Event logging or tracing is one of the most common techniques for collecting data about the software execution. For simple application running on the same machine, a trace of events timestamped with the machine’s hardware clock is typically sufficient. When the system grows and becomes distributed over multiple nodes, each node is going to produce its own independent logs or traces. Unfortunately, nodes running on different physical machines do not have access to a single global master clock to timestamp and order the events, making these individual logs unaligned in time.
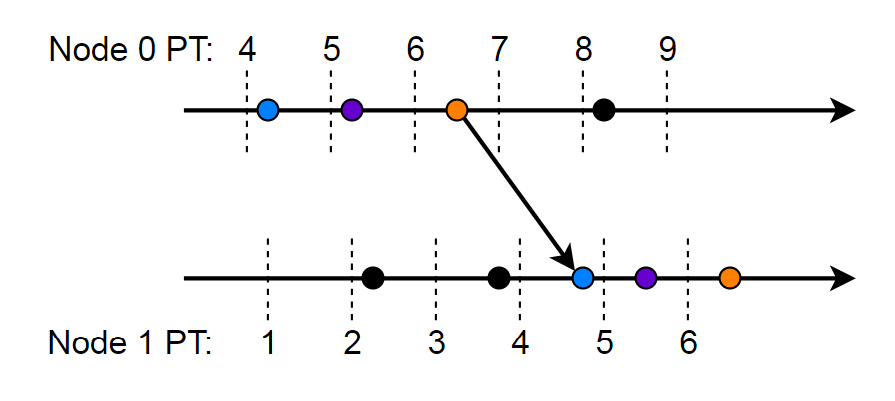
For some purposes, such as debugging, engineers often need to look at these independent logs as one whole. For instance, if Alice the engineer needs need to see how some event on one node influenced the rest of the system, she will need to examine all logs and pay attention to the causal relationships between events. The time skew of different nodes and the trace misalignment caused by such skew prevents Alice from safely relying on such independently produced traces, as shown in the figure below. Instead, she need to collate the logs together and reduce the misalignment as much as possible to produce a more coherent picture of a distributed system execution.
Of course if only the causality was important, Alice could have used Lamport’s logical clocks (LC) to help her identify some causal relationship between the events on different nodes. Alternatively, logging system can also use vector clocks (VC) to capture all of the causal relationships in the system. However, both LC and VC are disjoint from the physical time of the events in the trace, making it hard for Alice to navigate such logging system.
Using synchronized time protocols, such as NTP and PTP will help make the traces better aligned. These protocols are not perfect and still leave out some synchronization error or uncertainty, introducing the possibility of breaking the causality when collating logs purely with them.
HLC sync
Instead of using NTP or logical time for synchronizing the event logs, I thought whether it is possible to use both at the same time with the help of Hybrid Logical Time (HLC). HLC combines a physical time, such as NTP with logical clock to keep track of causality during the period of synchronization uncertainty. Since HLC acts as a single always-increasing time in the entire distributed system, it can be used to timestamp the events in the log traces of every node. You can learn more about HLC here.
Similar to logical time, HLC does not capture full causality between the events. However, HLC conforms to the LC implication: if event A happened before event B, then HLC timestamp of A is smaller than the HLC timestamp of B. This can be written as A hb B ⇒ hlc.A < hlc.B. Obviously, we cannot use HLC timestamps to order any two events. Despite this limitation, we can still use the LC implication to give some partial information about the order of events. If an event A has an HLC timestamp greater than the event B, we can at least say that event B did not happen before A, thus either A happened before B or A is concurrent with B: hlc.A < hlc.B ⇒ A hb B ∨ A co B.
We can use this property to adjust the synchronization between the traces produced at different nodes. Let’s assume we have two nodes with some clock skew. These nodes produce logs that are not fully synchronized in time (we also assume the knowledge of a global, “ideal” time for now). The events in the log happen instantaneously, however we can rely on the machine’s clock to measure the time between events on the same node to give the “rigidity” to the logs. Each node timestamps the log events with its machine’s physical time (PT).
