Playing Around
-
Cloudy Forecast: How Predictable is Communication Latency in the Cloud?
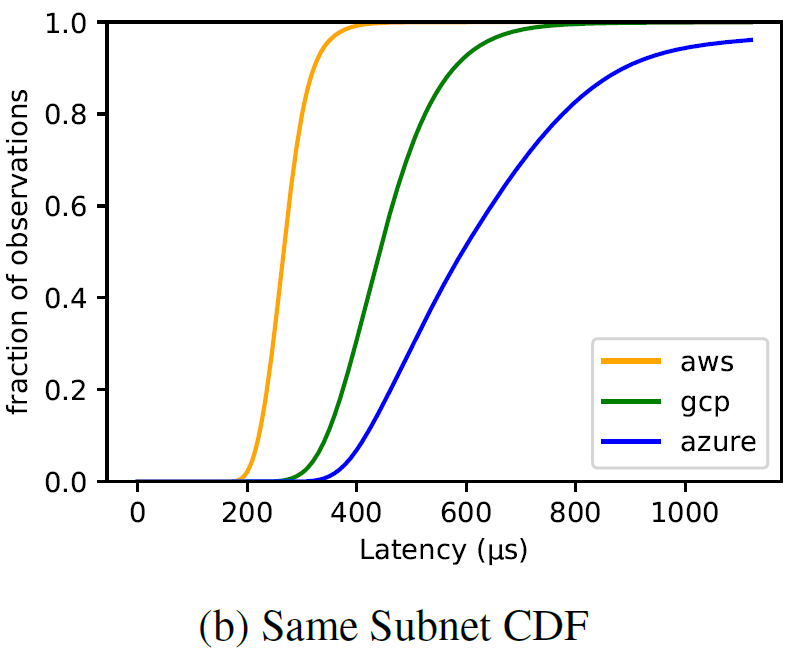
Many, if not all, practical distributed systems rely on partial synchrony in one way or another, be it a failure detection, a lease mechanism, or some optimization that takes advantage of synchrony to avoid doing a bunch of extra work. These partial synchrony approaches need to know some crucial parameters about their world to estimate…
-
PigPaxos: continue devouring communication bottlenecks in distributed consensus.

This is a short follow-up to Murat’s PigPaxos post. I strongly recommend reading it first as it provides full context for what is to follow. And yes, it also includes the explanation of what pigs have to do with Paxos. Short Recap of PigPaxos. In our recent SIGMOD paper we looked at the bottleneck of…
Search
Recent Posts
- Paper #196. The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling
- Paper #193. Databases in the Era of Memory-Centric Computing
- Paper #192. OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck
- Paper #191: Occam’s Razor for Distributed Protocols
- Spring 2025 Reading List (Papers ##191-200)
Categories
- One Page Summary (10)
- Other Thoughts (10)
- Paper Review and Summary (14)
- Pile of Eternal Rejections (2)
- Playing Around (14)
- Reading Group (103)
- RG Special Session (4)
- Teaching (2)