fault-tolerance
-
Reading Group Paper: Hyrax: Fail-in-Place Server Operation in Cloud Platforms
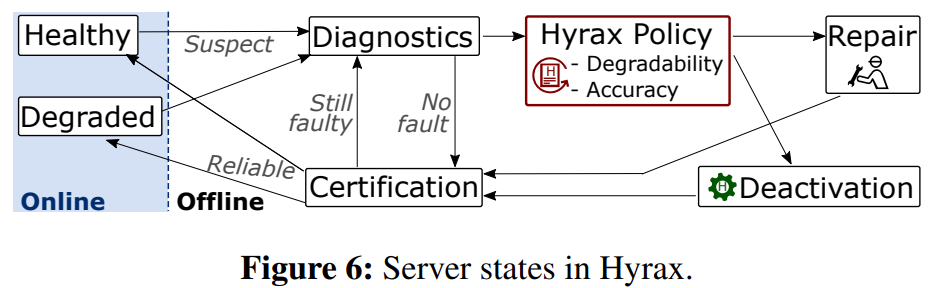
In the 142nd reading group meeting, we discussed “Hyrax: Fail-in-Place Server Operation in Cloud Platforms” OSDI’23 paper. Hyrax allows servers with certain types of hardware failures to return to service after some software-only automated mitigation steps. Traditionally, when a server malfunctions, the VMs are migrated off of it, then the server gets shut down and…
-
Reading Group Special Session: Scalability and Fault Tolerance in YDB
YDB is an open-source Distributed SQL Database. YDB is used as an OLTP Database for mission-critical user-facing applications. It provides strong consistency and serializable transaction isolation for the end user. One of the main characteristics of YDB is scalability to very large clusters together with multitenancy, i.e. ability to provide an isolated user environment for…
-
Reading Group. Solar Superstorms: Planning for an Internet Apocalypse
Our 96th reading group paper was very different from the topics we usually discuss. We talked about the “Solar Superstorms: Planning for an Internet Apocalypse” SIGCOMM’21 paper by Sangeetha Abdu Jyothi. Now (May 2022), we are slowly approaching the peak of solar cycle 25 (still due in a few years?) as the number of observable…
-
Reading Group. In Reference to RPC: It’s Time to Add Distributed Memory
Our 70th meeting covered the “In Reference to RPC: It’s Time to Add Distributed Memory” paper by Stephanie Wang, Benjamin Hindman, and Ion Stoica. This paper proposes some improvements to remote procedure call (RPC) frameworks. In current RPC implementations, the frameworks pass parameters to function by value. The same happens to the function return values.…
-
Metastable Failures in Distributed Systems
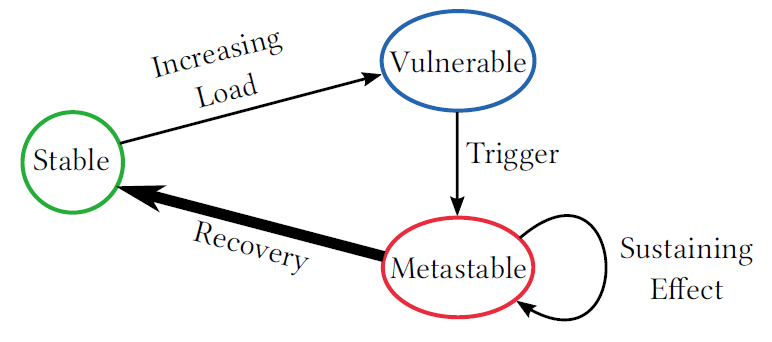
Metastability is a stable state of a dynamical system other than the system’s state of least energy. – Wikipedia Distributed systems often fail spectacularly and unpredictably. They are a cause for a headache and sleepless on-call nights for way too many engineers. And this is despite lots of efforts to understand the failures, and all…
-
Reading Group. Protocol-Aware Recovery for Consensus-Based Storage
Our last reading group meeting was about storage faults in state machine replications. We looked at the “Protocol-Aware Recovery for Consensus-Based Storage” paper from FAST’18. The paper explores an interesting omission in most of the state machine replication (SMR) protocols. These protocols, such as (multi)-Paxos and Raft, are specified with the assumption of having a…
-
Reading Group. Toward a Generic Fault Tolerance Technique for Partial Network Partitioning
Short Summary We have resumed the distributed systems reading group after a short holiday break. Yesterday we discussed the “Toward a Generic Fault Tolerance Technique for Partial Network Partitioning” paper from OSDI 2020. The paper studies a particular type of network partitioning – partial network partitioning. Normally, we expect that every node can reach every…
-
Reading Group. RMWPaxos: Fault-Tolerant In-Place Consensus Sequences
Quick Summary In the last reading group discussion, we talked about RMWPaxos. The paper argues that under some circumstances, log-based replication schemes and replicated state machines (RSMs), like Multi-Paxos, are a waste of resources. For example, when the state is small, it may be more efficient to just manage the state directly instead of managing…
-
One Page Summary: Flease – Lease Coordination without a Lock Server
This paper talks about a decentralized lease management solution. In the past, many lock/lease services have been centralized, placing a single authority to manage all locks in the system. Google’s Chubby, Apache ZooKeeper, etcd, and others rely on a centralized approach and backed by some flavor of a consensus algorithm for fault-tolerance. According to Flease authors,…
Search
Recent Posts
- Paper #196. The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling
- Paper #193. Databases in the Era of Memory-Centric Computing
- Paper #192. OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck
- Paper #191: Occam’s Razor for Distributed Protocols
- Spring 2025 Reading List (Papers ##191-200)
Categories
- One Page Summary (10)
- Other Thoughts (10)
- Paper Review and Summary (14)
- Pile of Eternal Rejections (2)
- Playing Around (14)
- Reading Group (103)
- RG Special Session (4)
- Teaching (2)