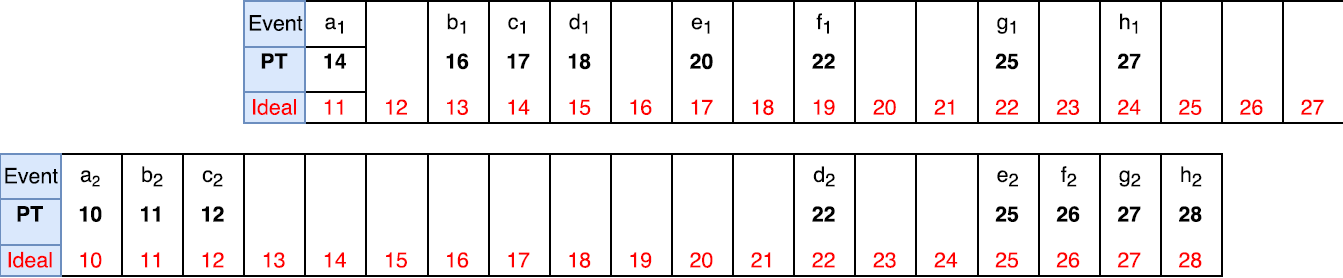
In the figure above, the two logs are not synchronized in the “ideal” time, even though they appear to be in sync based on the PT of each node. Without any additional information we cannot improve on the synchrony of these logs. However, if we replace PT time with HLC, we can achieve better trace synchronization.
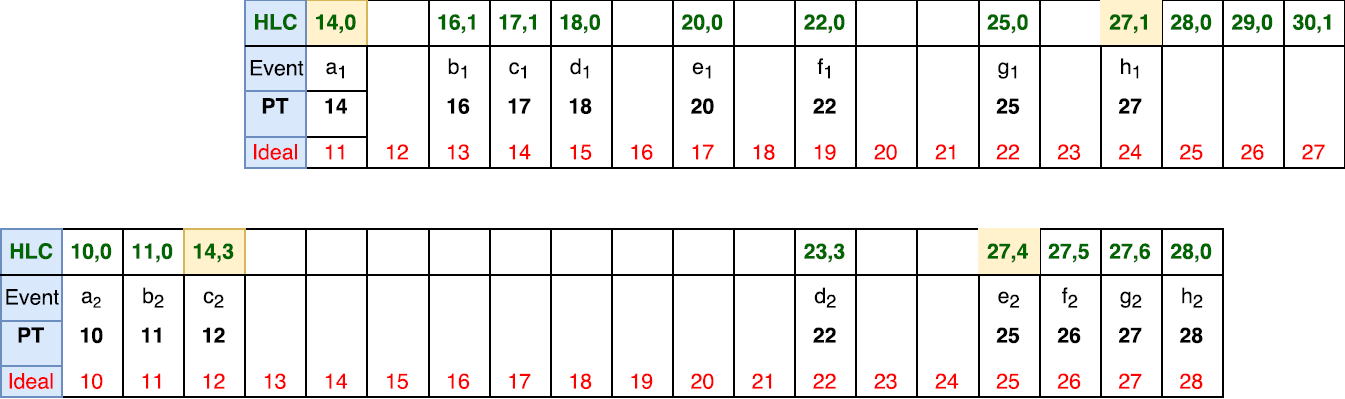
With the addition of HLC time, we may see that when the logs are aligned by the PT only, some HLC timestamps (highlighted in yellow) appear to be out of place. In particular, this alignment does not satisfy the LC condition (A hb B ⇒ hlc.A < hlc.B), since the alignment makes event a1 to appear to happen before c2, however, hlc.c2 > hlc.a1. In order to satisfy the condition, we need to re-sync the logs such that c2 appear concurrent with a1.
