Paper Review and Summary
-
Metastable Failures in Distributed Systems
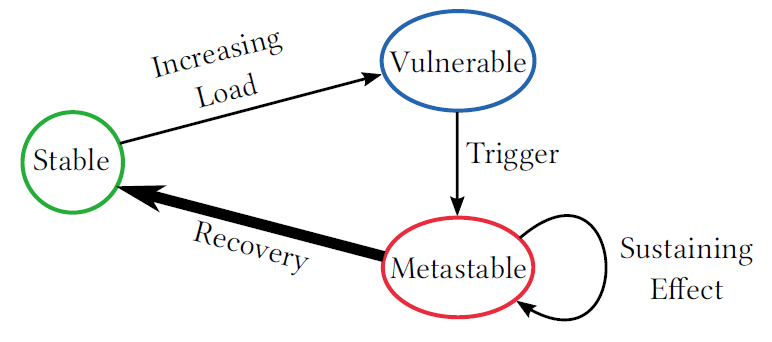
Metastability is a stable state of a dynamical system other than the system’s state of least energy. – Wikipedia Distributed systems often fail spectacularly and unpredictably. They are a cause for a headache and sleepless on-call nights for way too many engineers. And this is despite lots of efforts to understand the failures, and all…
-
Paper Summary: Bolt-On Global Consistency for the Cloud
This paper appeared in SOCC 2018, but caught my Paxos attention only recently. The premise of the paper is to provide strong consistency in a heterogeneous storage system spanning multiple cloud providers and storage platforms. Going across cloud providers is challenging, since storage services at different clouds cannot directly talk to each other and replicate the…
-
Looking at State and Operational Consistency
Recently I rediscovered the “The many faces of consistency” paper by Marcos Aguilera and Doug Terry. When I first read the paper two years ago, I largely dismissed it as trivial, and, oh boy, now I realized how wrong I was at that time. It is easy to read for sure, and may appear as…
-
Is Java Fast Enough for Distributed Applications?
Lots of modern distributed systems are built with Java programming language, and consequently use Java Virtual Machine (JVM) as their execution environment. The list of such systems is rather large: Hadoop, Spark, HBase, Cassandra, Voldemort, ZooKeeper, BookKeeper, Kafka, and the list goes on and on. But is JVM fast enough for these systems? Anyone who…
-
Gorilla – Facebook’s Cache for Time Series Data
Facebook operates a huge infrastructure that needs to be constantly monitored for performance and stability. Such monitoring collects huge amounts of data that must be easily accessible to various diagnosis and anomaly detection tools in order to quickly identify and react to possible issues. Many of such parameters can be represented as real-valued time series.…
-
Pivot Tracing Part 2
After looking more at Pivot Tracing tool described in my earlier post, I asked myself about the limitations of such monitoring approach. Pivot tracing is not a universal tool, so it appears that there are few problems it does not address well enough. The basic idea of the Pivot Tracing is to collect the information…
-
Review – Pivot Tracing: Dynamic Causal Monitoring for Distributed Systems
Debugging can be a nightmare for software engineers, it is even more so in the distributed systems that span many machines in potentially more than one datacenter. Unfortunately, many of the debugging and monitoring techniques for such large system do not differ much from the methods used to debug and monitor simple single-machine software. Logs…
-
Review: Implementing Linearizability at Large Scale and Low Latency
In this post I will talk about Implementing Linearizability at Large Scale and Low Latency SOSP 2015 paper. Linearizability, the strongest form of consistency, can be very important in large scale data storage systems, although many such systems either do not implement linearizability or do not fully expose serializable operation to the clients. The later type…
-
A Few Words about Inconsistent Replication (IR)
Recently I was reading the “Building Consistent Transaction with Inconsistent Replication” paper. In this paper authors use inconsistently replicated state machine, but yet they are capable of creating a consistent transaction system. So what is Inconsistent Replication (IR)? In the previous posts I summarized Raft and EPaxos. These two algorithms are used to achieve consensus…
-
EPaxos: Consensus with no leader
In my previous post I talked about Raft consensus algorithm. Raft has a strong leader which may present some problems under certain circumstances, for example in case of leader failure or when deployed over a wide area network (WAN). Egalitarian Paxos, or EPaxos, discards the notion of a leader and allows each node to be…
Search
Recent Posts
- Paper #196. The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling
- Paper #193. Databases in the Era of Memory-Centric Computing
- Paper #192. OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck
- Paper #191: Occam’s Razor for Distributed Protocols
- Spring 2025 Reading List (Papers ##191-200)
Categories
- One Page Summary (10)
- Other Thoughts (10)
- Paper Review and Summary (14)
- Pile of Eternal Rejections (2)
- Playing Around (14)
- Reading Group (103)
- RG Special Session (4)
- Teaching (2)