-
Reading Group. Prescient Data Partitioning and Migration for Deterministic Database Systems
In the 75th reading group session, we discussed the transaction locality and dynamic data partitioning through the eyes of a recent OSDI’21 paper – “Don’t Look Back, Look into the Future: Prescient Data Partitioning and Migration for Deterministic Database Systems.” This interesting paper solves the transaction locality problem in distributed, sharded deterministic databases. The deterministic…
-
Reading Group. Viewstamped Replication Revisited
Our 74th paper was a foundational one — we looked at Viestamped Replication protocol through the lens of the “Viewstamped Replication Revisited” paper. Joran Dirk Greef presented the protocol along with bits of his engineering experience using the protocol in practice. Viestamped Replication (VR) solves the problem of state machine replication in a crash fault…
-
Reading Group. Polyjuice: High-Performance Transactions via Learned Concurrency Control
Our 73rd reading group meeting continued with discussions on transaction execution systems. This time we looked at the “Polyjuice: High-Performance Transactions via Learned Concurrency Control” OSDI’21 paper by Jiachen Wang, Ding Ding, Huan Wang, Conrad Christensen, Zhaoguo Wang, Haibo Chen, and Jinyang Li. This paper explores single-server transaction execution. In particular, it looks at concurrency…
-
Reading Group. Meerkat: Multicore-Scalable Replicated Transactions Following the Zero-Coordination Principle
Our 72nd paper was on avoiding coordination as much as possible. We looked at the “Meerkat: Multicore-Scalable Replicated Transactions Following the Zero-Coordination Principle” EuroSys’20 paper by Adriana Szekeres, Michael Whittaker, Jialin Li, Naveen Kr. Sharma, Arvind Krishnamurthy, Dan R. K. Ports, Irene Zhang. As the name suggests, this paper discusses coordination-free distributed transaction execution. In…
-
How to Read Computer Science (Systems) Papers using Shampoo Algorithm
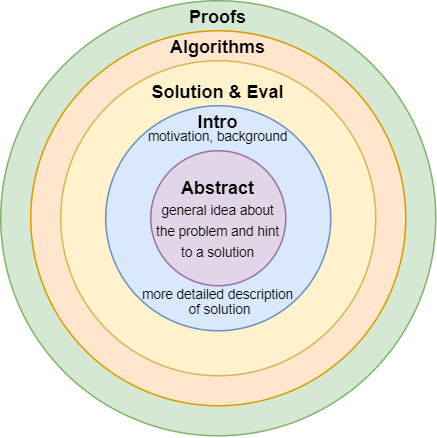
I think most academics had to answer a question on how to approach papers. It is the beginning of the semester and a new academic year, and I have heard this question quite a lot in the past two weeks. Interestingly enough, I believe that almost every academic active on the Internet has written about…
-
Reading Group. DistAI: Data-Driven Automated Invariant Learning for Distributed Protocols
In the 71st DistSys reading group meeting, we have discussed “DistAI: Data-Driven Automated Invariant Learning for Distributed Protocols” OSDI’21 paper. Despite the misleading title, this paper has nothing to do with AI or Machine Learning. Instead, it focuses on the automated search for invariants in distributed algorithms. I will be brief and a bit hand-wavy…
-
One Page Summary. Photons: Lambdas on a diet
Recently, to prepare for a class I teach this semester, I went through the “Photons: Lambdas on a diet” SoCC’20 paper by Vojislav Dukic, Rodrigo Bruno, Ankit Singla, Gustavo Alonso. This is a very well-written paper with a ton of educational value for people like me who are only vaguely familiar with serverless space! The…
-
Reading Group. In Reference to RPC: It’s Time to Add Distributed Memory
Our 70th meeting covered the “In Reference to RPC: It’s Time to Add Distributed Memory” paper by Stephanie Wang, Benjamin Hindman, and Ion Stoica. This paper proposes some improvements to remote procedure call (RPC) frameworks. In current RPC implementations, the frameworks pass parameters to function by value. The same happens to the function return values.…
-
Reading Group. Fault-Tolerant Replication with Pull-Based Consensus in MongoDB
In the last reading group meeting, we discussed MongoDB‘s replication protocol, as described in the “Fault-Tolerant Replication with Pull-Based Consensus in MongoDB” NSDI’21 paper. Our reading group has a few regular members from MongoDB, and this time around, Siyuan Zhou, one of the paper authors, attended the discussion, so we had a perfect opportunity to…
-
Reading Group. Move Fast and Meet Deadlines: Fine-grained Real-time Stream Processing with Cameo
In the 68th reading group session, we discussed scheduling in dataflow-like systems with Cameo. The paper, titled “Move Fast and Meet Deadlines: Fine-grained Real-time Stream Processing with Cameo,” appeared at NSDI’21. This paper discusses some scheduling issues in data processing pipelines. When a system answers a query, it breaks the query into several steps or…
 I am an assistant professor of computer science at the University of New Hampshire. My research interests lie in distributed systems, distributed consensus, fault tolerance, reliability, and scalability.
I am an assistant professor of computer science at the University of New Hampshire. My research interests lie in distributed systems, distributed consensus, fault tolerance, reliability, and scalability.
 @AlekseyCharapko
@AlekseyCharapko
 aleksey.charapko@unh.edu
aleksey.charapko@unh.edu