This paper talks about a decentralized lease management solution. In the past, many lock/lease services have been centralized, placing a single authority to manage all locks in the system. Google’s Chubby, Apache ZooKeeper, etcd, and others rely on a centralized approach and backed by some flavor of a consensus algorithm for fault-tolerance. According to Flease authors, such centralized approach 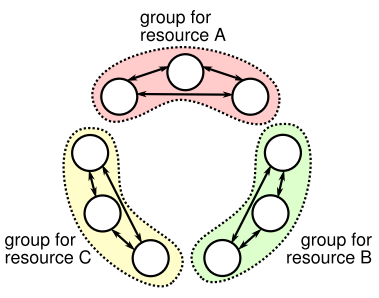 may not be ideal at all times and can create a bottlenecks when coordination is required only within small groups of nodes in the system. Distributed filesystems seem to be candidates for this sort of lock management, as a group of nodes tend to be responsible only for resources sharded to that group. Each such group acts independently and maintains locks for resources assigned to it, making a global lock not necessary.
may not be ideal at all times and can create a bottlenecks when coordination is required only within small groups of nodes in the system. Distributed filesystems seem to be candidates for this sort of lock management, as a group of nodes tend to be responsible only for resources sharded to that group. Each such group acts independently and maintains locks for resources assigned to it, making a global lock not necessary.
The implementation of decentralized, sharded, lock management system is rather trivial. Since getting a lock/lease requires nodes to reach the consensus about the lease ownership and duration, a Paxos algorithm will suffice. In fact Flease uses a flavor of Paxos built with a distributed register. Right away we can see why Flease targets systems that are sharded into small non-overlapping groups. Running Paxos over too many nodes will degrade the performance.
Just like other lease system, Flease needs to have synchronized clocks with known max time skew uncertainty ε to control lease expiration. It also places some restrictions on minimum lease duration due to the network characteristics, i.e. lease duration has to be greater than two RTTs and greater than ε. Choosing the max lease duration is important for performance reasons.
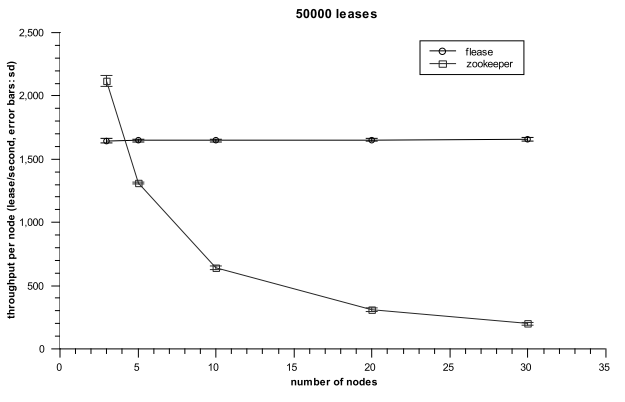 Flease was evaluated against ZooKeeper, as both are implemented in Java and use the same network IO libraries.The figure shows throughput per (client) machine with Flease (straight line) and ZooKeeper. Flease uses small groups of 3 nodes, each running Paxos, and ZooKeeper runs on 3 nodes as well, with all clients connecting to it for lock management. As expected form this experiment, Flease has greater parallelism. When running 30 clients, Flease runs 10 Paxos machines, while ZooKeeper still operates a single one (3 nodes) with 30 clients connected. It is unclear how quickly the performance of Flease will degrade as the group size increases. In essence, similar if not better results could have been achieved by deploying separate ZooKeepers for each group to allow for the same level of parallelism.
Flease was evaluated against ZooKeeper, as both are implemented in Java and use the same network IO libraries.The figure shows throughput per (client) machine with Flease (straight line) and ZooKeeper. Flease uses small groups of 3 nodes, each running Paxos, and ZooKeeper runs on 3 nodes as well, with all clients connecting to it for lock management. As expected form this experiment, Flease has greater parallelism. When running 30 clients, Flease runs 10 Paxos machines, while ZooKeeper still operates a single one (3 nodes) with 30 clients connected. It is unclear how quickly the performance of Flease will degrade as the group size increases. In essence, similar if not better results could have been achieved by deploying separate ZooKeepers for each group to allow for the same level of parallelism.
The problem of lock management is important and Flease give a good example of application that can benefit from a less-centralized solution to locks. However, the approach in this paper is as trivial as deploying multiple lock management systems for each of the independent non-overlapping groups of nodes in the system. Flease performance will degrade if group size grows above 3 to 5 nodes. In addition, the algorithm is not suitable when group boundaries must be breached on occasion.