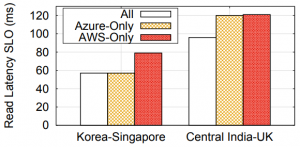
This paper appeared in SOCC 2018, but caught my Paxos attention only recently. The premise of the paper is to provide strong consistency in a heterogeneous storage system spanning multiple cloud providers and storage platforms. Going across cloud providers is challenging, since storage services at different clouds cannot directly talk to each other and replicate the data with strong consistency. The benefits of spanning multiple clouds, however, may worth the hustle, since a heterogeneous system will be both better protected from cloud provider outages, and provide better performance by placing the data closer to the users. The latter aspect is emphasized in the paper, and as seen in the figure, going multi-cloud can reduce latency by up to ~25%.
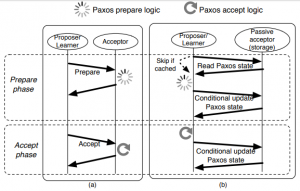
To solve the issue of consistent cross-cloud replication, authors propose to use Cloud Paxos (CPaxos), a Paxos variant designed to work with followers supporting a very minimal and common set of operations: get and conditional put. In CPaxos, clients act as prospers, and storage systems serve the role of the followers. The followers are not really “smart” in this protocol, and most of the Paxos logic shifts to the client-proposers (Figure 2).
The prepare phase in CPaxos simply gathers the state from the followers, making the proposer decide for itself whether the followers would have accepted it with the current ballot or not. If the proposer thinks it would have been accepted, it will try updating the followers’ state. Doing this, however, requires some precautions from the followers, since their state may have changed after the proposer made a decision to proceed. For that matter, CPaxos uses conditional put (or compare-and-set) operation, making the followers update their state only if it has not changed since it was read by the proposer. This ensures that at most one proposer can succeed with changing the state of the majority of followers.
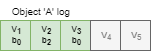
I visualize this as a log to represent changes in some object’s state. The new version of an object corresponds to a new slot in the log, while each slot can be tried with different ballot by different proposers. The put operation succeeds at the follower only if the value at the slot and a ballot has not been written by some other proposer. In case a proposer does not get a majority of successful updates, it needs to start from the beginning: increase its ballot, perform a read and make a decision whether to proceed with state update. Upon reaching the majority acks on state update, the proposer sends a message to flip the commit bit to make sure each follower knows the global state of the operation.
This basic protocol has quite a few problems with performance. Latency is large, since at least 2 round-trips are required to reach consensus, since every proposer needs to run 2 phases (+ send a commit message). Additionally, increasing the number of proposers acting on the same objects will lead to the growth in conflict, requiring repeated restarts and further increasing latency. CPaxos mitigates these problems to a degree. For example, it tries to commit values on the fast path by avoiding the prepare phase entirely and starting an accept phase on what it believes will be next version of an object with ballot #0. If the proposer’s knowledge of the object’s state (version, ballot) is outdated, the conditional put will fail and the proposer will try again, but this time with full two phases to learn the correct state first. However, if the proposer is lucky, an update can go in just one round-trip. This optimization, of course, works only when an object is rarely updated concurrently by multiple proposers; otherwise dueling leaders become a problem not only for progress, but for safety as well, since two proposers may write different values for the same version using the same ballot. This creates a bit of a conundrum on when the value becomes safely anchored and won’t ever get lost.
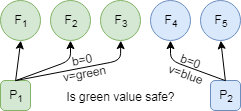
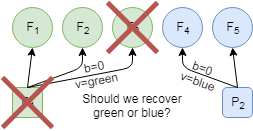
Consider an example in which two proposers write different values: green and blue to the same version using ballot #0 (Figure 4 on the left). One of the proposers is able to write to the majority, before it becomes unresponsive. At the same time, one green follower crashes as well, leading to a situation with two followers having green value and two being blue (Figure 5 on the right). The remaining proposer has no knowledge of whether the green or blue value needs to be recovered (remember, they are both on the same ballot in the same slot/version!). To avoid this situation, CPaxos expands the fast path commit quorum from majority to a supermajority, namely \(\left \lceil{\frac{3f}{2}}\right \rceil +1\) followers, where \(2f+1\) is the total number of followers, and f is the tolerated number of follower failures, allowing the anchored/committed value to be in a majority of any majority of followers ![]() . Having this creates an interesting misbalance in fault tolerance: while CPaxos still tolerates \(f[\latex] node failures and can make progress by degrading to full 2 phases of the protocol, it can lose an uncommitted value even if it was accepted by the majority when up to [latex]f\) followers fail.
