Aleksey Charapko
-
Paper #196. The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling

The last paper we covered in the Distributed Systems Reading group discussed CPUs, data centers, scheduling, and carbon emissions—we read “The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling.” Below is my improvised presentation of this paper for the reading group. This paper was an educational read for me, as I learned…
-
Paper #193. Databases in the Era of Memory-Centric Computing
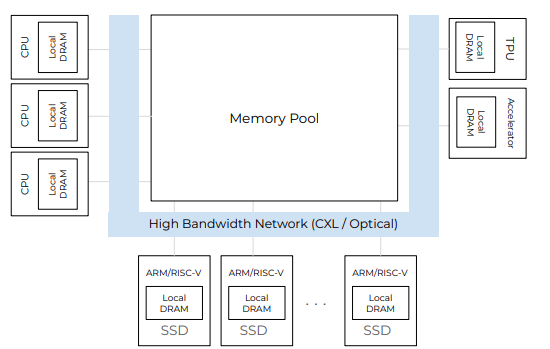
Last week, we read “Databases in the Era of Memory-Centric Computing” CIDR’25 paper in our reading group. This paper argues that the rising cost of main memory and lagging improvement in memory bandwidth do not bode well for traditional computing architectures centered around computing devices (i.e., CPUs). As CPUs get more cores, the memory bandwidth…
-
Paper #192. OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck
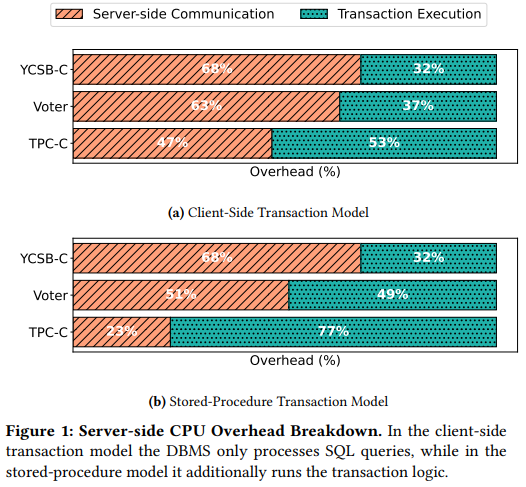
Last week we read “OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck” CIDR’25 paper by Xinjing Zhou, Viktor Leis, Xiangyao Yu, Michael Stonebraker. This paper revisits the original “OLTP Through the Looking Glass, and What We Found There” paper and examines the bottlenecks in modern OLTP databases. The new paper…
-
Paper #191: Occam’s Razor for Distributed Protocols

We have been doing a Zoom distributed systems paper reading group for 5 years and have covered around 190 papers. This semester, we should reach the milestone of 200 papers. Over the years, my commitment to the group has varied — at some point, I was writing paper reviews, and more recently, I’ve had less…
-
Spring 2025 Reading List (Papers ##191-200)

This is a list of papers for the DistSys reading group Spring 2025 term. The schedule is also available on our Google Calendar.
-
Fall 2024 Reading Group Papers (Papers ##181-190)
Without further ado, here is the list:
-
Pile of Eternal Rejections: Revisiting Mencius SMR

Last time, I briefly talked about my pile of eternal rejections. Today, I will describe another paper that has been sitting in that pile for quite some time. It seems like this particular work, done by my student Bocheng Cui, has found its home, though, and by the skin of its teeth, it will appear…
-
System’s Guy Teaching Game Development…
·

This semester, I taught a class that I am extremely unqualified to teach. It was super fun! We are a relatively small university and a small CS department, so offering “fun” classes for our undergraduate students can be challenging, especially if such “fun” courses do not align well with anyone’s research. Despite many students getting…
-
Summer 2024 Reading Group Papers (Papers ##171-180)

This is a list of papers for the DistSys reading group summer term. The schedule is also available on our Google Calendar.
-
Pile of Eternal Rejections: The Cost of Garbage Collection for State Machine Replication
I have a “pile” of papers that continuously get rejected from any conference. All these papers, according to the reviews, “lack novelty,” and therefore are deemed “not interesting” by the reviewing experts. There are some things in common in these papers — they are either observational or rely on old and proven techniques to solve a problem or improve a system/algorithm. Jokingly, I call this set of papers the “pile of…
Search
Recent Posts
- Paper #196. The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling
- Paper #193. Databases in the Era of Memory-Centric Computing
- Paper #192. OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck
- Paper #191: Occam’s Razor for Distributed Protocols
- Spring 2025 Reading List (Papers ##191-200)
Categories
- One Page Summary (10)
- Other Thoughts (10)
- Paper Review and Summary (14)
- Pile of Eternal Rejections (2)
- Playing Around (14)
- Reading Group (103)
- RG Special Session (4)
- Teaching (2)