Lots of modern distributed systems are built with Java programming language, and consequently use Java Virtual Machine (JVM) as their execution environment. The list of such systems is rather large: Hadoop, Spark, HBase, Cassandra, Voldemort, ZooKeeper, BookKeeper, Kafka, and the list goes on and on. But is JVM fast enough for these systems?
Anyone who has ever dealt with Java probably knows at least a little bit about how JVM works. To start with, Java programs are compiled into a machine independent, un-optimized byte code. The byte code is then being interpreted by the JVM and compiled into the native code with the just-in-time (JIT) compiler. JVM adds various optimizations at the JIT compilation and these optimizations can be more aggressive than the optimizations done by a native compilers. After all, before doing these optimizations and compilation, Java has already ran the code in the interpreted mode, and it was able to collect some statistics on the branch predictions, loops and function calls to make optimization tailored not just to that specific code, but also to the specific runtime or data.
However, before Java performs all the tricks, it needs to run in a slow interpreted mode, incurring some warm-up overheads. OSDI’16 paper “Don’t Get Caught in the Cold, Warm-up Your JVM” goes into more details about what are the warm-up overheads and how they impact data-parallel distributed systems, such as Hadoop, Spark and Hive.
Warm-up Costs
The paper breaks down warm-up overheads into the two categories: class loading and bytecode interpretation overheads. It investigates these overheads under different workloads on different distributed systems. Of course it is expected for warm-up to impact the freshly started JVM, but how big is the cost of warm-up? If we look at the HDFS client performance, we can see the warm-up can easily take a few seconds, depending on your task. In HDFS, writing is more complicated and involves more classes, thus Java spends more time loading all the classes. Warm-up while reading from HDFS also differs depending on whether we read in parallel or sequentially. The graph below shows warm-up costs by the task and dataset size.
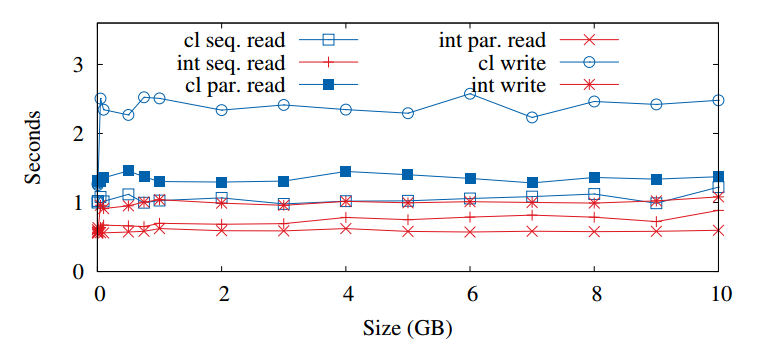
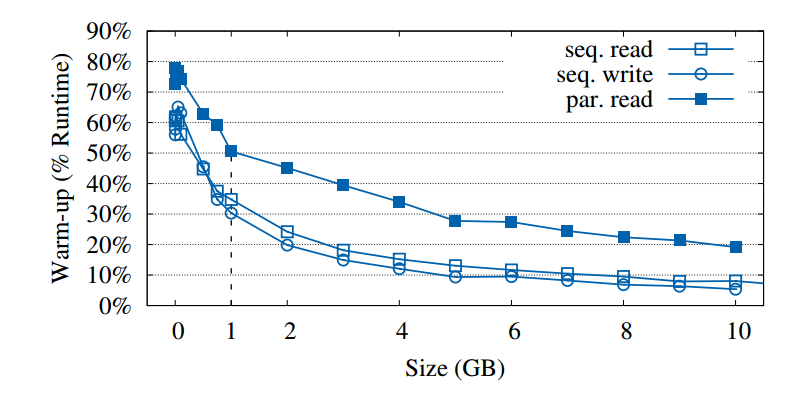
We can see that the size of the operation has no impact on the overheads, meaning that small operations will spend much larger fraction of their time in warm-up, while big operations tend to amortize the warm-up costs.
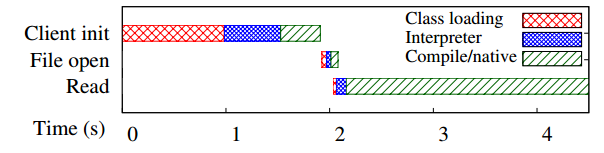
It is also interesting to see when the warm-up occurs in the execution cycle. Obviously starting the client requires lots of class loading and interrupting the byte code, however starting actual jobs (for the first time?) also incurs warm-ups.
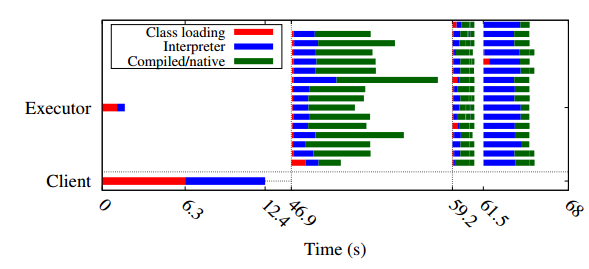
Another question one may ask is how slow actual class loading is? For HDFS sequential read, client had to load about 2000 classes, taking 1028 ms to complete. Spark was much heavier on the classes it uses and needs to load with 19,066 classes on average taking roughly 6.3 seconds in overheads. These are rather large numbers, especially if we aim at low-latency execution of our requests, however not everything is so grim.
It is important to emphasize that the paper mainly uses clients to study the warm-up, while the actual distributed system is not being studied in much of the details. To be fair, authors mention that the warm-up overheads are present on the server side as well, and in Spark the executor warm-up can add up to almost 50% of the overall warm-up time.
Dealing with Warm-up
The paper argue that these are very big overheads that must be dealt with. Authors even offer a prototype solution, a modified JVM, called HotTub, which acts as a container for many other “normal” JVMs to be reused when needed. Reusing JVM means we do not need to load classes and perform JIT. Such approach works well for short lived JVMs, i.e we have a client performing one operation and terminating. If such terminated JVM ends up in the pool for JVM reuse, we can save time on overheads next time we need another short-lived JVM.
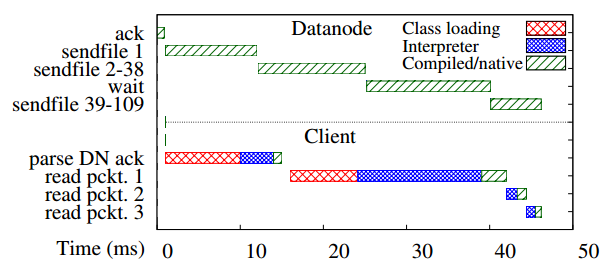
I have to disagree, however, that these overheads are a big problem, and here is why. JVM running server side of the distributed system are warmed-up if they ran for at least some time. As such, these machines do not experience warm-up costs anymore. In this breakdown of the HDFS request, we do not see any warm-up losses occurring on the data-node side and all of the overheads were due to the warm-up of a short-lived HDFS client. This means that keeping you JVM alive and designing your workloads/client to stay up is the best solution to overcome these type of overheads.
There are few lessons I have learned from this paper. They may sound like a common sense, but nevertheless these are important points to keep in the back of your head to get the most out of your Java code.
- Keep JVMs alive. Long running JVMs do not incur as many new class loads and do not need to interpret as much code, allowing the JVM to be faster.
- Simpler is better. Too Many classes hurt performance on the warm-up, however do not go to extreme on the other side too. After all these are warm-up costs and not constant penalty to your performance.
- Watch your external libraries. This goes together with previous point. Bringing a big library to perform one small task may not be too wise if similar-performing alternatives are available.