The 97th paper in the reading group was “Shard Manager: A Generic Shard Management Framework for Geo-distributed Applications.” This paper from Facebook talks about a sharding framework used in many of Facebook’s internal systems and applications.
Sharding is a standard way to provide horizontal scalability — systems can break down their data into (semi-) independent chunks and store and process operations on these data chunks on different servers. There are many complex questions about this seemingly simple concept. For instance, how do we split the data or keyspace into good chunks? And once we know how to partition the keyspace, where do we store the shards and perform compute tasks on them? How do applications find the right partitions for their data?
Despite the widespread use, many large systems handle sharding in an ad-hoc manner, implementing everything they need from scratch. Obviously, reinventing the bicycle each time can be problematic when you run a big company with hundreds of distributed sharded systems and applications. Shard Manager is Facebook’s solution to the sharding problem that aims to be general enough to be reused by many internal systems. It is a comprehensive framework that can decide how to split the data/keyspace (apps can override this and have their own sharding rules), where to place the resulting shards (app specify rules or constraints to guide the placement), and how to find them.
Shard Manager aims to be general and accommodate many workloads and deployment patterns observed at Facebook. The paper states that currently, 54% of all sharded applications at Facebook use the framework. Unlike other sharding frameworks that are constrained to a single data center or region, Shard Manager works across regional boundaries. In a traditional sharding framework, if an application needs a copy of a partition in a different region, it must orchestrate this copy’s placement in the regional instance of the sharding platform. This is a problem for availability, scalability, fault-tolerance, and cost, as components managing the shard placement and migration, are separated between different systems. With Shard Manager, the shard’s placement is not confined to a single region, and copies can move between the geographical regions, all controlled by one system. Speaking of shard copies, Shard Manager assumes replicated shards and also allows for a “special” primary shard to facilitate leader-based replication approaches.