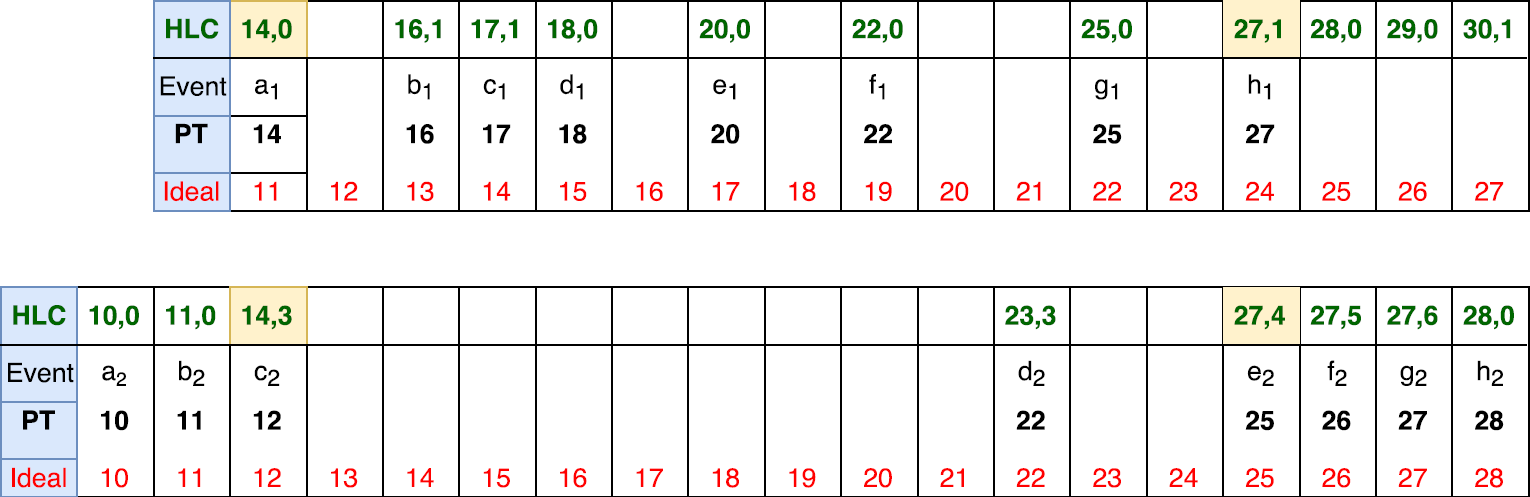
After the adjustment, our synchronization error between two nodes is reduced. Note that we cannot synchronize the logs better and put a1 to happen before c2, since the LC implication simple does not allow us to do so.
The two node synchronization works nice and easy because the LC/HLC implication provides some guarantees about the two events, and we pick these two events from two separate nodes. Aligning more than two logs is more challenging, as we need to perform many comparisons each involving just two events from some two nodes. The number of possible comparison we need to make grows drastically as we increase the number of traces to sync.
However, with HLC we can reduce the problem to just that of performing n-1 2-node log alignments when we need to sync logs from n nodes. HLC operates by learning of higher timestamps from the communication, thus HLC time at all nodes of the cluster tends to follow the PT time of one node with the highest PT clock. Once, again to see this you need to understand how HLC ticks, which is explained here. Having one node that drives the entire HLC in the cluster allows us to synchronize every other log from each node independently with the log of that HLC “driver node”.
Some Testing and Limitation
I set up some synthetic tests to see if HLC can help us achieve any improvement in log synchronization on already loosely synchronized system. The benchmark generates the logs with a number of parameters I can controlled: time skew, communication latency and event probabilities. Maximum time-skew controls the time desynchronization in the simulated cluster measured in time ticks. There will be two nodes in the simulation with maximum time-skew difference between their clocks. Communication latency parameters control the latency of simulated communications in time ticks. Probability of an event parameter controls the chance of an event happening at every time tick; similarly, the probability of communication determines the chance of an outgoing message happening at the time tick.
