database
-
Paper #193. Databases in the Era of Memory-Centric Computing
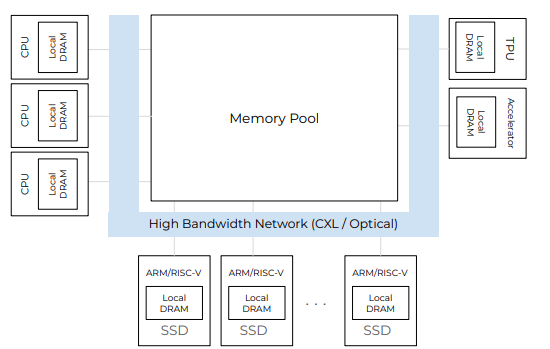
Last week, we read “Databases in the Era of Memory-Centric Computing” CIDR’25 paper in our reading group. This paper argues that the rising cost of main memory and lagging improvement in memory bandwidth do not bode well for traditional computing architectures centered around computing devices (i.e., CPUs). As CPUs get more cores, the memory bandwidth…
-
Paper #192. OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck
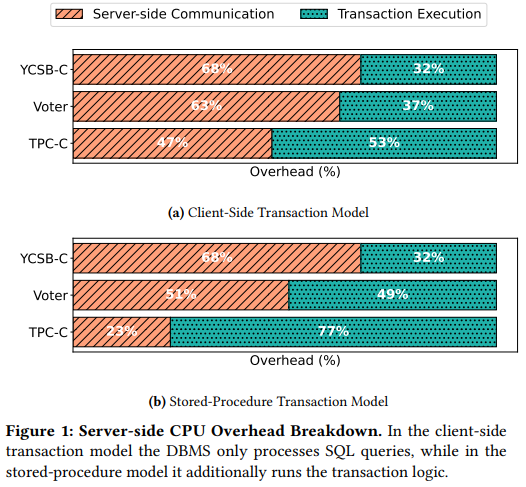
Last week we read “OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck” CIDR’25 paper by Xinjing Zhou, Viktor Leis, Xiangyao Yu, Michael Stonebraker. This paper revisits the original “OLTP Through the Looking Glass, and What We Found There” paper and examines the bottlenecks in modern OLTP databases. The new paper…
-
Reading Group. Chardonnay: Fast and General Datacenter Transactions for On-Disk Databases
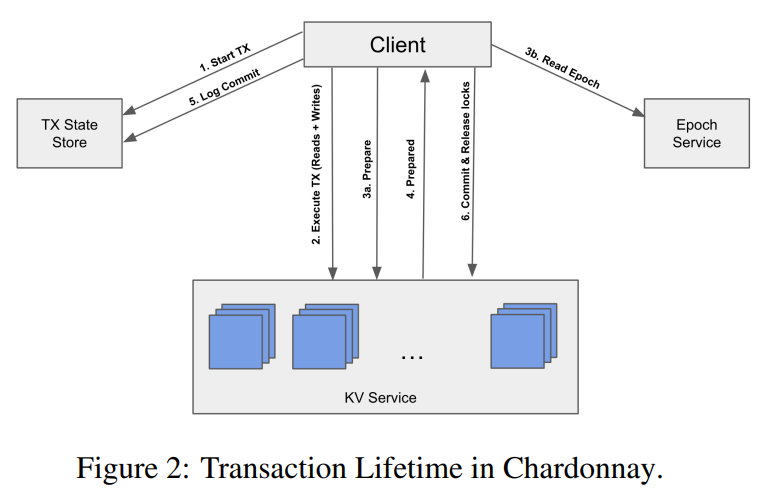
Last week, we looked at the “Chardonnay: Fast and General Datacenter Transactions for On-Disk Databases” OSDI’23 paper by Tamer Eldeeb, Xincheng Xie, Philip A. Bernstein, Asaf Cidon, Junfeng Yang. The paper presents a transactional database built on the assumption of having a very fast two-phase commit protocol. Coordination, like a two-phase commit (2PC), usually has…
-
Reading Group Paper. Take Out the TraChe: Maximizing (Tra)nsactional Ca(che) Hit Rate
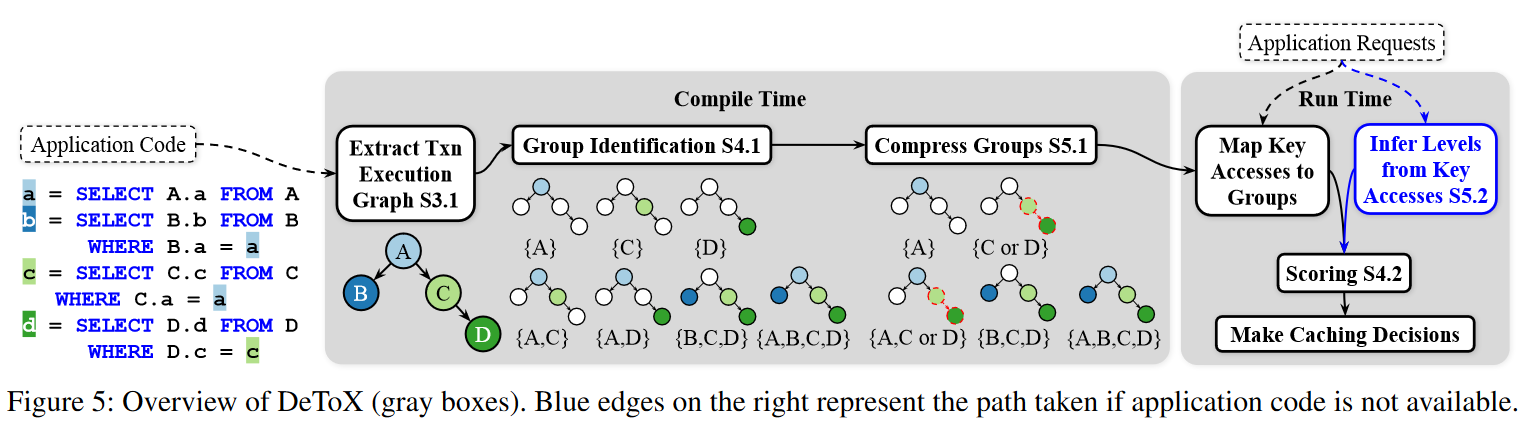
In this week’s reading group, we discussed the “Take Out the TraChe: Maximizing (Tra)nsactional Ca(che) Hit Rate” OSDI’23 paper by Audrey Cheng, David Chu, Terrance Li, Jason Chan, Natacha Crooks, Joseph M. Hellerstein, Ion Stoica, Xiangyao Yu. This paper argues against optimizing for object hit rate in caches for transactional databases. The main logic behind…
-
Reading Group. Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service
In the 120th DistSys meeting, we talked about “Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service” ATC’22 paper by Mostafa Elhemali, Niall Gallagher, Nicholas Gordon, Joseph Idziorek, Richard Krog, Colin Lazier, Erben Mo, Akhilesh Mritunjai, Somu Perianayagam, Tim Rath, Swami Sivasubramanian, James Christopher Sorenson III, Sroaj Sosothikul, Doug Terry, Akshat Vig.…
-
Reading Group. The Case for Distributed Shared-Memory Databases with RDMA-Enabled Memory Disaggregation
