In the 41st distributed systems reading group meeting, we have looked at in-memory caches through the lens of yet another OSDI20 paper: “A large scale analysis of hundreds of in-memory cache clusters at Twitter.” This paper explores various cache usages at Twitter and distills the findings into a digestible set of figures. I found the paper rather educational. It starts by describing Twitter’s cache architecture, called Twemcache. Twemcache operates as a managed service, with cache clustering starting up, scaling up/down in a semi-automatic manner. After the brief Twemcache description, the paper starts to distill the findings of the cache usage itself. A few of the more interesting findings:
- A sizeable number of cache cluster at Twitter are used for write-heavy workloads/applications
- 15% of key-value pairs have values smaller than the key. Of course, this may be specific to Twitter’s keying scheme, which authors say seem to have rather large keys.
- Objects of some sizes tend to be more popular. Side question here. Does this correlate with some application or use case? So, maybe some use cases favor certain sizes?
- TTL usage: bounding inconsistency/staleness, implicit deletion of objects.
- TTL usage: expirations are more efficient than evictions. This one kind of makes sense, but it shifts some of the burdens of managing objects life-cycle in the cache over to applications that set TTLs
The paper goes more in-depth about a variety of other important topics, such as evection methods, object popularity, etc. Another important point and potentially one of the most important ones for the academic community is the dataset — the authors released their dataset, which is a super nice thing to do.
Our presentation is available here:
Discussion
This paper was educational and shed a light on cache usage at a big company, including some pretty interesting statistics. We did not have fundamental questions about the paper or its findings.
1) Dataset. One of the bigger discussion points that were mentioned multiple times is the public dataset. Having such a large dataset is very nice for many researchers in academia. Of course, the dataset applies to the cache usage, but we think it may be useful for database researchers as well. For example, taking into account all the cache misses may produce some real representation of read workloads against the storage systems. However, such access patterns may be less useful when applied to strongly consistent storage, as caches are less likely to be used there.
2) Dataset distribution. The dataset for this paper is huge (2.8 TB compressed), and distributing it is a challenge on its own, making it even more impressive that a dataset is available.
3) Object Popularity. Authors note a few deviations from expected: (1) unpopular objects are often even more unpopular than expected, and (2) popular objects are less popular than expected. One question we had here (and in many other places) is how specific such finding is to Twitter? Maybe a better insight into the type of workloads the exhibit such deviations from expected would have helped understand this better, but it is likely that the authors simply could not disclose the details about specific workloads/tasks.
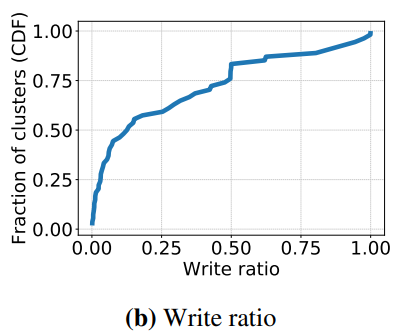
4) Write-heavy workloads. The biggest question here is what types of workloads use cache and are write-heavy. One suggestion was “counters” (i.e. likes, retweets, etc), which makes sense as it is a piece of data that may be both accessed a lot, maybe a bit stale, and gets updated relatively frequently. Counters of sorts are also used as rate limiters, according to the paper. Another idea is maybe some analytics workloads, where some weights/models are updated relatively frequently.
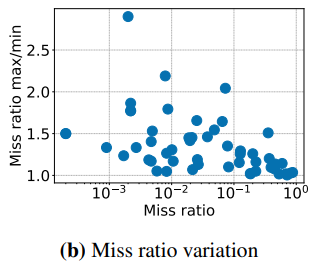
5) Miss ratio. It was rather interesting to see the miss ratio figures, especially the ratio of max miss ratio to min miss ratio. Ultimately, a cache miss must be followed by a read from the underlying storage system. A high miss ratio puts more stress on the storage system. A high ratio between max and min miss ratios over the course of a week may indicate a workload that spikes in the number of cache misses on occasion. Such workload would require a more robust/overprovisioned storage to tolerate the spikes in requests to it due to cache misses. For example, Facebook avoids sudden traffic migrations between datacenters to control cache misses and not overwhelm the underlying infrastructure.