Last time, I briefly talked about my pile of eternal rejections. Today, I will describe another paper that has been sitting in that pile for quite some time. It seems like this particular work, done by my student Bocheng Cui, has found its home, though, and by the skin of its teeth, it will appear in SRDS’24.
I will not pretend that this work has a lot of “novelty,” which is a common theme for papers in my eternal rejection pile. However, I still think it has several valuable lessons to teach regarding architecture simplicity, fault-tolerance, and reliability of distributed systems — not all distributed protocols are fault-tolerant in practice, even if their complicated recovery mechanisms work in theory.
Bocheng was reviewing the literature on state machine replication, and in the process, he looked at the Mencius algorithm. This algorithm has a critical, yet trivially fixable, hole that makes it perform poorly even when just one node fails. To add an insult to injury, this hole did not have to be there in the first place, as a better solution literally existed in the algorithm Mencius builds upon — MultiPaxos. To be fair, I like Mencius protocol for the simplicity of its core idea.
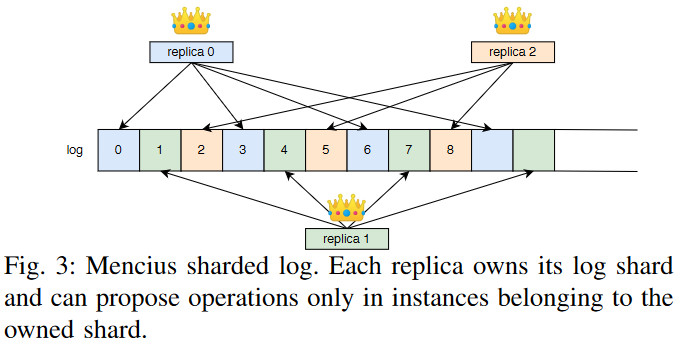
Ok, so let’s first have a refresher on Mencius. The big idea in Mencius is to shard the state machine log such that every node owns some instances of that log. The ownership of log instances usually happens in a round-robin manner and is static to the cluster configuration. This “share all work and responsibility equally” approach contrasts with MultiPaxos, where a single leader is the sole owner of the log. Each replica then acts as a leader on its log instances and pretty much relies on Phase-2 of MultiPaxos to propose commands in these log instances.
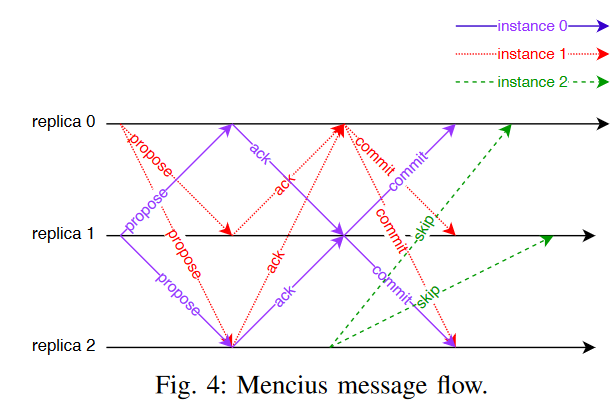
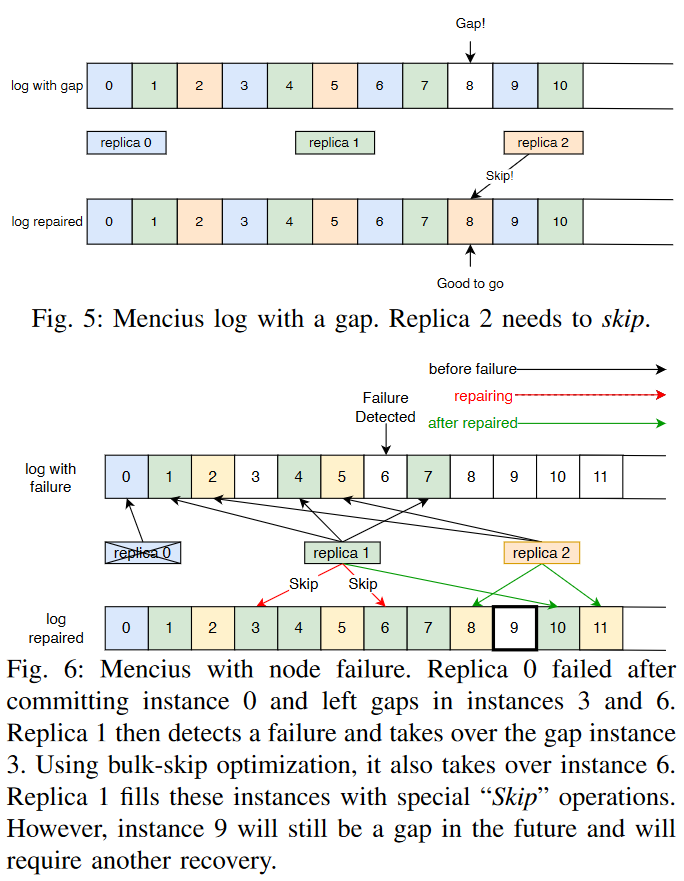
Obviously, through the shared ownership of the log, Mencius avoids a leader bottleneck and can theoretically provide better performance. Like MultiPaxos, however, the state machine executes the log sequentially, and if there are any gaps in the log, it has to pause and wait for the gap to get filled. The log gaps are not a big problem with a single leader, as it fills the log sequentially; under normal conditions, the gaps at replicas can arise only in case of some faults (i.e., messages