. Having this creates an interesting misbalance in fault tolerance: while CPaxos still tolerates \(f[\latex] node failures and can make progress by degrading to full 2 phases of the protocol, it can lose an uncommitted value even if it was accepted by the majority when up to [latex]f\) followers fail.
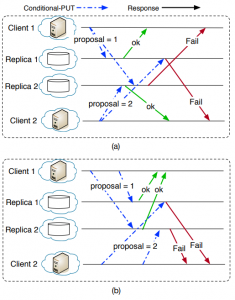
Proposer conflicts are a big problem for CPaxos, so naturally the protocol tries to mitigate it. The approach taken here reduces the duration in which possible conflicts may occur. As CPaxos is deployed over many datacenters, the latencies between datacenters are not likely to be uniform. This means, that a prepare or accept messages from some proposer reach different datacenters at different times, creating an inconsistent state. When two proposers operate concurrently, they are more likely so observe this inconsistency: as both proposers quickly update their neighboring datacenters, they run the risk of not reaching the required supermajority due to the conflicting state (Figure 6(a)) created by some messages being not as quick to reach remaining datacenters. To avoid rejecting both proposers, CPaxos schedules sending messages in a way to deliver them to all datacenters at roughly the same time. This reduces the duration of inconsistent state, allowing to order some concurrent operations (Figure 6(b)).
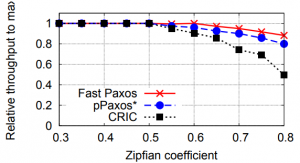
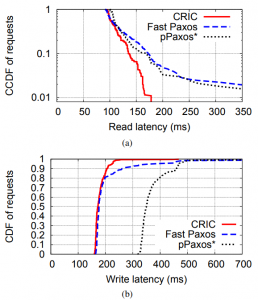
Despite the above mitigation strategy, conflicts still affect CPaxos greatly. The authors are rather open about this, and show their system CRIC with CPaxos degrading quicker than Paxos and Fast Paxos as the conflict rate increases. However, in the low conflict scenario, which authors argue is more likely in real world applications, CRIC and CPaxos improve on performance compared to Paxos/Fast Paxos, especially for reading the data. This is because reads in CPaxos are carried out in one round-trip-time (RTT) by client-proposer contacting all followers and waiting for at least a majority of them to reply. If the client sees the latest version with a commit flag set in the majority, it can return the data. Otherwise, it will wait to hear from more followers and use their logs to determine the safe value to return. In some rare cases when the proposer cannot determine the latest safe value, it will perform the recovery by running the write path of CPaxos with the value to recover (highest ballot value or highest frequency value if more than one value share the ballot).
Some Thoughts
- The motivation of the paper was to make strongly consistent system spanning multiple clouds providers and storage systems for the benefit of improved latency though leveraging the location of datacenters of these different providers. However, CRIC and CPaxos protocol requires a lot of communication, even on the read path. During reads, a client-proposer contacts all CPaxos nodes, located at all datacenters, and in best case still needs the majority replies. As such the latency benefit here comes from trying to get not just one node closer to the client, but a majority of nodes. This may be difficult to achieve in large systems spanning many datacenters. I think sharding the system and placing it on subset of nodes based on access locality can benefit here greatly. For instance, Facebook’s Akkio paper claims to have significant reduction in traffic and storage by having fewer replicas and making data follow access patterns. In our recent paper, we have also illustrated a few very simple data migration policies and possible latency improvement from implementing these policies.
- One RTT reads in “happy path” can be implemented on top of regular MutliPaxos without contacting all nodes in the systems. Reading from the majority of followers is good enough for this most of the time, while in rare circumstances the reader may need to retry the read from any one node. More on this will be in our upcoming HotStorage ’19 paper.
- The optimization to delay message sending in order to deliver messages at roughly the same time to all nodes can help with conflict reduction in other protocols that suffer from this problem. EPaxos comes to mind right away, as it is affected by the “dueling leaders” problem as well. Actually, CPaxos and EPaxos are rather similar. Both assume low conflict rate to have single round trip “happy path” writes and reads. When the assumption breaks, and there is a conflict, both switch to two phases. EPaxos is better here in a sense that the first opportunistic phase is not totally wasted and can be used as phase-1 in the two phase mode, whereas CPaxos has to start all the way from the beginning due to the API limitation on the follower side.