Our 79th paper was “Scaling Large Production Clusters with Partitioned Synchronization.” ATC’21 paper by Yihui Feng, Zhi Liu, Yunjian Zhao, Tatiana Jin, Yidi Wu, Yang Zhang, James Cheng, Chao Li, Tao Guan. This time around, I will not summarize the paper much since A. Jesse Jiryu Davis, who presented the paper, has written a very good summary.
The core idea of this paper is to scale the task schedulers in large clusters. Things are simple when one server performs all the scheduling and maps the tasks to servers. This server always knows the current state of the cluster and the load on each worker. The problem, of course, is that this approach does not scale, as a single scheduling server is an obvious bottleneck. A natural solution is to increase the number of schedulers, but this introduces new problems — to gain benefit from parallel schedulers, these schedulers cannot synchronize every single operation they perform. So, schedulers inherently operate on stale (and different) views of the cluster and, for example, may accidentally assign tasks to workers that are at capacity. The longer the schedulers work independently without synchronizing, the more divergent their cluster views become, and the greater number of mistaken or conflicting assignments they perform. The conflicts due to stale cluster views (i.e., two schedulers assigning two different tasks for the same worker slots) mean that at least one of these assignments has to retry for another worker/slot. As a result, we must have some balance between staleness and synchrony.
Typically, the schedulers would synchronize/learn the entire cluster view in a “one-shot” approach. A master scheduler aggregates the cluster views of all the schedulers and distributes the full aggregated cluster view back. This full “one-shot” synchronization is an expensive process, especially for large clusters, and it again puts the master into a bottleneck position. So, the system can perform this sync only so often. The paper proposes a partitioned synchronization or ParSync, as opposed to “one-shot” full synchronization. The partitioned approach takes the full cluster view and breaks it down into chunks, synchronizing one chunk at a time in a round-robin manner. The complete sync cycle occurs when the synchronization has rotated through all chunks or partitions. Both one-shot and ParSync approaches provide the same average staleness if both operate on the same full sync interval G. The difference is that the “one-shot” approach synchronizes every G time-units, while ParSync updates some partition every G/N time-units, for a system with N partitions. The partitioned synchronization has the effect of bringing the variance of staleness down. From the author’s experiments, they conjecture that most scheduling conflicts occur when staleness is high. As a result, bringing down the maximum staleness in the system brings the most benefit. The paper provides a detailed explanation of these findings, while Jesse, in his blog and presentation, gives an excellent visual example of this.
Another thing that I oversimplified is scheduling itself. See, it is not enough to know that some worker server has some capacity to be used for some task. In the real world, the workers have different speeds or other properties that make some workers preferred to others. The paper tries to capture this worker’s non-uniformity through the quality metric and suggests that a good scheduling mechanism needs to find not just any worker fast but a good quality worker fast. Moreover, the contention for quality workers is one source of scheduling delays.
The paper provides a much greater discussion on both the ParSync approach, and other scheduler architectures, so it is worth checking out,
Discussion
1) Quality. A good chunk of our discussion centered around the quality metric used in the paper to schedule tasks. ParSync has an approach to prioritize quality scheduling when staleness is OK and reduce quality when it becomes too expensive to ensure quality due to conflicts for high-quality slots. The paper treats the quality as a single uniform score common to all tasks scheduled in the system. This uniform quality score approach is not very realistic in large systems. Different tasks may have varying requirements for hardware, locality to other tasks, and locality to caches among many other things.
Having quality as a function of a task complicates things a bit from the simplified model. For instance, if a particular set of tasks prefers some set of worker nodes, and all these workers belong to the same partition, then, effectively, we degraded the scheduling to a “one-shot” synchronization approach for that specific set of tasks. So partitioning becomes a more complicated problem, and we need to ensure that each partition has a uniform distribution of quality workers for each set of similar tasks.
2) Number of Partitions. Another issue we discussed deals with the number of partitions. The main paper does not explore the impact of the number of partitions on performance and scheduling quality. The paper, however, mentions that the results are available in the extended report. In summary, the number of partitions has little effect on performance. This is a bit counter-intuitive since the claim of the paper is that partitioned state sync improves scheduling. The math on reducing max staleness in the cluster shows diminishing returns as the number of partitions grows to explain these results.
3) Evaluations. The paper presents two strategies for scheduling — quality-first and latency-first. In quality-first, schedulers try to assign tasks to the highest quality slots first. As schedulers’ views become staler, they start to conflict more often and try to assign tasks to quality slots that have already been taken. Interestingly enough, the quality-first strategy, while producing on average higher-quality assignments, has more quality variance than the latency-first strategy that optimizes for the scheduling speed. The quality variance of adaptive policy that can switch between the quality and latency mode is even worse for some reason.
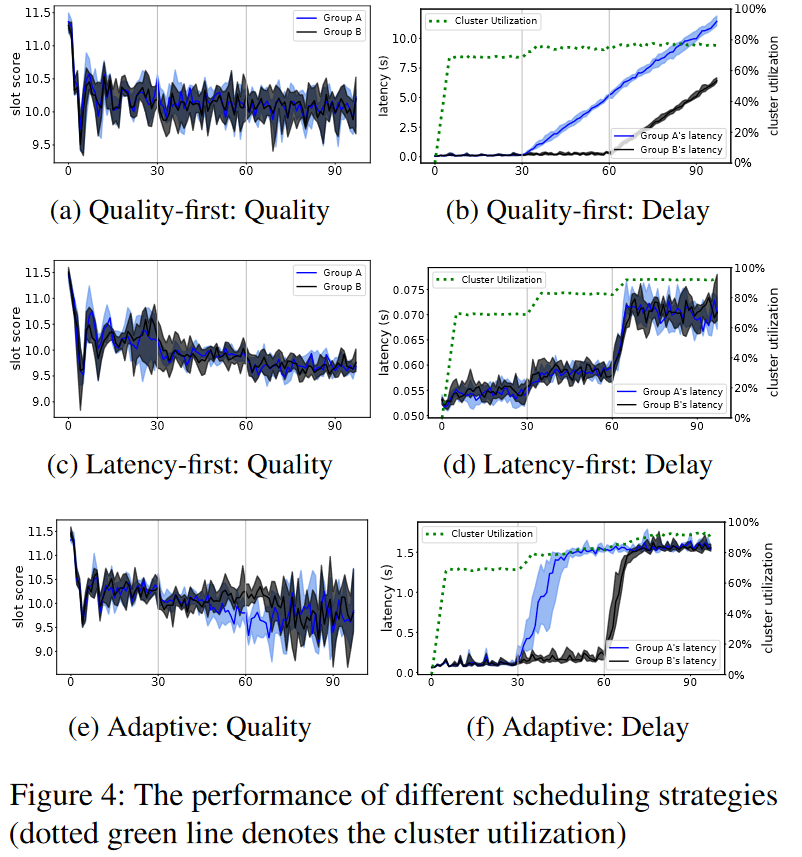
We again feel that the evaluation in the paper does not do justice to quality assignments. Having quality as a function of a task may reduce contention since not all tasks will compete for the same slots anymore.
4) Relation to ML Systems. It was also mentioned in the discussion that ML systems have been using similar partitioned synchronization tricks to control the staleness of the models.