Facebook operates a huge infrastructure that needs to be constantly monitored for performance and stability. Such monitoring collects huge amounts of data that must be easily accessible to various diagnosis and anomaly detection tools in order to quickly identify and react to possible issues. Many of such parameters can be represented as real-valued time series. For example, server CPU utilization can be thought of as one of such time series: it can be sampled at some time interval and represented as a numeric value. In order to accommodate all the time series data for various parameter produced by all the server, Facebook needs a scalable, robust and fast way to store and manage time series.
Gorilla: A Fast, Scalable, In-Memory Time Series Database paper describes Facebook’s approach to the problem of managing large amounts of time series. After reading the first page of this paper, I started to ask myself whether Gorilla is truly a time series database or if it is a monitoring data cache for Facebook. To understand what is Gorilla, we must look at what data Gorilla stores and how it was designed and implemented.
Facebook’s monitoring tasks set a strict set of requirements a time series database needs to meet, which I briefly summarize in the list below:
- Store real-valued monitoring data
- Have fast access to 26 hours of monitoring data
- Be scalable on Facebook scale, as the amount of data increases all the time
- Maintain millions of time series
- Fast retrieval of time series with reads in under 1 ms
- Support up to 40,000 queries per second
- Low granularity time series with resolution of up to 4 data point per second.
- Replicated design for disaster recovery.
Gorilla Data Model
Gorilla is said to store time series data in which every data point consists of a timestamp and a single 64-bit value. This places the limitation on what kind of time series can be stored. For one, timestamp requirement makes it more difficult to deal with ordinal time series in which only the order of events matters and not the duration between them (sure, we can assign always increasing integers for timestamp to represent the order). Another limitation is inability to store multi-dimensional time series, where a single data point consists of a vector rather than a single value.
Physical time of the event is important for Facebook’s usage case of Gorilla, as the engineers need to know the time when an event or anomaly happened. Facebook engineers also do not care about recording vectors of data for each point in time, as they can record multiple values into different time series, which allows them to improve memory utilization of the system at the expense of versatility. This makes Gorilla very specialized tool from the standpoint of data it can handle, as the data-model is dictated by the overall requirement for monitoring task on Facebook scale.
Gorilla Design and Implementation
Obviously, Gorilla was designed and built to meet the requirements outlined earlier. Similar to how data model was derived to achieve the requirements, the rest of the system also sacrifices the generalizability for the sake of meeting the monitoring goals. Below I try to look at various portions of the system and see how universal or flexible the design of Gorilla is.
Compressed In-Memory Storage
Requiring the time series retrieval in under 1 ms means that data needs to reside in memory of the machines composing the Gorilla deployment. This time requirement most likely also imposes the limitation of only 4 point/second, as the system needs to keep individual the time series small enough to be able to retrieve them in entirety quickly enough. The 26 hours of data is needed for monitoring tasks at Facebook, meaning that a single time series will not exceed the size of 6240 points.
Despite the small size of individual time series, Facebook generates millions of such time series, so the memory consumption of the entire cluster is very high. Some very clever algorithms are used to compact each time series individually. Gorilla compresses both the timestamps and values for each data point.
The timestamp compression uses a delta-of-delta technique. The compression starts by finding a difference Δtn-1,n between the new timestamp tn and a previous timestamp tn-1: Δtn-1,n = tn – tn-1. This difference can already be represented with less bits then the original timestamp. However, the time series used in the monitoring at Facebook tend to happen at regular intervals, allowing even greater compression by finding the difference D between delta’s instead of differences between events. In other words, system does not code the changes in timestamps of the events as it would do with a single delta, but it uses the differences between the intervals between the events: D = Δtn, n-1 – Δtn-1, n-2. If everything operates correctly, most events happen at regular, constant intervals, resulting in 0 difference between them. This 0 difference can be encoded with just one bit of ‘0’. However, when some irregularity happens, the difference between intervals can still be represented with just a few bits. Computing the delta-of-deltas is shown in the example below:
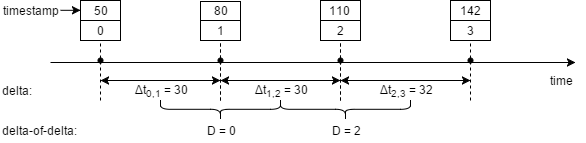
The binary representation for D also plays a crucial role in compression and must be tweaked based on the application and the frequency of point in the time series. In Facebook’s monitoring case if delta-of-deltas D is between [-63, 64], it is encoded with ‘10’ followed by 7 bits of difference value for a total size of 9 bits; if D is between [-255, 256], value D is prepended with ‘110’ bits, resulting in a total size of 12 bits, this patterns continues to cover larger D values.
Data compression is achieved through comparing two values and finding a substring of bits that changed from one point to the next one. Since the system looks for only one such substring, it can encode the offset if such substring from the beginning of the 64-bit value, and the actual substring containing the changes, thus eliminating the need to store the prefix and suffix to the changed substring, as these bits can be taken from previous value.