dropped), which are easy to detect and recover. In Mencius, the log gaps can appear without any faults — we simply need some node with nothing to propose in its log instances, while other nodes have something. So, if a replica does not have a command to propose, let’s say in log instance 8, it will sit and wait for the command. Other replicas may have commands and proposed instances 9 and 10. But since slot 8 is still empty, the entire state machine stalls on all nodes. Mencius recovers by replicating a special “skip” operation, a non-mutating command designed solely to fill empty log instances and unblock the state machine. This “skip” command is reactive — a node issues it only when it sees blocked items in the log replicated by other nodes after the gap.
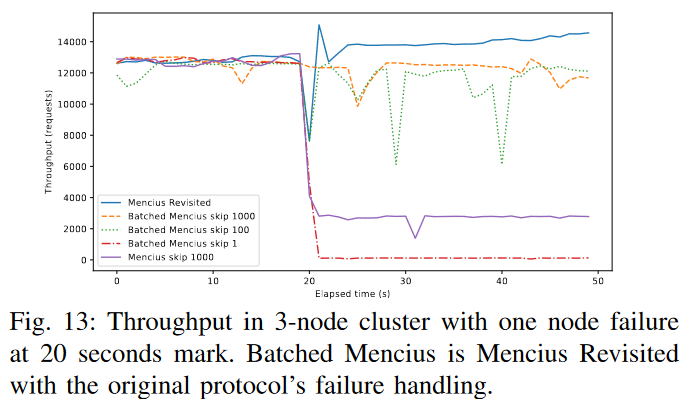
Phew, so now we have complicated the protocol with “skips” to deal with gaps, and as a consequence of its reactivity, we also made the tail latency worse. But this tail latency is not even the worst consequence of skips. See, these skips unblock a state machine from a log gap only when the node that owns that gap is alive and can issue a skip. What happens if a node fails? Well, all empty log instances it owns (potentially for many commands in the future) are blank, and there is no one to fill these gaps with “skips.” So here comes another reactive solution — whenever a log gap exists for too long, run a MultiPaxos protocol to elect a new leader for that gap log instance and either recover it (if there was something legit in it) or issue a skip. This is a perfectly safe solution. But it is extremely slow — waiting for every gap to timeout, run a round (hopefully one round, as dueling leaders/FLP is still a thing) of leader election, and recover the log instance only to be blocked by the next gap and repeat. What do these repeated leader elections do? For one, the latency of the state machine is high since the execution is constantly blocked by gaps in the log. But it also keeps wasting resources by running these leader elections non-stop. The original Mencius also proposes a naive optimization — taking over multiple log instances at once. We call this optimization “bulk-skip.” We illustrate an impact of such node failure below — at the 20-second mark, a node fails, and the cluster of 3 nodes can no longer sustain a workload of 13k requests per second.
