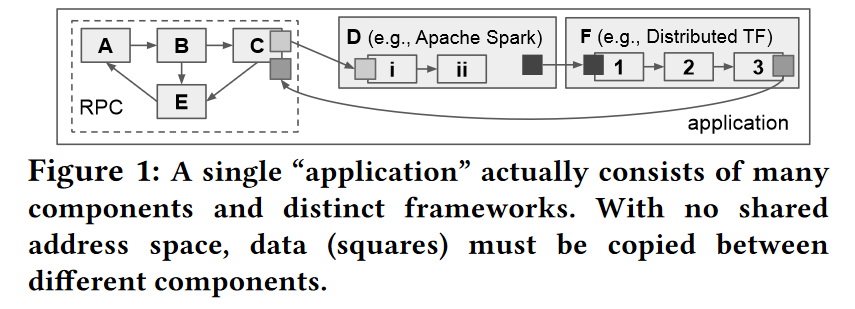
Our 70th meeting covered the “In Reference to RPC: It’s Time to Add Distributed Memory” paper by Stephanie Wang, Benjamin Hindman, and Ion Stoica. This paper proposes some improvements to remote procedure call (RPC) frameworks. In current RPC implementations, the frameworks pass parameters to function by value. The same happens to the function return values. Passing data by value through copying works terrific for small parameters and returns. Furthermore, since the caller and callee have independent copies of the data, there are no side effects when one copy is modified or destroyed. Things start to become less than ideal when the data is large and gets reused in multiple RPC calls.
For example, if a return value of one function needs to propagate to a handful of consecutive calls, we can end up performing many wasteful data copies. The wastefulness occurs as data transfers back to the caller and later gets copied multiple times to new RPCs. The obvious solution is to avoid unnecessary copying and pass the data within the RPC framework by reference using shared memory. In fact, according to the paper, many applications resort to doing just this with distributed key-value stores. Before invoking a remote function, a caller can save the parameters to the shared KV-store, and pass the set of keys as parameters to the RPC. Managing memory at the application level, however, has some problems. For example, the application must manage memory reclamation and cleanup objects no longer needed. Another concern is breaking the semantics of RPCs, as shared mutable memory can have side effects between different components of the system.
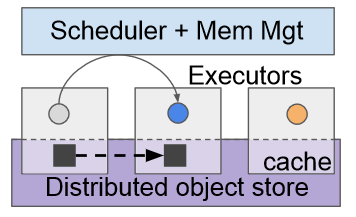
Instead of an ad-hoc application-level solution, the paper proposes a managed approach to shared memory in RPCs. The improved framework preserves the original RPC semantics while enabling shared memory space and facilitating automatic memory management and reclamation. The paper suggests having immutable shared memory where values remain read-only after an initial write. This shared memory system will have a centralized scheduler for RPCs and a memory manager to keep track of memory usage and active memory references. With a centralized memory management approach, the RPC framework can do a few cool things. For instance, the memory manager knows when a reference is passed between nodes and when it goes out of scope on all functions/clients. This global memory knowledge allows the memory manager to perform garbage collection on values no longer needed. The paper describes this in a bit more detail, including the APIs to facilitate global memory tracking. Another benefit of the RPC framework with a centralized scheduler and memory manager is locality awareness. With information about data location in the cluster, the system can collocate function invocation on the machines that already have the values needed.
The paper mentions that the proposed vision is already somewhat used in many specialized systems, such as Ray (Ray is from the same team as the paper) or Distributed TensorFlow. However, these systems are far from general and often used as parts of larger software stacks. The challenge with this new improved RPC framework is to make it general enough to span across the systems to allow better integration and more efficient resource use. I think of this as an RPC-as-a-service kind of vision that facilitates efficiency, interoperability and provides some blanket guarantees on communication reliability.
As always, the paper has a lot more details than I can cover in the summary. We also have the presentation video from the reading group:
Discussion
1) Other Distributed Systems Frameworks. Frameworks for building distributed systems seem to gain more and more popularity these days. We were wondering how these frameworks address some of the same issues, such as copying data between components and managing locality. This is especially relevant for actor-style frameworks. We had some feedback on the Orleans framework. Since locality is important for performance, frameworks tend to move actors to the data. It often seems to be cheaper to move a small executable component than large chunks of data. More specialized data processing systems have been using these tricks for some time and can move both data and compute tasks around for optimal performance.
2) Fault Tolerance. Fault tolerance is always a big question when it comes to backbone distributed systems like this one. With stateful components and shared memory subsystems, the improved RPC framework may be more susceptible to failures. While well-known and traditional techniques can be used to protect the state, such as replicating the shared memory, these will make the system more complicated and may have performance implications. Some components, like scheduler and memory manager, are on the critical path of all function invocations. Having strongly consistent replication there may not be the best choice for scalability and performance. The other option is to expose errors to the application and let them deal with the issues like in more traditional RPC scenarios or lower-level communication approaches. However, due to the size and complexity of the improved system, it would have been nice to have some failure masking. We were lucky to ask Stephanie Wang, the author of the paper, about fault tolerance, and she suggests RPC clients handle errors by reties, however, she also mentioned that it is still an open question about how much overall fault tolerance and fault masking is needed in a system like this one.
3) Programming Model vs. Implementation. Another important discussion question was on the vision itself. The paper mentions a few specialized systems that already have many of the features described. This made us wonder what is the paper proposes then? and what are the challenges? It appeared to us that the paper’s vision is for a general and interoperable RPC system to act as a glue for larger software stacks. Stephanie provided some of her first-hand feedback here that I will quote directly:
“In my opinion, Ray already has (most of) the right features for the programming model but not the implementation. One of the main implementation areas that the paper discusses is distributed memory management. Actually, I don’t think that any of the systems mentioned, including Ray, do this super well today. For example, I would say that Distributed TensorFlow is quite sophisticated in optimizing memory usage, but it’s not as flexible as pure RPC because it requires a static graph. The second thing that I think is still missing is interoperability, as you said. I believe that this will require further innovations in both programming model and implementation.”