cache
-
Reading Group #149. On-demand Container Loading in AWS Lambda
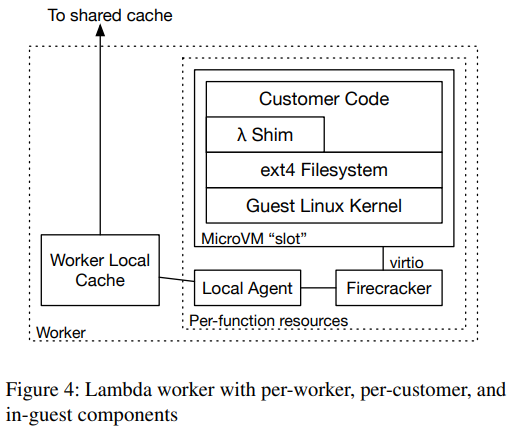
For the 149th paper in the reading group, we read “On-demand Container Loading in AWS Lambda” by Marc Brooker, Mike Danilov, Chris Greenwood, and Phil Piwonka. This paper describes the process of managing the deployment of containers in AWS Lambda. See, when AWS Lambda first came out, its runtime was somewhat limited — users could…
-
Reading Group. Palette Load Balancing: Locality Hints for Serverless Functions
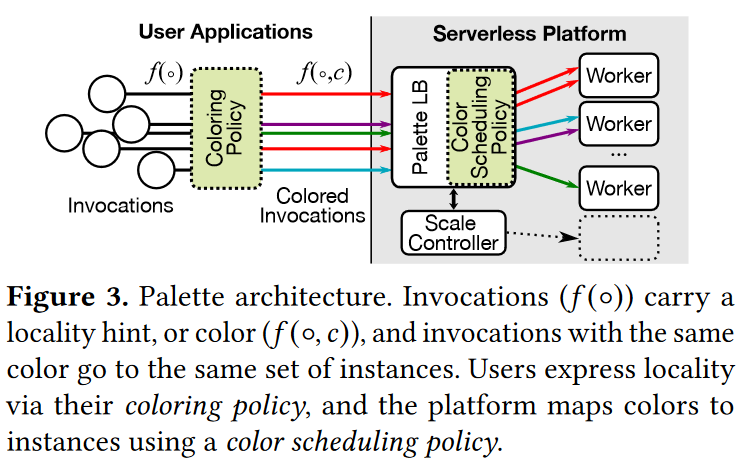
This week, our reading group focused on serverless computing. In particular, we looked at the “Palette Load Balancing: Locality Hints for Serverless Functions” EuroSys’23 paper by Mania Abdi, Sam Ginzburg, Charles Lin, Jose M Faleiro, Íñigo Goiri, Gohar Irfan Chaudhry, Ricardo Bianchini, Daniel S. Berger, Rodrigo Fonseca. I did a short improvised presentation since the…
-
Reading Group Paper. Take Out the TraChe: Maximizing (Tra)nsactional Ca(che) Hit Rate
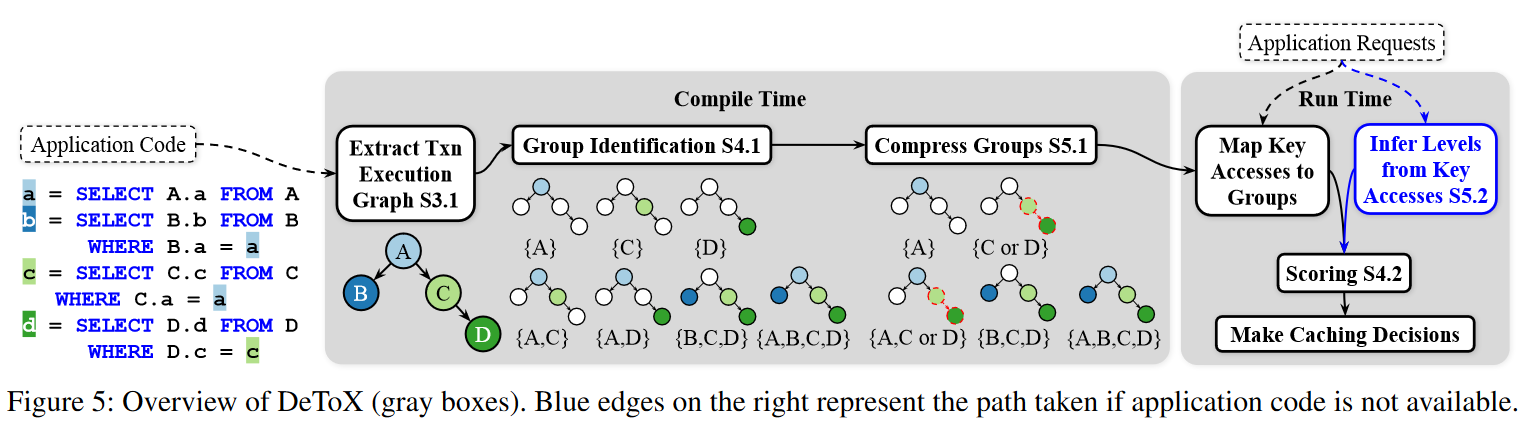
In this week’s reading group, we discussed the “Take Out the TraChe: Maximizing (Tra)nsactional Ca(che) Hit Rate” OSDI’23 paper by Audrey Cheng, David Chu, Terrance Li, Jason Chan, Natacha Crooks, Joseph M. Hellerstein, Ion Stoica, Xiangyao Yu. This paper argues against optimizing for object hit rate in caches for transactional databases. The main logic behind…
-
Reading Group. CompuCache: Remote Computable Caching using Spot VMs
In the 92nd reading group meeting, we have covered “CompuCache: Remote Computable Caching using Spot VMs” CIDR’22 paper by Qizhen Zhang, Philip A. Bernstein, Daniel S. Berger, Badrish Chandramouli, Vincent Liu, and Boon Thau Loo. Cloud efficiency seems to be a popular topic recently. A handful of solutions try to improve the efficiency of the…
-
Reading Group. FlightTracker: Consistency across Read-Optimized Online Stores at Facebook
Last DistSys Reading Group we have discussed “FlightTracker: Consistency across Read-Optimized Online Stores at Facebook.” This paper is about consistency in Facebook’s TAO caching stack. TAO is a large social graph storage system composed of many caches, indexes, and persistent storage backends. The sheer size of Facebook and TAO makes it difficult to enforce meaningful…
-
Reading Group. A large scale analysis of hundreds of in-memory cache clusters at Twitter.
In the 41st distributed systems reading group meeting, we have looked at in-memory caches through the lens of yet another OSDI20 paper: “A large scale analysis of hundreds of in-memory cache clusters at Twitter.” This paper explores various cache usages at Twitter and distills the findings into a digestible set of figures. I found the…
Search
Recent Posts
- Paper #196. The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling
- Paper #193. Databases in the Era of Memory-Centric Computing
- Paper #192. OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck
- Paper #191: Occam’s Razor for Distributed Protocols
- Spring 2025 Reading List (Papers ##191-200)
Categories
- One Page Summary (10)
- Other Thoughts (10)
- Paper Review and Summary (14)
- Pile of Eternal Rejections (2)
- Playing Around (14)
- Reading Group (103)
- RG Special Session (4)
- Teaching (2)