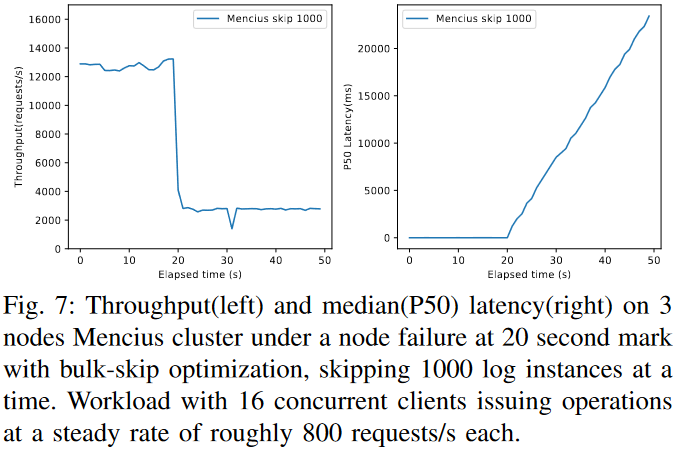
So this is the (maybe obvious and not novel) lesson I got here. Mencius is an example of a protocol that is fault-tolerant only on paper. I sometimes also call this an “algorithmic” fault-tolerance — it is safe, and it restores liveness after the reconfiguration/election, but in practice, its performance is so degraded that it almost does not matter. The reason for this, I think, is not unique to Mencius, but can be generalized to how many distributed systems and protocols are designed.
See, Mencius was designed to be simple. It takes MultiPaxos and makes several adjustments. However, these changes to the base algorithm were done in a greedy manner, only considering a part of a protocol or one emerging issue at a time, and when we put everything together, the whole thing crumbles. There are two main “greedy” changes to MultiPaxos that make Mencius. The first one is static log partitioning. It is simple to do but creates a problem when the protocol is no longer operating in the initial configuration, such as when a node fails. The second “greedy” step was the addition of “skip” commands to deal with a node that has nothing to propose. It is a simple solution to that specific problem, but it does nothing to help with node failures, although the two problems are very similar, as in both cases we have a gap in a log because the node did not propose a command. Solving the node failure on top of an algorithm with “skips” and static configuration then became kludgy.
Anyway, seeing the full picture is important, but also very difficult when we deal with distributed systems. Our Menicus Revisited algorithm is simpler than the original, and its simplicity did not require any new mechanisms or techniques. No novelty. In fact, I can describe the changes we made in just ten sentences.
We realized that a completely static partitioning is not required in Mencius. Thus, we simply changed the leader election process to take over all log instances owned by the failed replica, similar to how MultiPaxos takes over the leadership of the entire log from a failed leader. Naturally, when a node recovers, it can use the same procedure and take over its log shard back. We also realized that “skip” operations complicate protocol while mechanisms to issue “skips” contribute to tail latency and consume resources. Getting rid of skips was also easy — we used a “groundbreaking” idea of batching. See, if each node proposes dynamically sized batches of commands at a fixed rate, then we can replicate and commit these batches regardless of how many commands each replica has. Even if the node has nothing to propose, it can still commit an empty batch. These empty batches are similar to “skips” but they are not reactive and do not add extra latency for detecting the need for a “skip.” The entire part of the protocol that checks whether a node must send a skip is now entirely gone, as both cases converged to one common highly optimized path through the protocol. Detecting the need for a fail-over is also now simpler since each batch also acts as a heartbeat.