Since the logs are generated synthetically, I have access to the ideal time synchronization between these logs, allowing me to quantify the alignment error. I calculated the alignment error as 1 – adjustment / skew for every pair of logs.
The figure below shows the error in synchronizing 5 logs as a function of the log length. The Idea is that a longer trace can allow for more opportunities to find the violations in LC/HLC condition and adjust the logs accordingly. All other parameters were kept constant with skew of 50 ticks, communication delay of 3 to 10 ticks, a chance of event as 40% per tick. I made different plots for different probability of inter-node communication. I repeated the simulation 100,000 times and computed the average error.
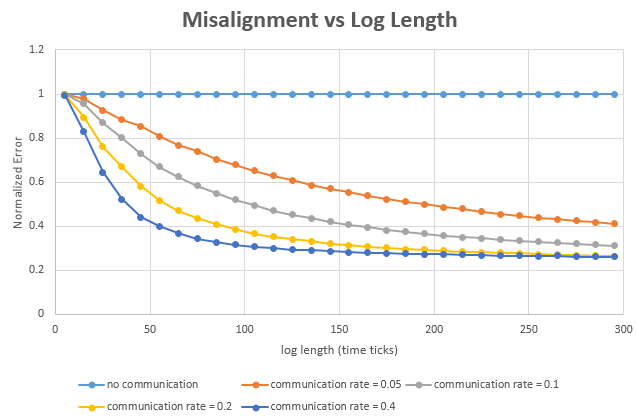
We can see that in this setup the synchronization between logs was significantly improved, and the improvement happens faster when communication if more frequent. This is because communication introduces the causality between nodes, allowing me to exploit it for synchronization. As the logs grow larger the improvements diminish. This is likely due to the reducing closer to the communication delay, at which point HLC synchronization can no longer make improvements.
Inability to achieve any synchronization improvement when the communication latency is equal or greater than the maximum time skew in the system is the most significant limitation of HLC synchronization. The following graph illustrates that:
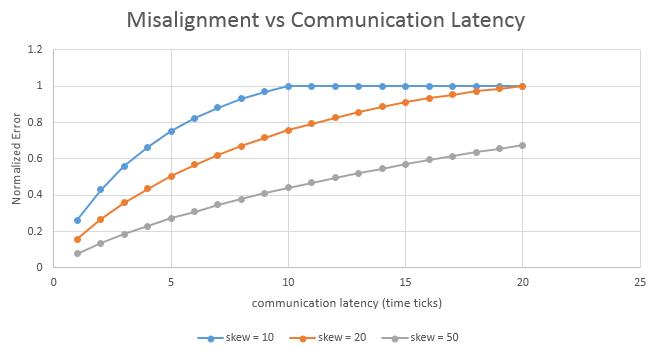
Here I ran the simulation with 3 different skew levels: 10, 20 and 50 ticks. As I increase the communication latency, the error is growing as well, getting to the level of no improvement as the latency reaches the time-skew.
Some Concluding Words
I think this is a rather naïve and simple way to achieve better synchronization for distributed logging software. One can argue that NTP and PTP time synchronization methods are rather good nowadays and that it should be enough for most cases. However, computers are fast now and even in 1 ms of desynchronization many computations can be made. Even a few full round trips of network message exchange can happen in that 1 ms in good Local Area Networks.
HLC synchronization’s simplicity allows it to be implemented purely in user-level application code. There is no need to constantly run NTP protocol to keep tight time synchrony, there is no need to access or modify any of the underlying system-level code beyond just reading the clock, there is no need to access high precision clock that may slow the application down.
HLC can also be used within a single machine to synchronize on traces from different threads. Despite having access to the same clock at all threads and processes, the clock granularity may still be coarse enough to do many computations within a single tick.
HLC sync is not without the limits. Its usefulness degrades as the synchronization gets closer to the communication latency, but it can still be used as a fail-safe mechanism in cases NTP fails.
Alternatively to synchronizing logs, HLC can be used to find consistent global states and search through the distributed application’s past execution.