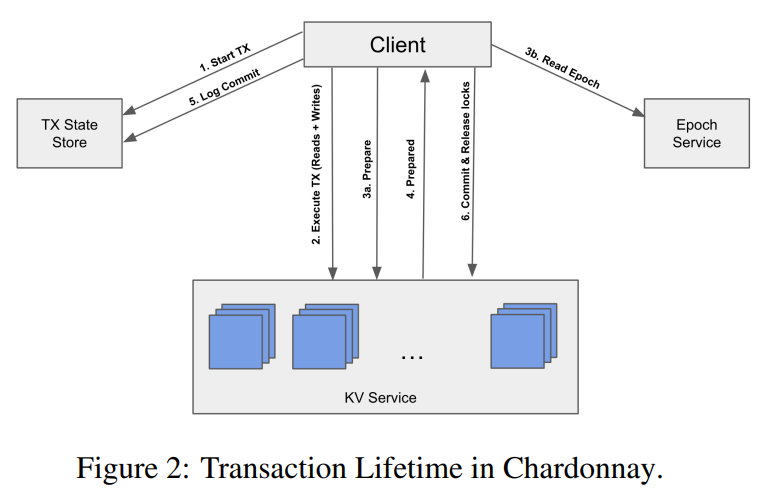
The KV storage is self-explanatory; it is a sharded store that partitions keyspace across multiple Multi-Paxos boxes. The store is multi-versioned, and in addition to storing data, it also manages locks to keys/objects. The transaction-state store is a component that keeps a state machine for each transaction. The state machine encodes the transaction’s linear lifecycle — started -> committed/aborted -> done. The store keeps a separate state machine for each transaction, and client/2PC-coordinator updates the state machine as it progresses through the transaction. The transaction store provides the fault tolerance for situations when the client/2PC coordinator crashes mid-transaction.
The epoch service is where we start to get to the solution of the “slow storage” problem, although indirectly. The epoch service enables the snapshot read mechanism for read-only transactions/operations. In Chardonnay, the only valid read snapshots occur at the epoch boundaries. The epoch service counts new epochs every 10 ms, creating predicably timed and spaced read-points. These epochs provide order to the read-only transactions, but all other transactions largely ignore epochs; they use 2PC with two-phase locking (2PL) and can execute across epoch boundaries. Anyway, a read-transaction queries the epoch service for current epoch e, waits for the epoch to advance to e+1, and queries the state from the multi-versioned KV store that captures all transactions finished by the end of the epoch e. I will leave the details out of this summary, but in short, each object has a version associated with it. The version captures the epoch and the number of changes to the object within that epoch. Querying at the end-of-epoch boundary then finds the latest version of the key in that epoch. There is also an issue with interacting with update transactions — an update may hold a lock for a key across the epoch boundaries (technically, a regular transaction can span only some limited range epochs to avoid stalling forever in case a KV store leader with the locks fails). In this case, the read simply waits for the lock to release before reading.
Anyway, the epoch part of the system supports the snapshot reads and pretty much nothing else. Why couldn’t Chardonnay use something like HLC for this? CockroachDB and YugabyteDB use that for snapshot reads! I think the answer is strict serializability that Chardonnay wants to optionally support, and HLC-based systems cannot do it. Okay, so we have snapshot reads. How do they solve the “slow SSD” problem?
As it turns out, Chardonnay uses these snapshot reads to do a dry-run transaction before the real one. This dry run can figure out the approximate read set and prefetch the objects in the read set from SSD to RAM. The prefetching works by knowing the transaction code/logic ahead of time — users submit the entire transaction function/logic and Chardonnay runs the transaction in the dry-run mode without acquiring any locks to compute and prefetch the read set. The normal transaction execution begins after the dry run: “Chardonnay transparently uses the client’s code to first execute the query in a lock-free, dry run mode to load the read set to memory, then executes normally with 2PL.”
How is running a dry-run sequentially followed by the normal execution faster than just running the normal execution? If the dry-run is perfect at prefetching, then we pay the SSD IO cost associated with reading in the dry-run. But since the dry-run and normal execution of a transaction seem to happen sequentially, the cost of IO and its latency remains on the overall common path of a transaction, and this common path now also has extra work to do!
It appears that the benefit of a dry-run is not the end-to-end latency observed by clients or the optimization of the resources needed for a transaction. Instead, the dry-run and the prefetching reduce the lock contention during the normal execution! This is because the normal run, which, unlike lock-less dry-run, uses 2PL. With most objects/keys in the read set already prefetched to RAM, the normal execution is faster, reducing the time each key spends under lock.