In the 122nd reading group meeting, we read “The Case for Distributed Shared-Memory Databases with RDMA-Enabled Memory Disaggregation” paper by Ruihong Wang, Jianguo Wang, Stratos Idreos, M. Tamer Özsu, Walid G. Aref. This paper looks at the trend of resource disaggregation in the cloud and asks whether distributed shared memory databases (DSM-DBs) can benefit from…
-
Reading Group Special Session: Scalability and Fault Tolerance in YDB
YDB is an open-source Distributed SQL Database. YDB is used as an OLTP Database for mission-critical user-facing applications. It provides strong consistency and serializable transaction isolation for the end user. One of the main characteristics of YDB is scalability to very large clusters together with multitenancy, i.e. ability to provide an isolated user environment for…
-
Reading Group. Exploiting Symbolic Execution to Accelerate Deterministic Databases
We have covered 60 papers in our reading group so far! The 60th paper we explored was “Exploiting Symbolic Execution to Accelerate Deterministic Databases” from ICDCS’20. I enjoyed the paper quite a lot, even though there are some claims I do not necessarily agree with. The paper solves the problem of executing transactions in deterministic…
-
Reading Group. chainifyDB: How to get rid of your Blockchain and use your DBMS instead
Our recent meeting focused on Blockchains, as we discussed “chainifyDB: How to get rid of your Blockchain and use your DBMS instead” CIDR’21 paper. The presentation by Karolis Petrauskas is available here: The paper argues for using existing and proven technology to implement a permissioned blockchain-like system. The core idea is to leverage relational SQL-99…
-
Reading Group Special Session: Distributed Transactions in YugabyteDB
When: May 11th at 12:00 pm EST Who: Karthik Ranganathan. Karthik Ranganathan is a founder and CTO of YugabyteDB, a globally distributed, strongly consistent database. Prior to Yugabyte, Karthik was at Facebook, where he built the Cassandra database. In this talk, Karthik will discuss Yugabyte’s use of time synchronization and Raft protocol along with some…
Search
Recent Posts
- Paper #196. The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling
- Paper #193. Databases in the Era of Memory-Centric Computing
- Paper #192. OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck
- Paper #191: Occam’s Razor for Distributed Protocols
- Spring 2025 Reading List (Papers ##191-200)
Categories
- One Page Summary (10)
- Other Thoughts (10)
- Paper Review and Summary (14)
- Pile of Eternal Rejections (2)
- Playing Around (14)
- Reading Group (103)
- RG Special Session (4)
- Teaching (2)