The 83rd paper in the reading group continues with another SOSP’21 paper: “Faster and Cheaper Serverless Computing on Harvested Resources” by Yanqi Zhang, Íñigo Goiri, Gohar Irfan Chaudhry, Rodrigo Fonseca, Sameh Elnikety, Christina Delimitrou, Ricardo Bianchini. This paper is the second one in a series of harvested resources papers, with the first one appearing in OSDI’20.
As a brief background, harvested resources in the context of the paper are temporary free resources that are otherwise left unused on some machine. The first paper described a new type of VM and that can grow and contract to absorb all unused resources of a physical machine. An alternative mechanism to using underutilized machines is creating spot instances on these machines. The spot instance approach, however, comes with start-up and shut-down overheads. As a result, having one VM that runs all the time but can change its size depending on what is available can reduce these overheads. Of course, using such unpredictable VMs creates several challenges. What type of uses cases can tolerate such dynamic resource availability? The harvested VMs paper tested the approach on in-house data-processing tasks with modified Hadoop.
The SOSP’21 serverless computing paper appears to present a commercial use case for harvested VMs. It makes sense to schedule serverless functions that have a rather limited runtime onto one of these dynamic harvested VMs. See, if a function runs for 30 seconds, then we only need the harvested VM to not shrink for these 30 seconds to support the function’s runtime. Of course, the reality is a bit more nuanced than this — serverless functions suffer from cold starts when the function is placed on a new machine, so, ideally, we want to have enough resources on the VM to last us through many invocations. The paper spends significant time studying various aspects of harvest VM performance and resource allocation. Luckily, around 70% of harvest VMs do not change their CPU allocations for at least 10 minutes, allowing plenty of time for a typical function to be invoked multiple times. Moreover, not all of these CPU allocation changes shrink the harvest VM, and adding more resources to the VM will not negatively impact functions it already has.
There are two major problems with running serverless workloads in the harvest VM environment: VM eviction, and resource shrinkage. Both of these problems impact running functions and create additional scheduling issues.
The VM eviction is not unique to harvest VMs and can also occur in spot VMs. According to the original harvest VM paper, harvest VMs should get evicted far less frequently — only when the full capacity of the physical server is needed. Moreover, the VM eviction has a negative impact only when it runs a function, and since VMs get an eviction warning, most often they have enough time to finish executions that have already started. As a result, a serverless workload running in harvest VMs still has a 99.9985\% success rate in the worst-case situation when a data center has limited harvested resources and undergoes many changes. Nevertheless, the paper considers a few other strategies to minimize evictions and their impact. For instance, one strategy is to use regular VMs for longer running functions to prevent them from being evicted “mid-flight,” while using harvest VMs for shorter jobs.
The resource shrinkage problem is a bit more unique to harvest VMs. Despite most harvest VMs undergoing resource reallocation relatively infrequently, a VM shrinkage can have severe implications. One or more running functions may need to stop due to resource shrinkage, and rescheduling these jobs may also be impacted by the cold start. As a result, the paper presents a scheduling policy, called Min-Worker-Set (MWS), that minimizes the cold starts for a function. The idea behind MWS is to place each function onto as few servers as possible while ensuring adequate compute capacity to serve the workload.
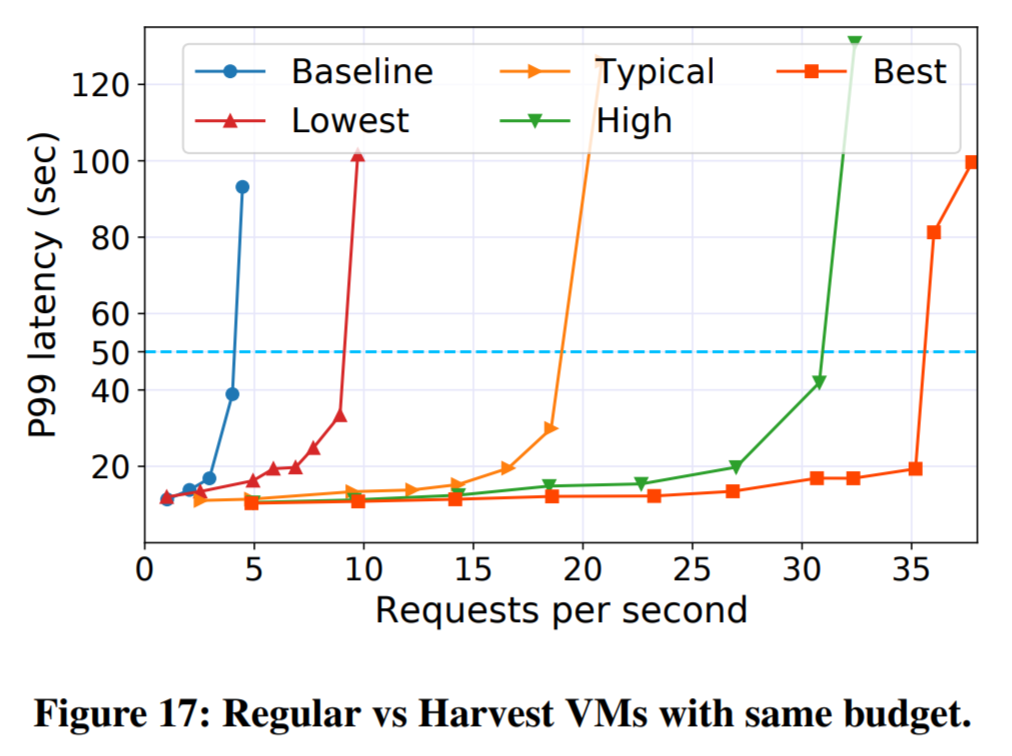
The authors have implemented the prototype with the OpenWhisk platform. The paper provides extensive testing and evaluations both for performance and cost. Each figure in the paper has tons of information! That being said, I am including the performance on a fixed budget figure below to show how much cheaper running serverless on harvest VMs can be. The blue line is running some workload with rather heavy and longer-running functions on dedicated VMs under some fixed budget. Other lines show the latency vs throughput of harvest VM solution under different levels of harvest VM availability. The “lowest” (red triangle) line is when few harvest resources are available, making harvest VMs most expensive (who and how decides the price of harvest VM?).
As usual, we had the presentation in the reading group. Bocheng Cui presented this paper, and we have the video on YouTube:
Discussion.
1) Commercializing Harvest VMs. This paper sounds like an attempt to sell otherwise unused resources in the data center. The previous harvest VM paper aimed at internal use cases (and there are lots of them, ranging from data processing to building and test systems). I think this is a great idea, and hopefully, it can make the cloud both cheaper and greener to operate with less resource waste. At the same time, it seems like the current prototype is just that — a prototype based on an open-source platform, and I wonder if this is feasible (or otherwise can be done even more efficiently) at the scale of an entire Azure cloud.
2) Evaluation. Most of the eval is done in an environment that simulates harvest VMs based on the real Azure traces. I suppose this is good enough, and the evaluation is rather extensive. It also includes a small section of the “real thing” running in real harvest VMs. But again, I wonder about the scale.