-
Reading Group. The Case for Distributed Shared-Memory Databases with RDMA-Enabled Memory Disaggregation
In the 122nd reading group meeting, we read “The Case for Distributed Shared-Memory Databases with RDMA-Enabled Memory Disaggregation” paper by Ruihong Wang, Jianguo Wang, Stratos Idreos, M. Tamer Özsu, Walid G. Aref. This paper looks at the trend of resource disaggregation in the cloud and asks whether distributed shared memory databases (DSM-DBs) can benefit from…
-
Reading Group. Not that Simple: Email Delivery in the 21st Century
I haven’t been posting new reading group paper summaries lately, but I intend to fix that gap and resume writing these. Our 123rd paper was about email: “Not that Simple: Email Delivery in the 21st Century” by Florian Holzbauer, Johanna Ullrich, Martina Lindorfer, and Tobias Fiebig. This paper studies whether different emerging standards and technologies impact email delivery…
-
Winter Term Reading Group Papers: ##121-130
Our winter set of papers! The schedule is also in our Google Calendar. C5: Cloned Concurrency Control that Always Keeps Up [VLDB’23] Authors: Jeffrey Helt, Abhinav Sharma, Daniel J. Abadi, Wyatt Lloyd, Jose M. Faleiro What: Enabling a more concurrent execution of copied/replicated operations at the followers. When: December 14th The Case for Distributed Shared-Memory…
-
Fall Term Reading Group Papers: ##111-120
Below is a list of papers for the fall term of the distributed systems reading group. The list is also on the reading group’s Google Calendar. Metastable Failures in the Wild [OSDI’22] Authors: Lexiang Huang, Matthew Magnusson, Abishek Bangalore Muralikrishna, Salman Estyak, Rebecca Isaacs, Abutalib Aghayev, Timothy Zhu, Aleksey Charapko What: An exploration of many…
-
Reading Group Special Session: Scalability and Fault Tolerance in YDB
YDB is an open-source Distributed SQL Database. YDB is used as an OLTP Database for mission-critical user-facing applications. It provides strong consistency and serializable transaction isolation for the end user. One of the main characteristics of YDB is scalability to very large clusters together with multitenancy, i.e. ability to provide an isolated user environment for…
-
Metastable Failures in the Wild
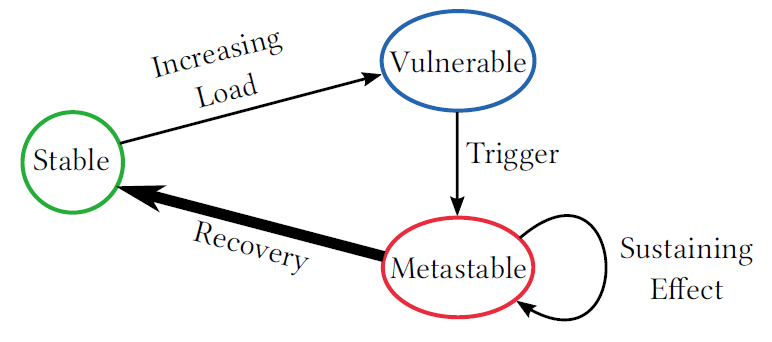
Metastable failures in distributed systems are failures that “feed” and strengthen their own “failed” condition. The main characteristic of a metastable failure is a positive feedback loop that keeps the system in a degraded/failed state. These failures are hard to spot, as they always start with some other distraction — some trigger event that nudges…
-
Reading Group. Darwin: Scale-In Stream Processing
In the 99th reading group meeting, we discussed stream processing. The paper we read, “Darwin: Scale-In Stream Processing” by Lawrence Benson and Tilmann Rabl, argues that many stream processing systems are relatively inefficient in utilizing the hardware. These inefficiencies stem from the need to ingest large volumes of data to the requirement of durably storing…
-
Reading Group. Achieving High Throughput and Elasticity in a Larger-than-Memory Store
“Achieving High Throughput and Elasticity in a Larger-than-Memory Store” paper by Chinmay Kulkarni, Badrish Chandramouli, and Ryan Stutsman discusses elastic, scalable distributed storage. The paper proposes Shadowfax, an extension to the FASTER single-node KV-store. The particular use case targeted by Shadowfax is the ingestion of large volumes of (streaming) data. The system does not appear…
-
Reading Group. Shard Manager: A Generic Shard Management Framework for Geo-distributed Applications
The 97th paper in the reading group was “Shard Manager: A Generic Shard Management Framework for Geo-distributed Applications.” This paper from Facebook talks about a sharding framework used in many of Facebook’s internal systems and applications. Sharding is a standard way to provide horizontal scalability — systems can break down their data into (semi-) independent…
-
Reading Group. Solar Superstorms: Planning for an Internet Apocalypse
Our 96th reading group paper was very different from the topics we usually discuss. We talked about the “Solar Superstorms: Planning for an Internet Apocalypse” SIGCOMM’21 paper by Sangeetha Abdu Jyothi. Now (May 2022), we are slowly approaching the peak of solar cycle 25 (still due in a few years?) as the number of observable…
 I am an assistant professor of computer science at the University of New Hampshire. My research interests lie in distributed systems, distributed consensus, fault tolerance, reliability, and scalability.
I am an assistant professor of computer science at the University of New Hampshire. My research interests lie in distributed systems, distributed consensus, fault tolerance, reliability, and scalability.
 @AlekseyCharapko
@AlekseyCharapko
 aleksey.charapko@unh.edu
aleksey.charapko@unh.edu