Another Chardonnay optimization that is supposed to improve the performance (here, by performance, the authors again mean reduced contention, which leads to higher throughput) is a deadlock avoidance mechanism. The approach is based on knowing the read and write sets of all transactions and, predictably, also relies on dry-runs, which, in turn, rely on snapshot reads.
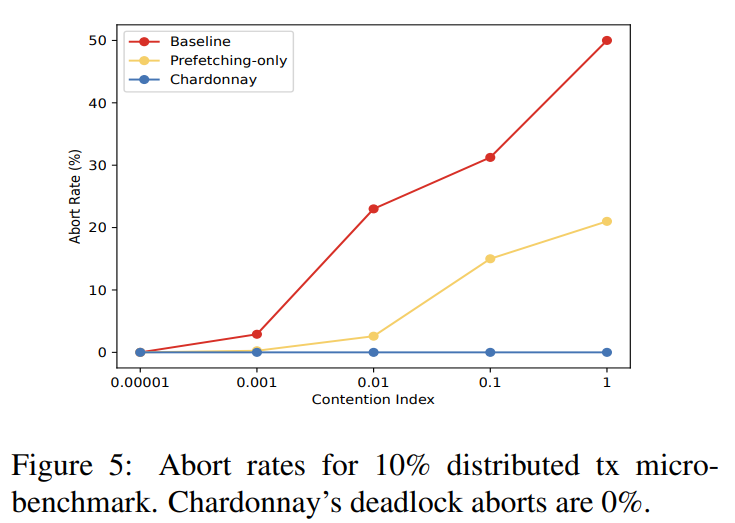
The evaluation compares Chardonnay to itself with stuff turned off or degraded. I want to see a better evaluation than what the paper has! I want to see more insights and details on how all the design decisions impacted latency, throughput, and contention. I want to see a comparison with other systems! However, in my opinion, this figure is the main result of the paper that shows what dry-runs with prefetching and optimized lock acquisition schedule can do to the abort rate. Naturally, having fewer aborts means less wasted resources and higher throughput.
Discussion
1) Fast 2PC. Having fast 2PC (by some definition of fast) is a big part of this paper. However, this is hardly the point of the paper — that supposed fast 2PC is just 2PC implemented with state-of-the-art tech and a bit of cheating (the “fast NVME SSD” is mocked in RAM in the paper).
2) Slow SSDs. According to the paper, having Fast 2PC, which relies on fast SSDs, makes slow SSDs the bottleneck in transactional systems. Of course, this begs the question: if we have a fast SSD, why do we use slow ones for storage? Is it a cost issue?
3) Is Dry-run fast enough? While snapshot reads do not acquire their own locks, the reads may still block when encountering locked objects. This can prolong the dry-run phase and increase the chance other prefetched objects change in the meantime.
4) Dry-runs. Chardonnay is not the first paper/system to suggest dry runs for computing read and write sets and using that to avoid deadlocks. The whole direction of deterministic databases does that and avoids all deadlocks by ordering everything! The problem with dry-runs in deterministic databases is that if read or write set changes between the dry run and normal execution, the normal run needs to abort. Naturally, deterministic databases try to avoid dry-runs by ideally having transactions with known read and write sets, since dry-runs slow the transactions down and consume resources. This means, that the ideal transaction for deterministic databases is a one-shot transaction. Chardonnay, while forgoing some generality of interactive transactions, allows transactions without the known read and write sets and allows dry-runs to have incorrect read and write sets, since the normal run has all the safety mechanisms.
5) Snapshot reads. Why not use HLC or something similar to get snapshot reads without the need for epochs and waiting for the epoch to end? CockroachDB and Yugabyte DB do that! The authors talk about linearizable snapshot reads, but this just blows my mind. Did they mean strictly serializable instead of linearizable, since we are talking about multi-object, multi-operation transactions here? But regardless of the terminology, these “linearizable” snapshot read-only transactions are also slower since the system needs to wait out some epoch changes, contributing to point 4 above.
6) Speculative dry-run. Since the dry-run is a best-effort attempt to prefetch data from slow storage, can we make this step a bit more speculative? For instance, if a dry-run and a normal run proceed in parallel, but the dry-run is much faster (even if it is less correct), then it can prefetch some data for a slower normal run just in time.
I will stop my comments here…