
In this week’s reading group, we discussed the “Take Out the TraChe: Maximizing (Tra)nsactional Ca(che) Hit Rate” OSDI’23 paper by Audrey Cheng, David Chu, Terrance Li, Jason Chan, Natacha Crooks, Joseph M. Hellerstein, Ion Stoica, Xiangyao Yu. This paper argues against optimizing for object hit rate in caches for transactional databases. The main logic behind this is that missing even a single object needed for a transaction will require a trip to the database and incur the associated costs. Instead, the paper suggests designing caches to leverage the structure/composition of transactions.
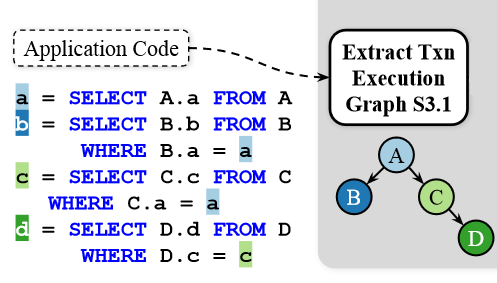
Let me use an example from the paper to explain this better. Let’s say we have a transaction, shown in the image here, that queries 4 different tables: A, B, C, and D, such that querying tables B and C depends on the results of reading table A, and reading D requires to first get the data from C. This read-only transaction has data dependencies, and the authors exploit such dependencies to improve transaction latency. See, this example has two dependency chains (A -> B and A -> C -> D). The A -> C -> D is the longest chain with three queries in a sequence. A transaction-optimized cache can then focus on reducing the number of such chained operations that need to hit the database. For instance, caching table A reduces the number of queries answered by the database from 3 down to 2 (using cache for A, then reading B and C concurrently, and then reading table D). Similarly, caching just table C also reduces the number of database steps in the longest chain (reading A, using cached C, and reading B and D concurrently). Every time we reduce the number of database steps in the transaction chain with the most such steps, we improve transaction latency further by cutting out more database interactions and associated networking costs. As such, caching both A and C, for example, can be even better than just A or C, as now there is only one database step left in both transaction chains. A further improvement now needs to consider caching tables that can help cut database access from both chains.
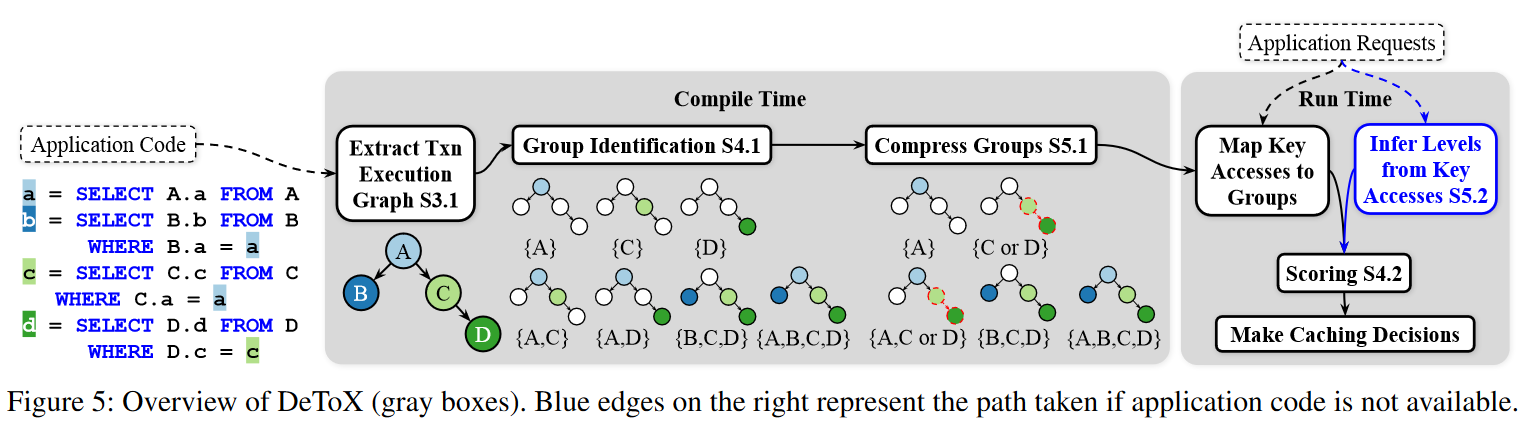
DeToX, the system proposed in the paper, tries to achieve the above strategy. It works by knowing what types of transactions an application may run and using it to enumerate all possible groups of tables to cache for each transaction type. These groups are then scored during the runtime to decide which groups of tables are more valuable to the cache. In short, the idea is to give higher scores to groups with smaller yet frequently used tables. Finally, caching entire tables may be infeasible, so DeToX also scores individual keys/objects to decide which ones to cache. Similarly, the idea here is to keep as many high-impact keys/objects in the cache as possible, where impact is measured by the object’s “hotness” and whether the object benefits from important/frequent transactions or lots of types of transactions. The paper has a more precise description and formulas used for scoring than my super high-level summary.