Of course, all shard placements and movements are constrained based on the application requirements and load balancing needs. The applications set the constraints, some of which are hard and cannot be violated, and some are more like a wish list — good to have but not strictly necessary. The hard constraints ensure the minimum requirement for shard placement, such as the server capacity needed for a shard. Examples of soft constraints or goals are preferred geographical location, the spread of replicas across failure domains, and various load balancing requirements.
To make everything tick, Shard Manager consists of multiple components. The orchestrator component is a monitor for health and resource usage; it makes the decisions to change the placement of shards whenever needed. The allocator component creates new shard-to-server assignments. Allocator also receives input from Twine, Facebook’s cluster manager. This connection allows the orchestrator to make decisions based on planned or anticipated events known to Twine, such as servers shutting down or rebooting for maintenance. Apparently, this is a big deal, as it allows applications to gracefully handle infrastructure maintenance. The paper spends quite some time talking about graceful shard migration, especially for cases when a primary copy of a shard needs to move to a different server.
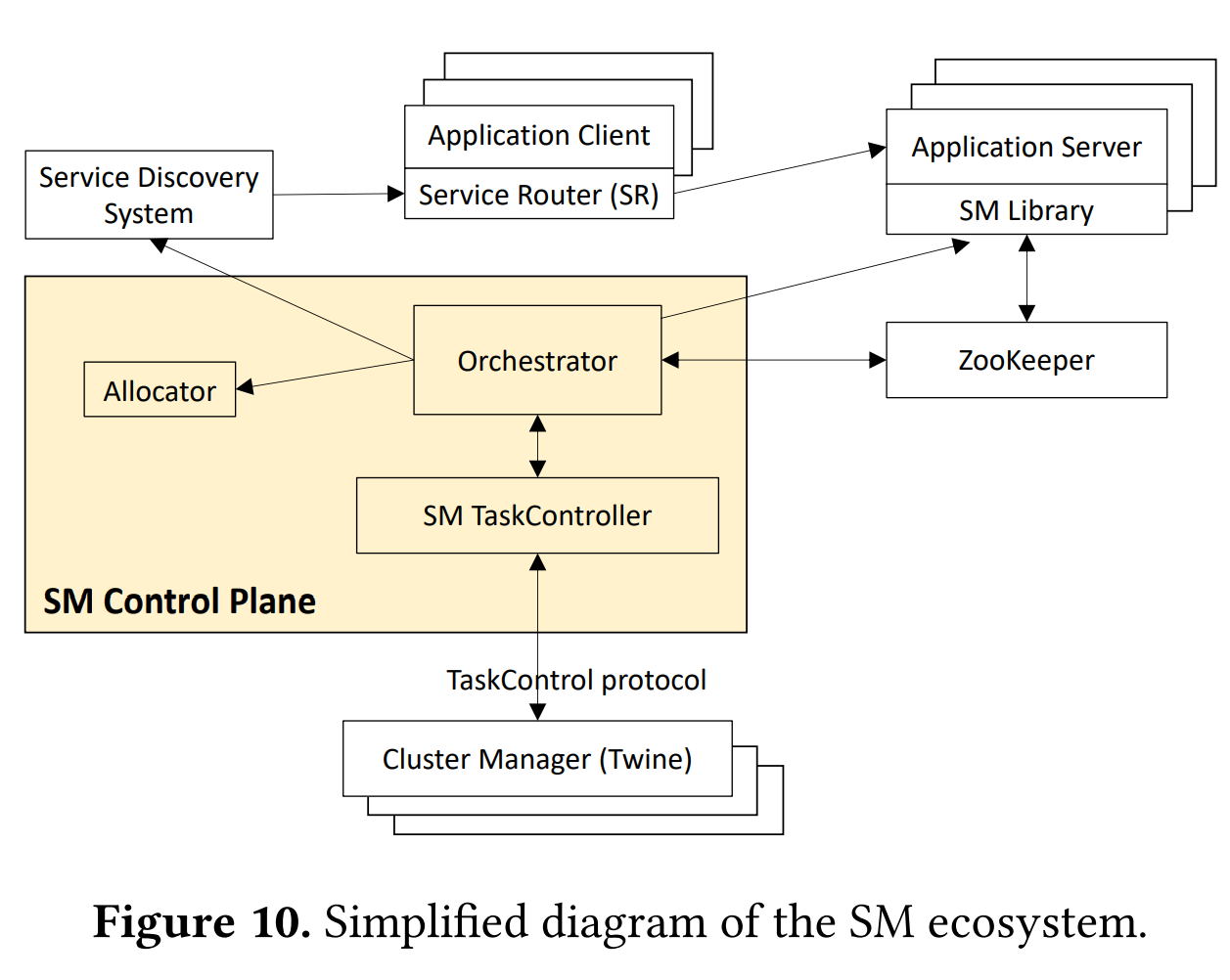
Finally, the ZooKeeper stores all the important stuff, such as the orchestrator’s state and shard assignments. ZooKeeper also acts as a failure detector for application nodes. On the application side, servers used Shard Manager (SM) Library to interact with the orchestrator and ZooKeeper. Application clients, on the other hand, interact with Service Discovery to find the required shards. We recently covered the Delos paper that talks about building control plane storage for Facebook to replace ZooKeeper, so it is likely that the actual ZooKeeper has been replaced with a Delos-based system.
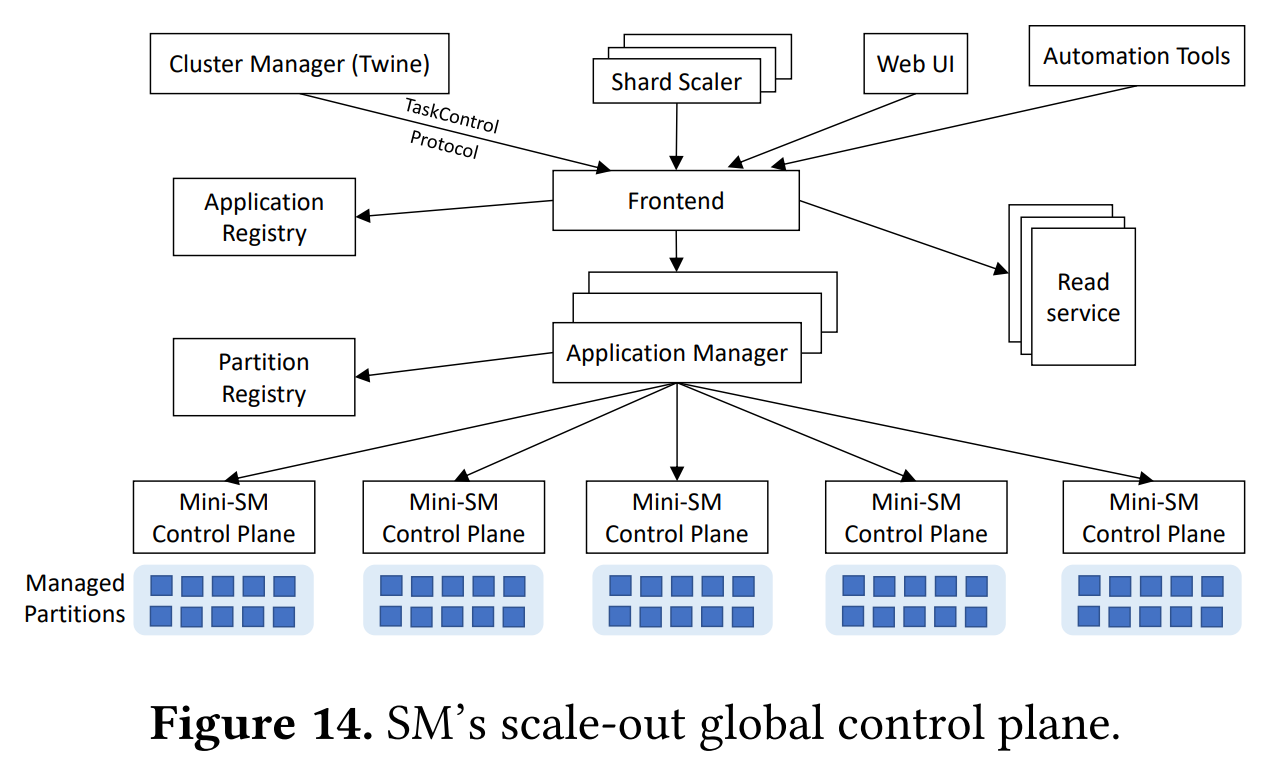
The scale of Facebook’s operation demands the Shard Manager to be sharded itself. The system is composed of many Mini Shard Managers (Mini-SMs). Each Mini-SM handles multiple partitions, and each partition represents a slice of servers available to some application across many regions.
Reading Group
Our reading group takes place over Zoom every Wednesday at 2:00 pm EST. We have a slack group where we post papers, hold discussions, and most importantly manage Zoom invites to paper discussions. Please join the slack group to get involved!