On Wednesday we were discussing scheduling in large distributed ML/AI systems. Our main paper was the “Heterogeneity-Aware Cluster Scheduling Policies for Deep Learning Workloads.” one from OSDI’20. However, it was a bit outside of our group’s comfort zone (outside of my comfort zone for sure). Luckily we had an extensive presentation with a complete background overview of prior ML/AI scheduling works.
Scheduling problems are not new by any means. We have schedulers at the OS level to allocate CPU resources, we have more sophisticated schedulers for large clusters, HPC systems, etc. So scheduling for machine learning should not pose a big problem, given all the prior scheduling work in the literature and practice. However, this is not necessarily the case, since scheduling for ML/AI systems introduces a few additional challenges. One issue is unpredictable completion time. For instance, many similar jobs may be started with different hyperparameters, and get killed off as they progress, making it harder to have a fair scheduler. Another issue is the non-uniformity of access to resources — information exchange between GPUs is faster within the confines of a single machine. When a job is scheduled on resources (GPUs/FPGAs, etc) spread across many servers, the network latency/bandwidth may get in a way. And the difference in how fast or slow the data can be exchanged between the devices grows with the degree of network separation. I find this problem similar to NUMA.
In the context of today’s paper, the additional challenges are the heterogenicity of resources in the cluster. This is something more traditional OS schedulers started to consider only relatively recently on ARM with big.LITTLE CPU architectures (and will consider soon on x86). Here, however, we have more than just a few resource variations. The paper considers different types of GPUs, but they also mention other special-purpose hardware, like FPGAs. To make things even more complicated, faster hardware provides a non-uniform speedup for different types of ML tasks — one application may have a 3x speedup from a switch to a faster GPU, while some other task may have a ten-fold speedup from the same switch. Finally, different users of the same system may even have different scheduling goals or objectives, as for some (researchers?) the completion time may be more important, while for others (production users in the cloud?) the fairness may play a bigger role.
Gavel separates the scheduling into a set of distinct components or steps. The scheduling policy takes into account the scheduling objective, i.e. the fairness or completion time. Gavel implements various scheduling policies, such as LAS, FIFO, Shortest Job First, and hierarchical composition of these policies. The scheduling mechanism executes the policy on the cluster. The throughput estimator provides the estimation of the speed of different tasks, to be fed into the policy engine if the performance estimation is not provided by the user. This is an important piece since the performance impact of different hardware varies for different training tasks!
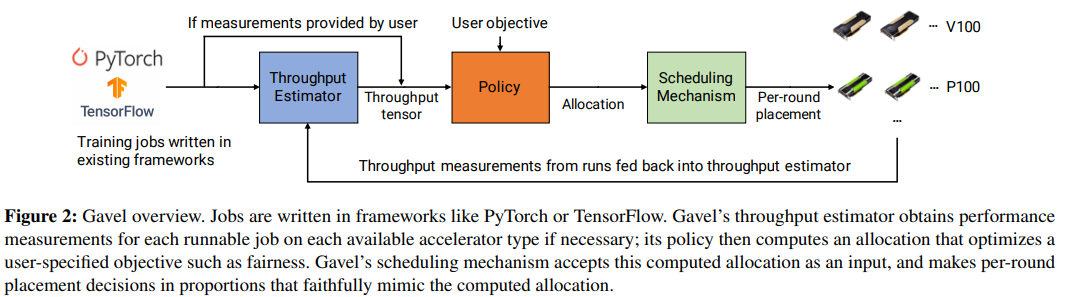
The scheduling itself is iterative. The policy engine provides the resource allocation for a task. For example, it may say that a task needs to run 60% of the type on GPU A and 40% of the time on GPU B. This of course is computed given the user objectives and other competing tasks. The scheduling mechanism takes the allocation and tries to enforce it in an iterative manner. I will leave the detailed discussion of scheduling to the paper. The intuition, however, is rather simple. Gavel keeps track of how many iterations have been done on each resource (i.e. GPU) type, compares it with the scheduling plan, and computes the priority score for the next iteration, potentially reshuffling the tasks. So for example, if a scheduling plan calls for 60% on GPU A, but so far the task used GPU A in only 20% of scheduling iterations, then the GPU A will have a higher priority for being scheduled on the next iteration/round.
The paper evaluated the scheduling of training tasks both on a real cluster and with extensive simulations.
Discussion
1) Type of jobs. The paper describes the scheduling of training jobs, but there are other types of jobs. For example, there are interactive jobs running in things like Jupiter notebooks. This type of job has to be scheduled all the time, and cannot be completely preempted pr paused due to its interactive nature. Also, trained models are only good when they are used for something. Inference jobs may have different requirements than training jobs. For example, for a production inference task, it may be more important to schedule it on multiple different machines for fault tolerance, an opposite approach to the training jobs when scheduling on as few machines as possible improves the performance through minimizing the network bottlenecks. Taking into account these other types of tasks running in the same cluster may complicated scheduling further.
2) Task movement. We talked about the performance penalty of scheduling on many different machines due to the network latency and bandwidth. However, as tasks get scheduled against different resources, they have to migrate over the network, so a very frequent change of resources may not be very good for the performance.
The task movement itself is a tricky problem. At least it appears so to an uninitiated person like me. Do we move a task at some snapshot point? How to insert that snapshot if the task itself does not make it? Can we move the task just by dumping the process and (GPU) memory on one server and restoring it on another? Does this even work across different GPU designs/generations?
3) Fault tolerance. What is the granularity of fault tolerance in large cloud ML/AI systems? Obviously, if the process crashes for some reason, we want to restart at some previous checkpoint/snapshot. But whose responsibility is it to make these snapshots? The snapshots may be costly to make too frequently, so users may be reluctant to make snapshot their progress too often. But since the snapshots may be needed for task movement, can we take advantage of that for fault tolerance? Again, the uninitiated minds are speaking here, so likely these are all solved questions.
4) Planetary-scale scheduling. We want to avoid (frequent) communication between GPUs over the network because of limited bandwidth. On a geo-scale, the bandwidth may become even more limited, and the “first-byte” latency even larger, further impacting the performance. So it is likely not a good idea to schedule a task across WAN (or maybe even across availability zones in the same region). However, moving the tasks on a planetary scale between regions may be something to consider, if this is done infrequently, and remote regions have more of the desired resource available. This requires longer-term planning though, as we would like to make sure that an expensive move can be offset by the task using as much of that resources as possible before being moved again.
5) User performance estimates. Gavel has a performance estimation component, but it can take performance estimates from the users. It would be interesting to see if these user-provided estimates are correct in real world. Also, can Gavel adjust these user estimates based on its own measurements?