In my previous post I talked about Raft consensus algorithm. Raft has a strong leader which may present some problems under certain circumstances, for example in case of leader failure or when deployed over a wide area network (WAN). Egalitarian Paxos, or EPaxos, discards the notion of a leader and allows each node to be a leader for the requests it receives. “There Is More Consensus in Egalitarian Parliaments“ talks about the algorithm in greater details.
According to the designers of the algorithm, they were trying to achieve the following three goals:
- Good commit latency in WAN
- Good load balancing
- Graceful performance decrease due to slow or failing replicas
These goals are achieved by decentralized ordering of commands. Unlike classical Paxos and many Paxos-lie solutions, EPaxos has no central leader, and orders the commands dynamically and only when such ordering is required. Upon receiving a request, EPaxos replica becomes a request-leader, it then uses fast quorum to establish any dependencies for such request. If no dependencies are found, it can proceed to committing a request, but if the request conflicts with other requests being processed, the order of the request is established taking into account all the dependencies in a manner similar to regular Paxos algorithm.
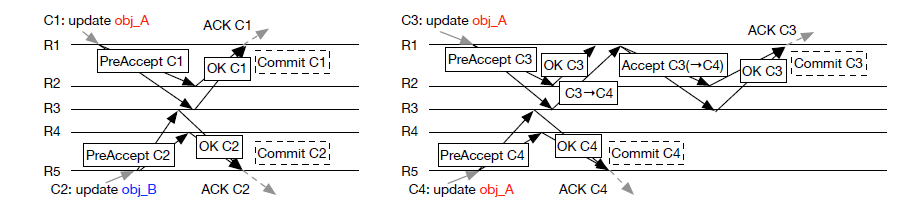
Figure 1. Sample Message flow in EPaxos. R1-R5 are replicas, obj_A and obj_B are requests. Arrows designate message flow. Figure taken from the “There Is More Consensus in Egalitarian Parliaments” paper.
The figure above illustrates two scenarios. On the left we have two requests coming in to different EPaxos nodes (R1 and R5), and such requests have no dependencies on each other, so both R1 and R5 can proceed to commit right after the fast quorum tells them there are no dependencies. Similarly, on the right side we have two messages arriving from the client to their corresponding replicas, but Message C3 has a dependency on message C4. R1 learns of such dependency through node R3 and must invoke Paxos accept stage of the algorithm to enforce proper ordering of the requests, as such we order C3 only after C4 and commit C3 after C4 has been committed and executed.
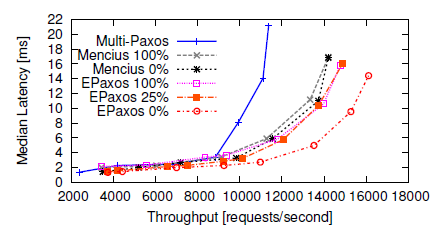
Figure 2. Latency vs Throughput. Figure taken from the “There Is More Consensus in Egalitarian Parliaments” paper.
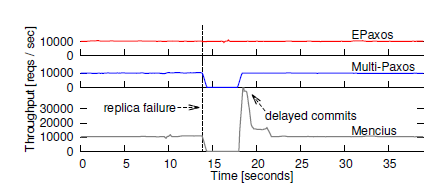
Figure 3. Throughput in case of a replica failure (leader failure for Multi-Paxos). Figure taken from the “There Is More Consensus in Egalitarian Parliaments” paper.
EPaxos demonstrates good performance and stability when compared to other common consensus algorithms. Both figures above are from the EPaxos paper mentioned earlier. It is interesting to see how throughput stays the same for EPaxos in the event of a node failure, while classical Multi-Paxos virtually stops until a new leader can be elected. In Figure 2, the percentage next to the algorithm name designates the conflicting commands, or commands that have dependencies. As can be seen EPaxos generally performs well, even with a high number of conflicting commands, although the difference between 25% and 100% conflicting commands seems small. It is worth noting that based on previous and related work, authors estimate 2% conflicting commands in real world situations.