DeToX runs as a shim layer between the PostgreSQL and the clients. This shim layer sits on a separate (and equally large!) machine as the database itself. In the eval, both ran on AWS c5a.4xlarge (16vCPU, 32GB RAM) VMs. Clients do not interact with the database directly and use the shim layer instead. The shim keeps the cache coherence with the underlying PostgreSQL with two-phase locking. The actual cache is backed by Redis, running on an even larger VM (in the eval, it was c5a.16xlarge with 64 vCPUs and 128 GB RAM).
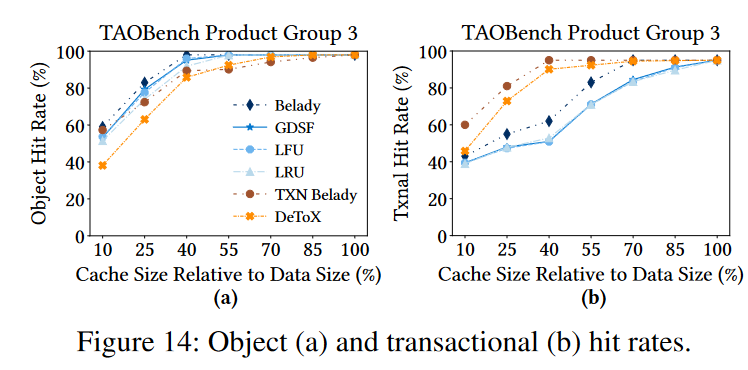
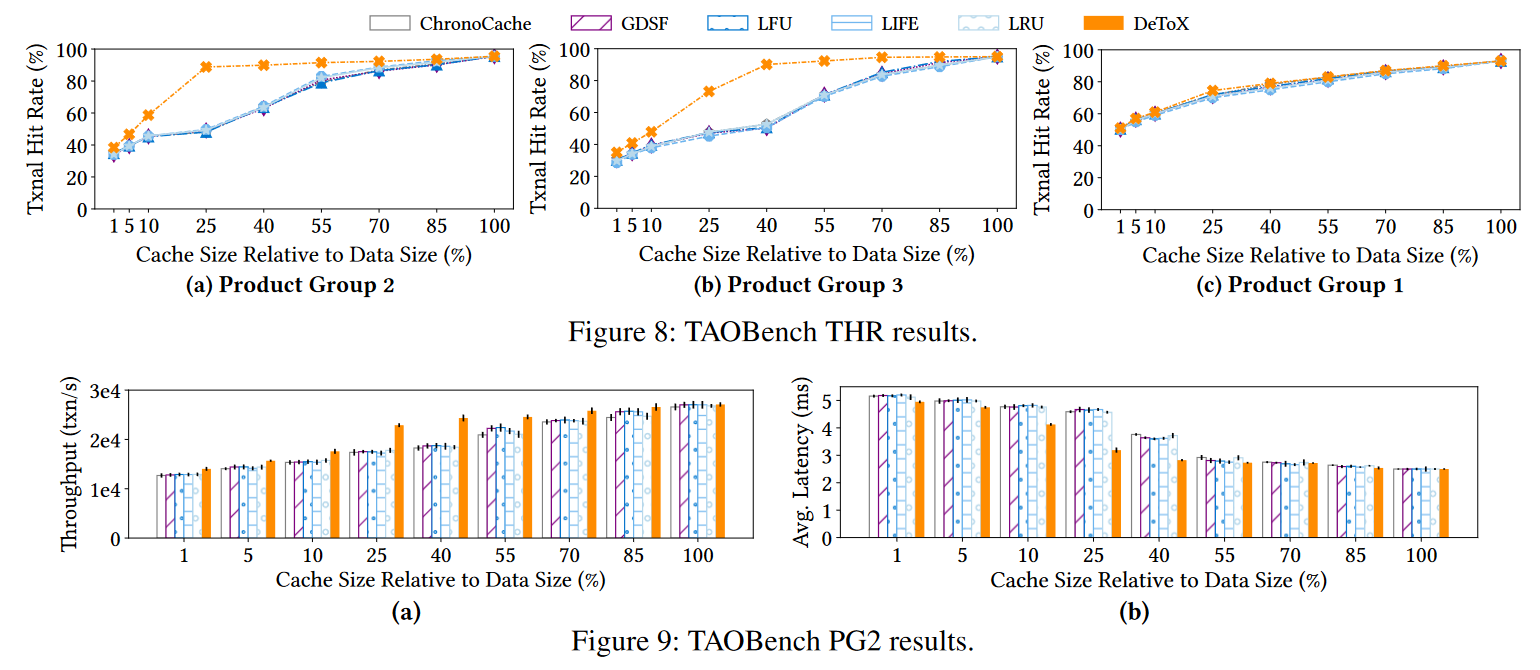
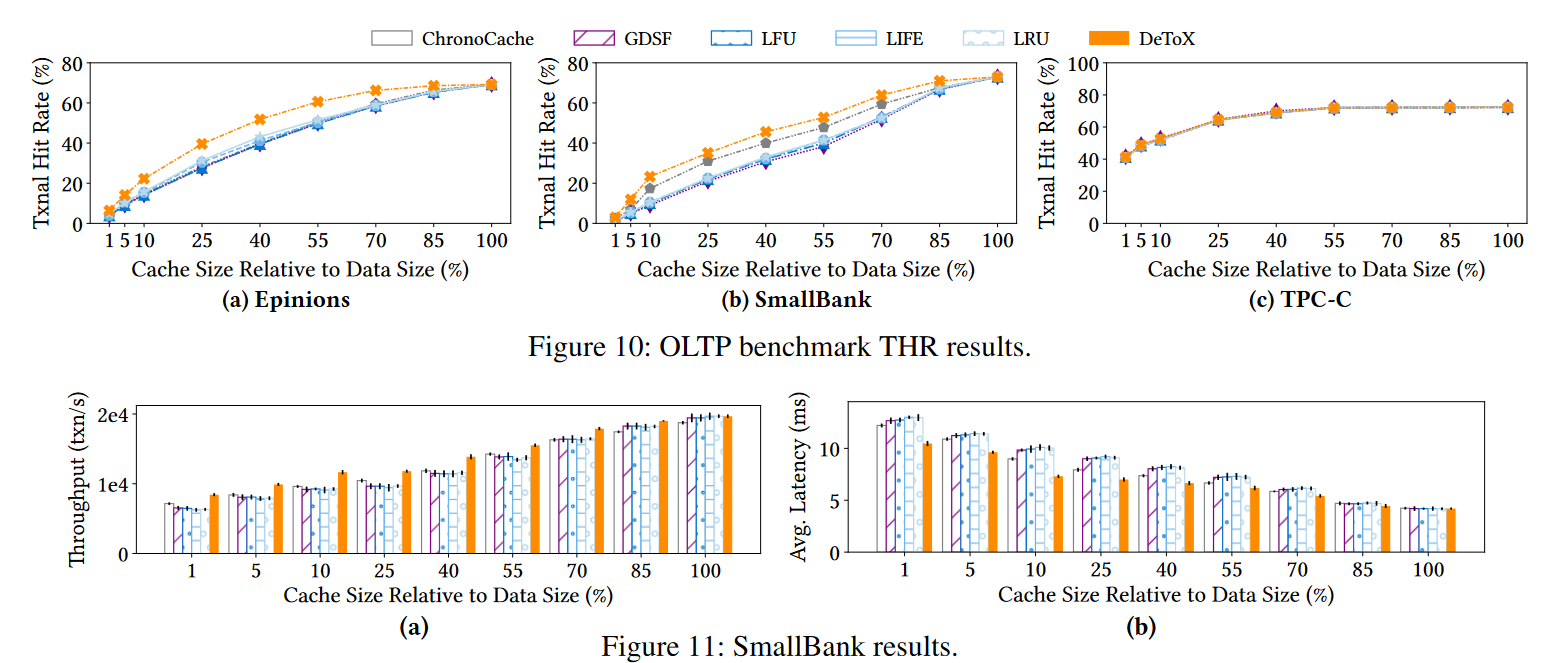
Anyway, this approach and setup seem to provide a decent improvement in the transaction hit rate over other state-of-the-art caching strategies. The paper defines a transaction hit rate as using a cache to successfully reduce the number of databases accessed in the transaction’s longest dependency chain. The object hit rate, however, is reduced since this is not a priority for the scoring system.
Discussion
We had a long discussion of the paper, and for the sake of space and my time, I will summarize only a handful of points.
1) Object hit rate vs. Transaction hit rate. The objective of the paper is to minimize the transaction hit rate (i.e., caching at least some of the transaction’s sequential steps in their entirety to remove these steps from ever touching the database). This seems to help improve the latency. However, a lower object hit rate may result in databases having to do more work, as now the database needs to serve more objects. It may be the case that for use cases that require higher throughput, object hit rate may still be more important. For what is worth, the paper reports throughput improvements despite the lower object hit rate.
2) Use cases for DeTox. Stemming from the point above, the use case we see for DeToX is latency-driven. Some caches only exist for reducing latency, and regardless of cache hit or miss, they exercise the underlying storage (see DynamoDB ATC’22 paper) for reliability reasons. It seems like a DeToX may be a viable solution in this type of cache usage for transactional workloads.
3) Latency Improvements. The DeToX caching approach is supposed to improve latency by cutting out entire transactional steps from reaching the database. The system prefers to cache objects from smaller yet frequently utilized tables. These smaller tables, due to their size, may also be the most efficient to answer using the databases and not the cache. As such, the latency improvements may not be proportional to the number of transactional steps cached and “cut out” if the remaining steps require more complex queries over larger tables that just take longer to be served by the database.
4) Cost of scoring. For large enough applications with many transaction types, there can be a substantial number of groups that need to be scored during the runtime as system access patterns start to emerge. This process can be quite costly (and the paper admits that), so we were wondering whether there are ways to mitigate some of that cost. The paper already proposes a few improvements.