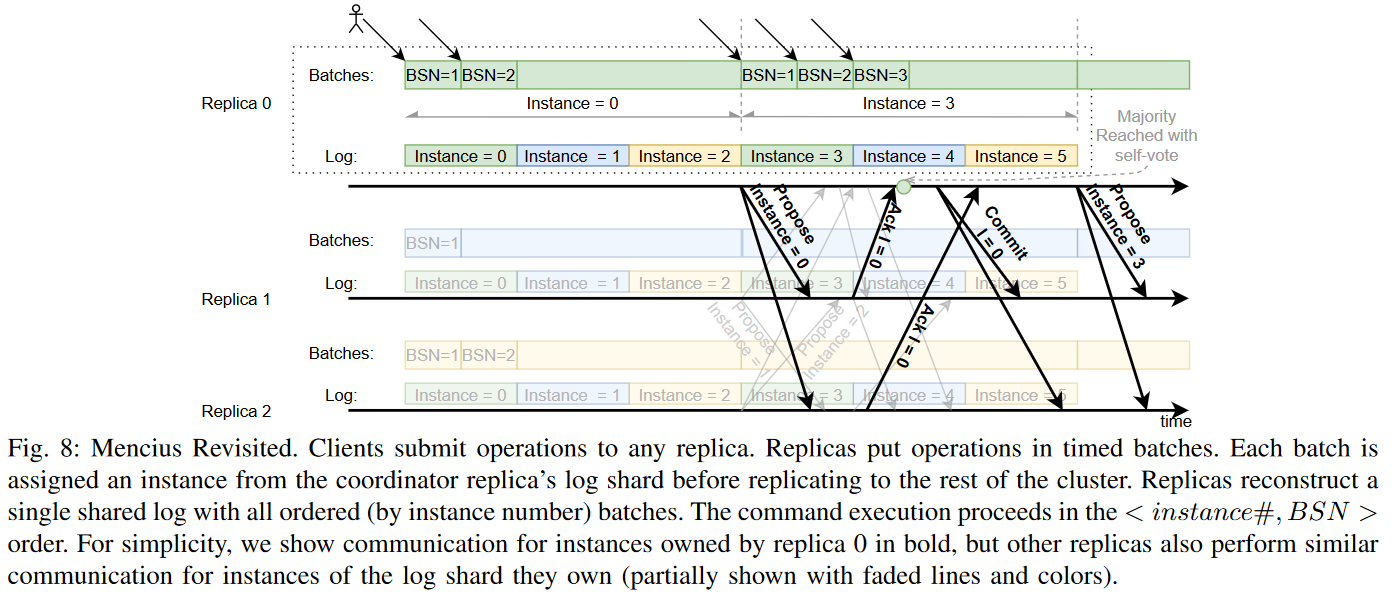
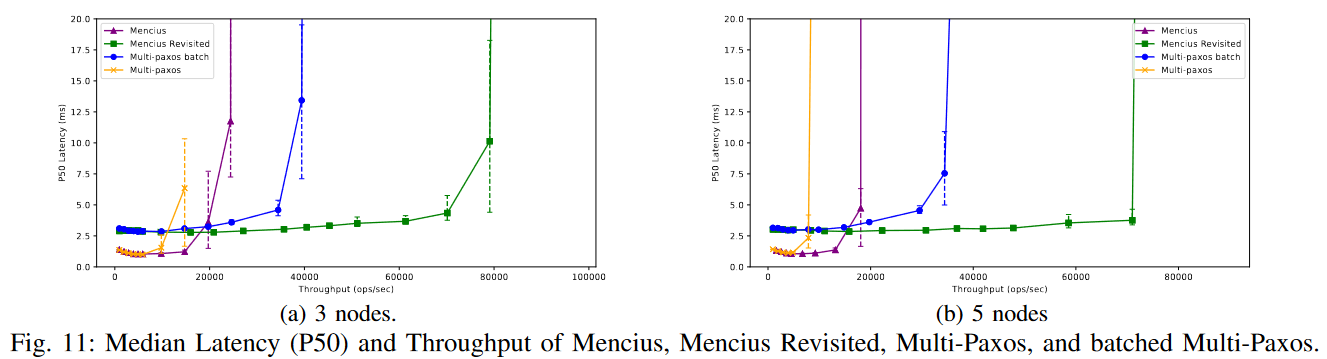
Anyway, we designed a simpler Mencius by looking at the big picture instead of greedily solving one problem at a time. But of course, we also had the benefit if the hindsight to fix these problems. Our throughput, thanks to batching (3 ms batches in the figures below), is much higher, while latency is still low. Our performance under node failures is more predictable. And I like predictable performance. There will be a bit more stuff in the upcoming paper/report.