The last paper in our reading group was “Protean: VM Allocation Service at Scale.” This paper from Microsoft is full of technical insights into how they operate their datacenters/regions at scale. In particular, the paper discusses one of the fundamental components of any cloud provider — the VM service. The system, called Protean, is an allocation service that handles VM allocation requests at the availability zone granularity in each Azure region. It tries to figure out which server of many thousands of candidates is the best fit for the VM described in the request. Its goal is to pack VMs tightly to avoid fragmentation of resources — having too many small and unusable server chunks. There are several challenges in doing so. First, each VM has a set of requirements, such as the VM type, the number of vCPUs, memory allocation, on-server SSD size, networking, location preferences for fault tolerance, and many more. This alone makes the problem very hard to solve optimally, NP-hard as a matter of fact. The second major challenge is doing these allocations at scale. There are surprisingly many VM allocations going on in each availability zone all the time. In the steady state, the system deals with hundreds of allocation requests per second, with occasional spikes to thousands of new VM requests per second!
Protean is made up of the placement store, a database that keeps a record of VM assignments in the zone’s server inventory. One of many concurrent Allocation Agents (AAs) computes the actual VM assignment to the machine. Each AA is like a server filter — it takes the requests for new VMs and filters out all the servers not capable of hosting the VM. After the filtering, AAs compute a general preference score to figure out a set of most suitable servers and pick one random server from such a set of candidates.
Protean implements this whole filtering and scoring using a rule approach and divides the process into multiple phases. First, it uses cluster validator rules to filter out any homogeneous clusters that cannot support a VM. These validator rules specify a “hard” requirement needed to support a VM. For example, a VM with a GPU cannot be supported by a cluster of GPU-less servers, so the entire cluster is automatically not a candidate for allocation. Then the system scores the clusters that can handle the VM based on some preference rules, which describe “nice-to-have” features, as opposed to hard requirements. A similar validator rules process is repeated to filter out the non-compatible machines in the selected cluster (for example, servers that are already at capacity and have no available resources for a VM type). Finally, all remaining good servers are scored based on the machine preference rules.
This tiered approach greatly reduces the possible allocation choices since many thousands of servers can be removed from consideration by excluding the entire clusters. However, filtering out the remaining machines is still a resource-intensive task. Protean has many rules that validate or score machines and doing these computations can add up to significant amounts of time. Each AA, therefore, caches the rules and the scoring results. This works well for two major reasons: (1) most requested VMs are very similar, so the same rules are used repeatedly; (2) inventory changes are relatively small, and between two invocations of the same rule, there will not be a lot of change in terms of server allocations. Moreover, AAs largely address the inventory changes by updating the cached rules before each use. Cache updates recompute the scores/results for a handful of servers that may have been updated by other AAs, and it is a lot faster than doing the full computation for all servers every time. To make the system more efficient, the AAs learn of changes from the placement store via a pub/sub system, so updating cache only involves local operations and local storage and does not query the placement store. This lowers the latency of cache updates and reduces the load on the placement store by avoiding the repeated queries for every cache update.
