When we talk about consensus in a distributed system, we talk about a system consisting of multiple machines that act as one state machine yet capable of surviving failures of some of the system nodes. Consensus algorithms are designed to enforce all distributed nodes have the same state so that the distributed system can tolerate failures. Paxos family of algorithms are probably the most widely used consensus mechanism currently used in practice, but according to many researcher in the community it is fairly difficult for implementation and understanding. The authors of Raft claim to have designed an efficient, reliable consensus algorithm that is easy to understand. In fact, the ease of comprehension was at the cornerstone of the algorithm development and influenced many decisions.
Consensus
In the very basic terms, the need to establish consensus arises when a set of clients send requests to the replicated state machines. Such machines need to keep the same state and same log of state changes. In case some nodes of such replicated system fail, an uninterrupted operation is still going to be possible with leftover machines. Once the machines recover from the failure, their state can be brought up to date with the rest of the cluster.
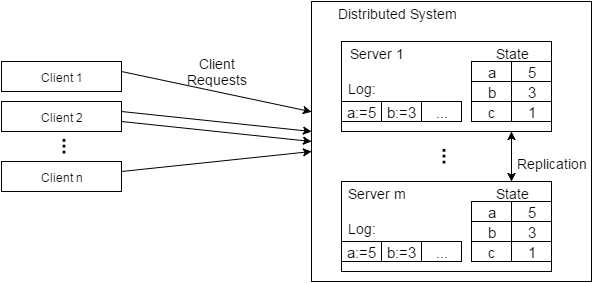
Figure 1. Simplified view of distributed system
An oversimplified view of a distributed system is shown in Figure 1. As the clients send requests to the system, at handles the requests, and replicates state and log changes across the cluster to make sure each node has the correct information. It is the job of a consensus algorithm to keep replicated state machines in agreement with each other.
Raft
Raft is a fairly new consensus algorithm, and as have been mentioned earlier one of the requirement was the ease of understanding. I will not go into much details describing the algorithm, and will provide only the basics of the approach.
Each server in the Raft system can take one of the three possible roles: leader, follower and candidate. The role each server takes determines how it reacts to the messages and requests received. For example, on leader can receive requests form the client, while the follower nodes must relay any client communication to the leader. Follower servers listen and respond to the leader server. A follower node may become a candidate node when it believes that no leader is available.
Leader Election
The first step in the Raft algorithm is a leader election. Once a server starts up, it enters the follower mode, if no leader is present, the node will timeout and change its role to the candidate, thus starting the election process. In the election process, a candidate sends out requests to other nodes, and if other nodes acknowledge such requests, a candidate becomes a leader. A leader failure can occur while the system is operating, but such case is no different than the startup of the cluster, since the followers will timeout and start the election process.
The concept of a term is used as a logical time for the system. Term is used to count how many leaders has been observed by the system. Term information is used to determine stale server with no up-to-date information about the current state of the system. For instance, is a node believes it is in term x, while other nodes are in term x+1, then such stale node needs to be updated with correct log and state machine. Term is also important for leader election, as the system needs to make sure no stale node can become the leader.
Log Replication
Consensus algorithms needs to enforce the replication of state change log. In Raft, only a leader can serve client requests, reducing possible requests entry points down to one machine. Once a leader receives a request, it communicates the change to the follower servers and after receiving acknowledgement of such communication from the majority of the followers, the leader applies or commits the request to its state machine and serves the result to the client. In case some followers do not respond with an acknowledgement, the leader will be trying to update the log of such follower until it receives a successful ack.
Figure 2 show the log entries for a hypothetical cluster of 5 machines. In this scenario, we have some followers who significantly lack behind, but it does not stop the system to advance as long as the majority of servers acknowledge that they received the log entry from the leader. As can be seen, log entries up to log #7 are committed, because the majority of machines accepted that entry.
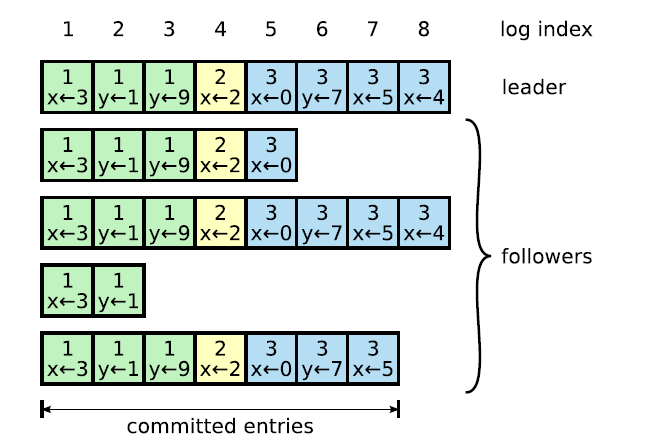
Figure 2. Log structure in Raft. (Source: “In Search of an understandable Consensus Algorithm”
There are a few key safety properties Raft algorithm enforces:
- Only one leader can be elected at a time.
- A leader can only add new entries to the log, but not modify the existing ones.
- When logs have an entry with the same ID and term, such entry and all entries prior to it must contain the same data.
- No two distinct entries can exist with the same id.
More to Read and Think
I am leaving out a lot of details about the algorithm, but I think the basic gist of it can be understood. Of course the paper provides more information and mentions a few optimizations to the algorithm.
One thing that caught my attention when looking at the algorithm is the need to have a single entry point for all client requests. I may be wrong since it is probable the case for all other algorithms with a strong leader, but it seems like this can be a limited factor, if a leader, who serves as such entry point runs out of compute resources or network bandwidth. Imagine a scenario when a leader is so overloaded with serving clients and communicating with all the follower that it causes network latency to go up and eventually severs the connection entirely. A new leader is then elected and it has to deal with even more client requests, more log replications and eventually fails too…