In the 142nd reading group meeting, we discussed “Hyrax: Fail-in-Place Server Operation in Cloud Platforms” OSDI’23 paper. Hyrax allows servers with certain types of hardware failures to return to service after some software-only automated mitigation steps.
Traditionally, when a server malfunctions, the VMs are migrated off of it, then the server gets shut down and scheduled for repair. The paper calls this an “all-or-nothing” model for repairs that leaves only perfectly healthy servers in operation. This behavior aligns well with “distributed” people like me — we treat nodes as disposable and replaceable. However, the physical hardware is not disposable and is sometimes hard to replace. The paper suggests that repair time can take up to nearly half a year in some cases, likely due to the availability of parts for older machines. The authors also state that 22% of servers will experience at least one failure in the 6-year lifespan.
Anyway, Hyrax suggests that this shutdown and repair process may be overkill, especially in large data centers and clouds. The repairs take a lot of technician time, consume the resources, and decommission capacity for days at a time. Surprisingly (at least to me), many component failures within a server do not necessarily lead to a server’s complete loss of function, creating a possibility for the “Fail-in-Place” model. The Fail-in-Place approach works by remotely deactivating failed components, physically leaving them inside the server, and returning the server to production, albeit with some capacity/performance restrictions. This way, the capacity is returned quicker, and valuable technician time can be deferred until the repairs can be done more efficiently (i.e. when more failures accumulate in the server or nearby).
The paper focuses on failures of a select few component types: memory DIMMs, SSDs, and cooling fans. For each failure, the system tries to identify a specific failed component, such as a concrete DIMM or SSD. If successful, then that component can be deactivated. The deactivation, however, is a tricky part with multiple problems to solve, starting from actually doing it without physically removing the components to ensuring that a server can still perform adequately enough to host at least some VM types.
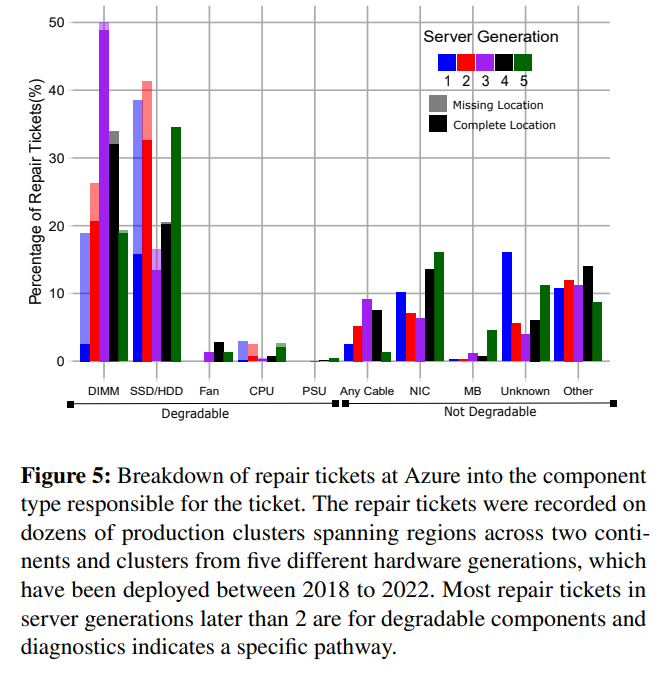
The paper focuses mainly on DIMM deactivation since it is the most complicated case. A faulty “memory stick” gets deactivated via a nearly undocumented BIOS feature, leaving a server in a somewhat crippled state. See, turning off a DIMM or two leaves the server in a configuration not supported by the CPU and its memory controllers. This has to do with DIMM placement rules that get violated. Long story short, such a server will have both the reduced memory and memory address space fragmented by different bandwidths — some memory addresses may work as fast as unaffected servers, and others can have bandwidth degraded by an order of magnitude. To deal with the problem, Hyrax modifies the scheduling policies for the VMs. For example, a degraded server may not host larger VM types that require a lot of memory with high bandwidth. The system also manages VM placement locally to better adhere to these memory regions with different speeds — placing smaller VMs in slower memory regions may be okay since these smaller VMs, even on healthy servers, do not utilize the full memory bandwidth. Naturally, Hyrax has all these combinations precomputed and stored in the database, so the rules are simple mapping of the server’s degraded configuration to VM types it can host.
SSD story is much simpler than DIMMs. Each server the Hyrax prototype was tested on had 6 SSDs, all striped to get maximum performance. The authors calculated that 5 SSDs still have enough performance even for the largest VMs, so deactivating 1 SSD leads to no performance impact. For cooling fan failures, it appears that cooling is severely overprovisioned, and even 2 “dead” fans do not impact the server.
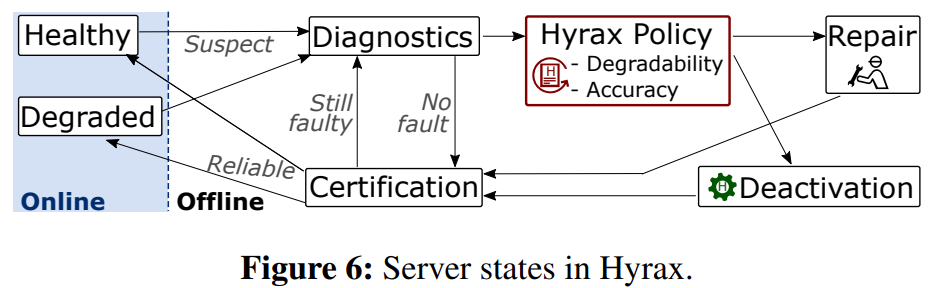
After deactivating the malfunctioning component, Hyrax returns the server to production with the new capacity restrictions for VM sizes. However, it does so only after extensive testing and verification to ensure that correct components have been deactivated and there are no other faults that can cause unstable performance.
The paper provides much more information and details, including an evaluation of the system!