reliability
-
Reading Group. Method Overloading the Circuit
In the 126th reading group meeting, we continued talking about the reliability of large distributed systems. This time, we read the “Method Overloading the Circuit” SoCC’22 paper by Christopher Meiklejohn, Lydia Stark, Cesare Celozzi, Matt Ranney, and Heather Miller. This paper does an excellent job summarizing a concept of a circuit breaker in microservice applications.…
-
Reading Group. How to fight production incidents?: an empirical study on a large-scale cloud service
In the 125th reading group meeting, we looked at the reliability of cloud services. In particular, we read the “How to fight production incidents?: an empirical study on a large-scale cloud service” SoCC’22 paper by Supriyo Ghosh, Manish Shetty, Chetan Bansal, and Suman Nath. This paper looks at 152 severe production incidents in the Microsoft…
-
Reading Group. Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service
In the 120th DistSys meeting, we talked about “Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service” ATC’22 paper by Mostafa Elhemali, Niall Gallagher, Nicholas Gordon, Joseph Idziorek, Richard Krog, Colin Lazier, Erben Mo, Akhilesh Mritunjai, Somu Perianayagam, Tim Rath, Swami Sivasubramanian, James Christopher Sorenson III, Sroaj Sosothikul, Doug Terry, Akshat Vig.…
-
Metastable Failures in the Wild
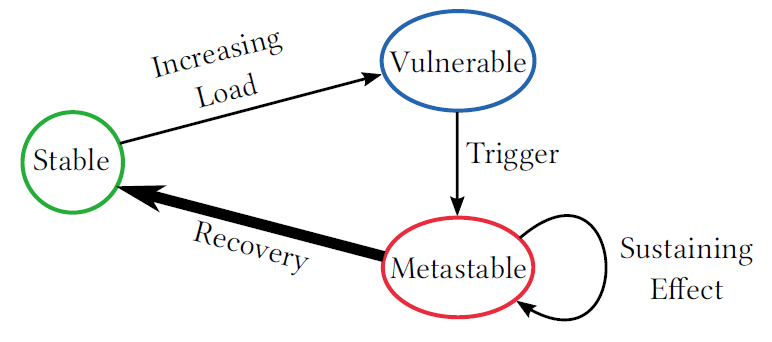
Metastable failures in distributed systems are failures that “feed” and strengthen their own “failed” condition. The main characteristic of a metastable failure is a positive feedback loop that keeps the system in a degraded/failed state. These failures are hard to spot, as they always start with some other distraction — some trigger event that nudges…
-
Reading Group. Cores that don’t count
Our 66th paper was a recent HotOS piece about faulty CPUs: “Cores that don’t count.” This paper from Google describes a decently common (at Google datacenter scale) issue with CPUs that may miscompute or silently fail under some conditions. This is a big deal, as we expect CPUs to be deterministic and always provide correct…
-
Reading Group. Evolution of Development Priorities in Key-value Stores Serving Large-scale Applications: The RocksDB Experience
On Wednesday, we had our 26th reading group meeting, discussing RocksDB with a help of a recent experience paper: “Evolution of Development Priorities in Key-value Stores Serving Large-scale Applications: The RocksDB Experience.” Single-server key-value storage systems are crucial for so many distributed systems and databases. For distributed folks like myself, these often remain black-boxes that…
-
Metastable Failures in Distributed Systems
Metastability is a stable state of a dynamical system other than the system’s state of least energy. – Wikipedia Distributed systems often fail spectacularly and unpredictably. They are a cause for a headache and sleepless on-call nights for way too many engineers. And this is despite lots of efforts to understand the failures, and all…
Search
Recent Posts
- Paper #196. The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling
- Paper #193. Databases in the Era of Memory-Centric Computing
- Paper #192. OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck
- Paper #191: Occam’s Razor for Distributed Protocols
- Spring 2025 Reading List (Papers ##191-200)
Categories
- One Page Summary (10)
- Other Thoughts (10)
- Paper Review and Summary (14)
- Pile of Eternal Rejections (2)
- Playing Around (14)
- Reading Group (103)
- RG Special Session (4)
- Teaching (2)