This compression scheme favors the scenarios in which the value stays constant from one point to another, as constant value can be represented with just one bit. This is extremely useful for Facebook monitoring in which many of the values stay constant or show small changes that can be efficiently compressed. Combined with time stamp compression, Gorilla shows remarkable reduction in the average size of a data point:
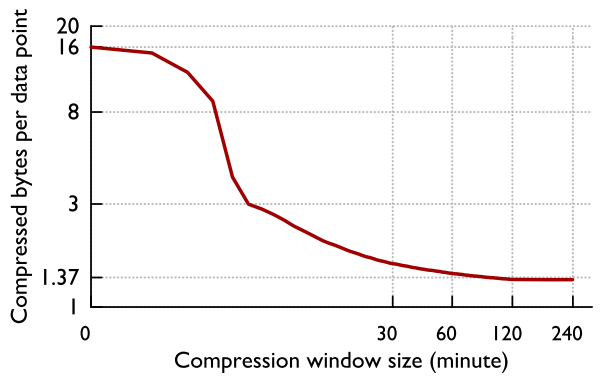
This performance is however not universal and will not scale well to other time series outside of the Facebook monitoring use case. In both timestamp and value compression, in order to read a data point, system needs to read its predecessor, this requires the compression to run in non-overlapping windows and reset itself after some time interval. Having windows too large will require more compute resources to read the data point.
The timestamp compression struggles from a number of shortcoming. It operates on a second level resolution which allows to ignore small millisecond level variations and still encode the points with such variations as having no difference in the intervals. This works well for when we can record a maximum of 4 points in one minute, however many application, such as music, audio, or sensors produce data at much faster rate, requiring a more precise timestamp resolution on a millisecond or even nanosecond scale and not on a second scale. Requiring more precision from timestamps will undermining the benefits that can be achieved with timestamp compression. Additionally, if the intervals between the time series are not constant or nearly constant and tend to change frequently, the efficiency of compression will also dramatically degrade.
The value compression cannot handle vector time series without making it more complicated and requiring constant size vectors. It also works best when the values do not change by much. Great changes on values may lead to no compression between two points at all.
Storage Model
Gorilla is a sharded system that assigns each server to handle a subset of the time series currently stored in the system. Since two shards share no data in common, growing the system to accommodate more time series is as easy as simply adding more servers and updating shard mapping to make these servers available for new time series. Gorilla tolerate machine failures by writing the data to a replicated network storage, although it does not attempt to make storage and memory consistent and may lose the information buffered for writing upon a node failure. Gorilla can handle more disastrous events as well, since it was designed to tolerate an entire region failure by streaming every data point to two different data centers. Similar to disk persistence, the system does not try to ensure consistency between the two regions. Such possible inconsistencies may lead to data loss, and dealing with incomplete data is left to the client.
Query Model
Gorilla query model appears to be very simplistic, as it simply allows to retrieve time series, given the time series unique name and the time range. The rest of the processing is left to the client systems. Such retrieval approach is very fast, as it simply requires locating the server responsible for the time series, uncompressing it and returning to the client. Such approach is most likely tuned for specific monitoring needs at Facebook and it provides very good latency as show below:
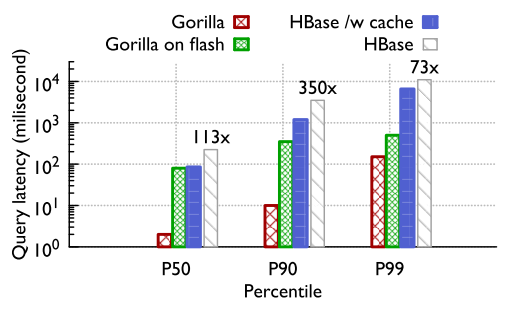
In my master’s thesis I have explored more complicated querying patterns for time series. In particular, one common query pattern is similarity search across many time series or across different parts of the same time series. Many approaches exist to answer the k Nearest Neighbors (k-NN) types of queries that search for k most similar fragments to the input query. Some of these approaches, such as Dynamic Time Warping are very difficult to index and are not suitable for database application, but there are methods that can be used for indexing and database application. I adapted and modified R*-tree index for being stored in the HBase database along with the actual time series data, and as such my system prototype was able to perform k-NN queries (with Euclidean distance similarity) on a disk backed system. Of course there were a number of limitations, such bad scalability when searching for large patterns without the use of dimensionality reduction and overall low latency of searches due to relying on HBase for index. However, in-memory approaches can have fast indexes, and can provide more sophisticated querying patterns to answer the similarity or anomaly detection type of queries. Finding similar sub sequences with Gorilla will require fetching the time series we are interested and exhaustively searching for patterns in them.
There are many motivations for k-NN search in time series, ranging from medical to engineering to entertainment. For example, a system records person’s ECG data and performs a search on new patterns it receives. If it finds a similar pattern to some known cases that lead to heart failure, the system can notify the doctor before the problem can develop further. And of course there are other types of interesting queries that can be done on time series, as such I strongly believe that Gorilla’s query model may be inadequate for some uses.
A Few Concluding Words
Facebook’s Gorilla is a fascinating piece of engineering, it achieves very good compression of time series data, high scalability and fast retrieval time. However, I am not sure one can call it a time series database, as all of its achievements result from making the system more and more specialized for a specific application – monitoring server/system parameters at Facebook. It high compression is the result of low time resolution and low update data update frequency in the time series used for monitoring. It’s query model is designed for fast retrieval, but it is very simplistic and offloads the time series processing, pattern matching and anomaly detection to the client applications. Gorilla’s data is also very specialized: it is single-dimensional, with infrequent updates, small changes to the value from one point to another, and constant update rate. This data is very specialized in nature and can hardly be thought of as a good representation for all other time series data. All of the limitations and compromises made to achieve Facebook’s requirements for a specific use case make me think that Gorilla is not a TSDB by any means. It is rather just a cache for infrequently changing monitoring data.