data center
-
Reading Group #153. Deep Note: Can Acoustic Interference Damage the Availability of Hard Disk Storage in Underwater Data Centers?

For the 153rd reading group paper, we read something very different this time: “Deep Note: Can Acoustic Interference Damage the Availability of Hard Disk Storage in Underwater Data Centers?” This HotStorage short paper explores the possibility of using soundwaves to attack underwater data centers. In particular, the paper shows how magnetic disks can be disrupted…
-
Reading Group Paper: Hyrax: Fail-in-Place Server Operation in Cloud Platforms
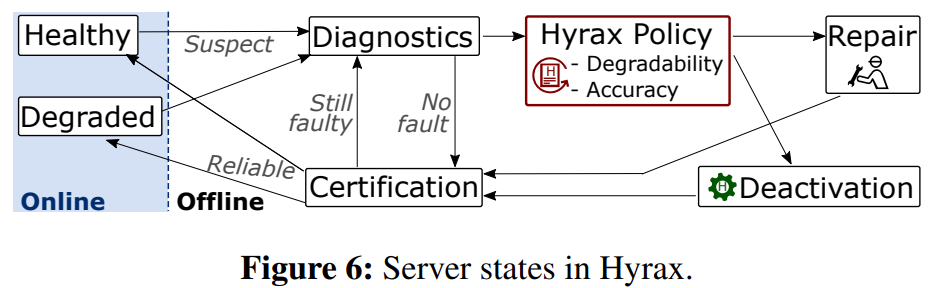
In the 142nd reading group meeting, we discussed “Hyrax: Fail-in-Place Server Operation in Cloud Platforms” OSDI’23 paper. Hyrax allows servers with certain types of hardware failures to return to service after some software-only automated mitigation steps. Traditionally, when a server malfunctions, the VMs are migrated off of it, then the server gets shut down and…
-
Reading Group. Running BGP in Data Centers at Scale
Our 82nd reading group paper was “Running BGP in Data Centers at Scale.” This paper describes how Facebook adopted the BGP protocol, normally used at the Internet-scale, to provide routing capabilities at their datacenters. They are not the first to run BGP in the data center, but the paper is interesting nevertheless at giving some…
Search
Recent Posts
- Paper #196. The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling
- Paper #193. Databases in the Era of Memory-Centric Computing
- Paper #192. OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck
- Paper #191: Occam’s Razor for Distributed Protocols
- Spring 2025 Reading List (Papers ##191-200)
Categories
- One Page Summary (10)
- Other Thoughts (10)
- Paper Review and Summary (14)
- Pile of Eternal Rejections (2)
- Playing Around (14)
- Reading Group (103)
- RG Special Session (4)
- Teaching (2)