ZooKeeper is a popular coordination service used as part of many large scale distributed systems. ZooKeeper provides a file-system inspired abstraction to the users on top of its replicated key-value store. Like other Paxos-inspired protocols, ZooKeeper is typically deployed on at least 3 nodes, and can tolerate F node failure for a cluster of size 2F+1. One characteristic of ZooKeeper is that it runs the consensus algorithm for update operations, however to speed things up reads may be served locally by the replica a client connects to. This means that a value read from a replica may be stale or outdated compared to the leader nodes or even other followers. This makes it a user’s problem to tolerate the stale data read from ZooKeeper, or perform sync operation to get up-to-date with the leader before reading.
But how stale can data become in a ZooKeeper cluster? This is a rather tricky question to answer, since each replica runs on a separate machine with different clock. We cannot just observe the time a value become available at each node, because these timestamp are not comparable due to clock skew. Instead of trying to figure out the staleness time, I decided to look at how many versions behind can a replica be. I used my Retroscope tool to keep track of when the data becomes available to the client at each replica. I used Retroscope Query Language (RQL) to collect the data from nodes and look at the consistent cuts progressing through the states of ZooKeeper. Retroscoping ZooKeeper took only about 30 lines of code to be added to the project.
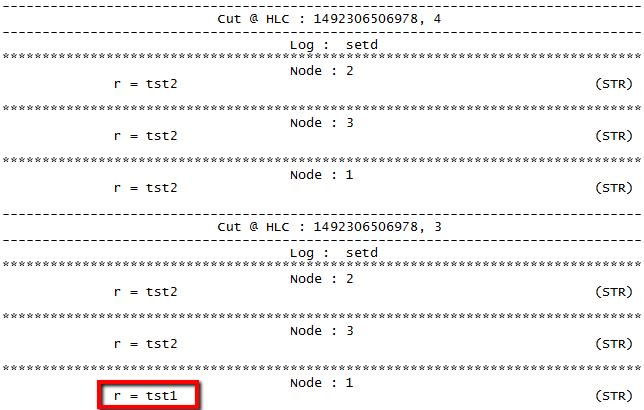
I deployed a small ZooKeeper cluster on 3 AWS t2.micro instances (I know, it is far from production setup, but it works well for a quick test). On a separate instance I deployed RQL server. To start, I simply created one znode and updated its value. I then proceeded with running the simplest possible RQL query: SELECT retro FROM setd; in this query, retro corresponds to /retro znode I’ve created, and setd is the name of the Retroscope log I put my monitoring data into. The result of the query was exactly what I have expected: at one of the consistent cuts one of the nodes had a value one version behind. This is entirely normal behavior, as the value needs to propagate from the leader to the followers once decided.
My next move was to give a bit more work to the ZooKeeper in a short burst, so I quickly wrote a small program that puts some incremental values to n znodes for a total of r writes. It starts with a value tst1, then goes to tst2 and so on for every znode. At first I restricted n=1, as I felt that writing to just one znode to create a “hot-spot” was going to give me the best chance of getting stale values. But ZooKeeper handled the burst of 100 writes easily, with the results being identical to a single write: stale value was at most 1 version behind the current data.
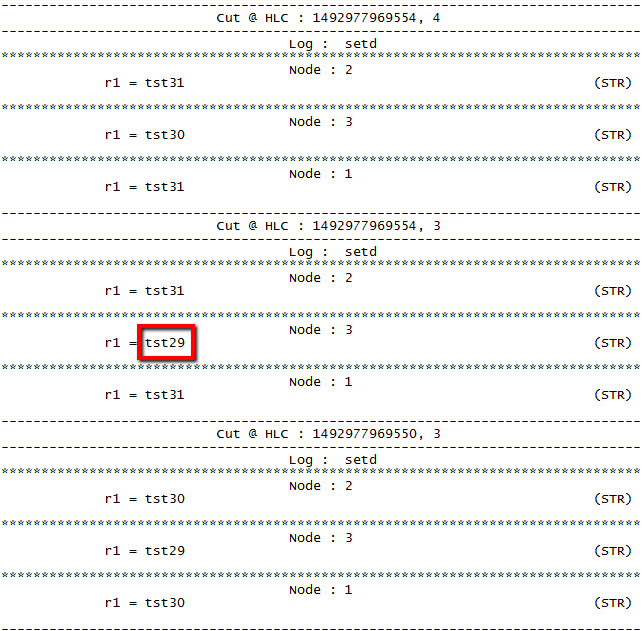
Seeing things work well was not interesting for me, so I decided to no longer play fair. I artificially made one replica to work slower and be a struggler node. ZooKeeper protocol tolerates this just fine, as it needs 2 out of 3 nodes in my cluster to form the majority quorum and make progress. For this crippled ZooKeeper setup I re-ran the workload and my simple query. Needless to say, I was able to spot one time a system had a node with a znode 2 versions behind, and it was my struggler machine. In the next step I increased the load on the cluster and made the workload write 1000 values to the same znode. I also changed the query so that I do not have to manually look through thousands of consistent cuts trying to spot the stale data. My new query emits consistent cuts with staleness of 2 or more versions:
SELECT r1 FROM setd WHEN Int(StrReplace(r1, “tst”, “”)) – Int(StrReplace(r1, “tst”, “”)) > 1;
The interesting thing about the query above is that it uses the same variable name twice in the expression, essentially telling RQL to output a cut when r1 – r1 > 1. However, there are are many r1‘s in the system (3 in fact, one at each node), so when a pair of r1‘s that satisfy WHEN condition is found (at different nodes), RQL will output the consistent cut.
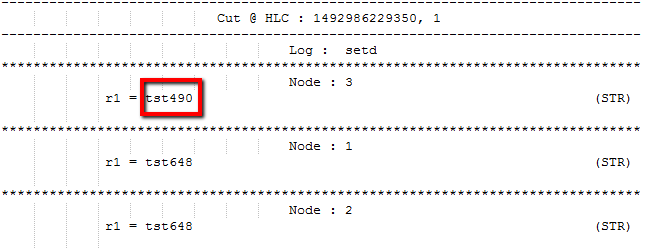
I was a bit surprised by the results. At first the struggler managed to keep-up with the rest of the cluster quite well, slipping 2 version behind on occasion, but after about 200 requests things went out of control for the crippled node, with the staleness growing to be 158 version behind towards the end of the run. Of course a struggler node will make things look worse, but it is not an unrealistic scenario to have underperforming machines. My test however is not fair either, as I was using a 100% write workload targeting just one znode. So In the next try I changed the workload to target 100 different znodes, while still measuring the staleness on just one znode. In that experiment, the staleness was not that high, but the number of updates to a single znode was only a small fraction of the previous test. Nevertheless, struggler replica was as much as 6 version stale, making it roughly 1/3rd of updates behind the rest of the cluster.
For the last quick test, I tried doing a large burst of 2000 writes to the same znode on a healthy cluster with no struggler nodes. Despite all replicas working at their proper speed, I was able to observe staleness of 3 versions on some occasions.
I am not sure about the lessons learned from this quick experiment. I was amazed by how easy it is to get ZooKeeper to have data 2 or more versions behind, although the system seems fast to catch up. Struggler scenario, however, illustrated how quickly things can get out of control with just some performance degradation at one of the replicas. Engineers using ZooKeeper must build their applications in such a way to tolerate the stale ZooKeeper values gracefully.