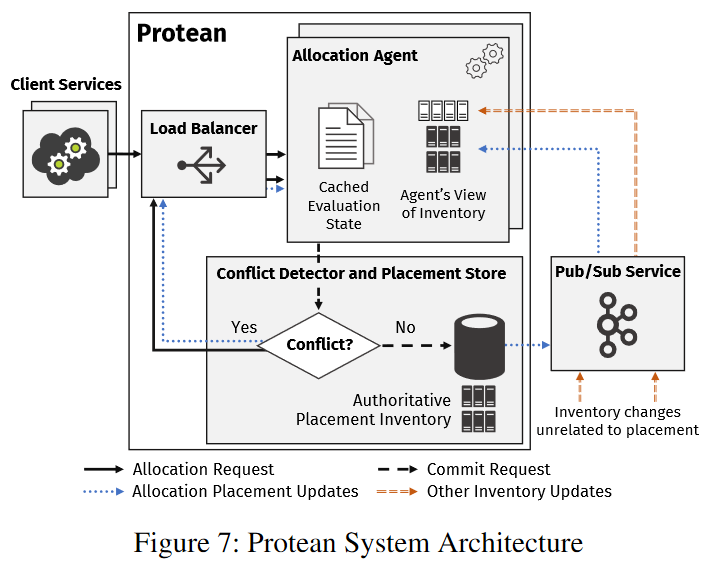
The whole interaction between AA and placement store is not strongly consistent/transactional to avoid locking the store while computing the VM placement. This allows multiple AAs to work concurrently, but also introduces the possibility of conflicts due to a race — a couple of AAs working concurrently may pick the same server for two different VM allocation requests. These conflicts are resolved by the placement store in one of two general ways. If the target server can accommodate both VMs (i.e. the validator rules pass for the server for two allocations instead of one), then the placement store will merge the conflicts. If the server cannot handle both VMs, then one conflict allocation is retried. Protean allows up to 10 retries, although this rarely happens in practice. Also, since the system already has a mechanism to tolerate conflicts, it is fine for AAs to work off slightly stale and not-up-to-date caches, allowing the aforementioned pub/sub way of updating them. However, there is probably some balance between the staleness of cache, the number of conflicts/retries, and the overall quality of placement, so I’d suspect that the cache updates still need to be relatively recent.
Microsoft has released the VM allocation dataset to the public!
As always, the paper has many more details and rationale for all the decision choices. My rambling presentation of the paper is on YouTube:
Discussion
1) Preference Rule Evaluation. Preference rules implement a Compare function that orders two objects (two servers or clusters) for a given VM request. Each rule also has a weight w that determines the overall weight of a preference rule in the scoring of servers/clusters. The servers are scored/ordered based on all preference rules, and the order is computed with a global compare function that combines all the individual compare functions in a weighted manner. However, the weight is constructed in such a way, that a higher-weight rule always outweighs all lower-weight rules combined. This is done to aid in the explainability of VM placement. The question we had is why do we need to compute the global compare function with all preference rules (and waste all the time doing these computations) if we can evaluate the rules sequentially starting with the most important rules first. This way, if the most important rule produces enough desired servers, we do not need to evaluate other lower-priority rules.
Of course, caching makes computing fast, since most rules have already been evaluated before, so this may be the reason for just sticking with a general score. At the same time, the need for cache is due to the slow speed of rule evaluations, and it seems like such evaluation of all rules (at least with the strict priority of preference rules) is not necessary.
2) On the Importance of Explaining the Allocations. Part of the design is the result of having “explainable” decisions — engineers want to know which rule has impacted each decision. But how important is this? What benefits it gives the engineers/operators aside from some piece of mind of understanding the system’s choices. Can a more efficient system be designed if the “explainability” rule is omitted? After all, we have many ML systems (including safety-critical systems, like self-driving vehicles) that are based on the models that lack any “explainability”.
3) Caching System. This is one interesting caching system, that caches the results of computations. It is highly-tailored to the task at hand, and papers go into great detail on many nuances of the systems. The interesting part is the cache-updates that must be done before each cache use to bring the cache up-to-date (and recompute some parts). However, the update does not guarantee that cache is the most recent! It simply ensures that cache is more recent, but it still may not have the newest changes that are still in the pub/sub pipeline.
4) Evaluating the Quality of Placement. The paper talks about the quality of placement quite a lot, however, the evaluation is limited to one simulation on packing density. However, it would be nice to see how production variations impact quality, especially since the paper suggested these impacts are small. Another interesting point is that the paper claims CPU to be the most contended resource. So how much impact other resources and constraints play in the quality of packing?
5) Many Interesting Tidbits. Most VMs are small – 1-2 cores. We think this is due to lots of small automated tasks, such as build and testing pipelines. Many VMs have a short lifespan. This is probably for the same reason, as these build-pipeline VMs will get destroyed when no longer needed. Need to keep empty servers. This looks weird on the surface to have idle capacity, but the paper mentions the fault-tolerance reasons — have resources to move VMs that occupy an entire machine. There are many more interesting tidbits in the paper.