Other Thoughts
-
Metastability in Recovery: Cascading Recovery with a Loop

My last metastable blog post discussed the interactions between systems and components and how they can lead to metastable failures. Specifically, I looked at interactions between systems/components and how signals can be misinterpreted by different systems due to ambiguity — a timeout may mean a transient fault that can be fixed by retrying, but it
-
Murat and Aleksey Read Papers: “Cloudspecs: Cloud Hardware Evolution Through the Looking Glass”

The “Cloudspecs: Cloud Hardware Evolution Through the Looking Glass” CIDR paper by Till Steinert, Maximilian Kuschewski, and Viktor Leis was the first paper I and Murat read this year. It was a short, but interesting read. Below is our reading video and my one-paragraph summary. The paper discusses the evolution of AWS cloud (virtual) hardware
-
On Metastable Failures and Interactions Between Systems
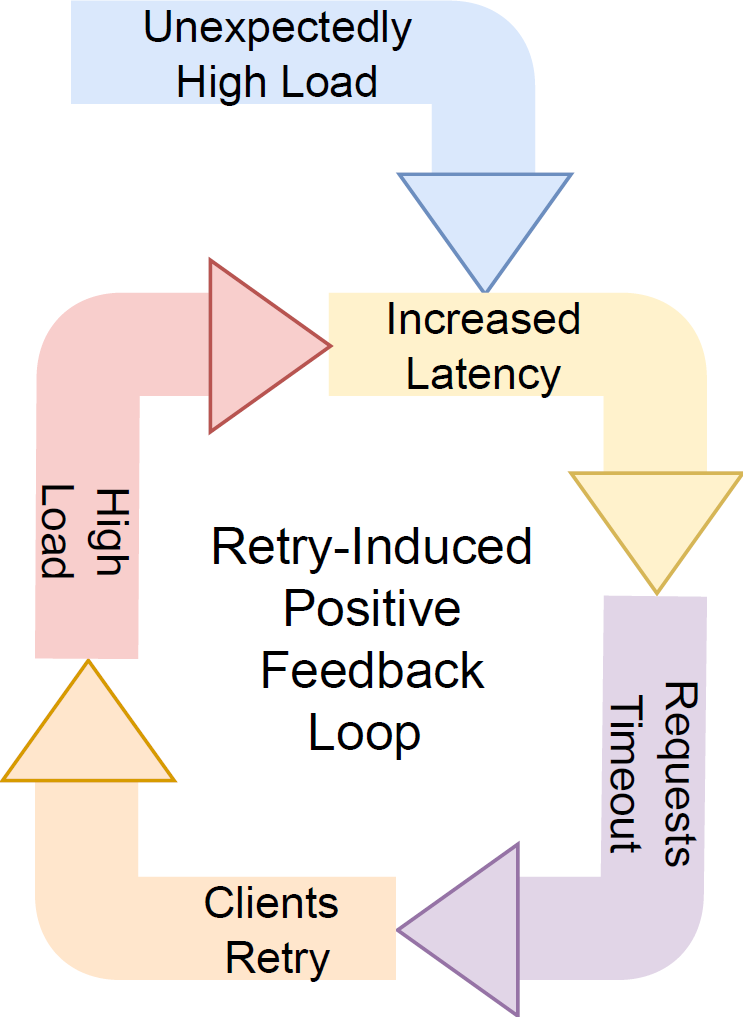
I’ve written about metastable failures before. The topic has been picked up by a few different teams since the, all analyzing metastable failures more, while I apparently has been slacking off… Anyway, Metastable failures are self-sustaining performance failures that arise in systems due to a positive feedback loop triggered by an initial problem. This positive
-
Murat and Aleksey Read Papers: “Barbarians at the Gate: How AI is Upending Systems Research”

The “Barbarians at the Gate: How AI is Upending Systems Research” paper by Audrey Cheng, Shu Liu, Melissa Pan, Zhifei Li, Bowen Wang, Alexander Krentsel, Tian Xia, Mert Cemri, Jongseok Park, Shuo Yang, Jeff Chen, Lakshya Agrawal, Aditya Desai, Jiarong Xing, Koushik Sen, Matei Zaharia, Ion Stoica from Berkeley has recently made a splash in
-
Academic Chat with Murat and Aleksey: 5 Cs of the Invisible Curriculum.

Instead of reading papers, last night, Murat and I engaged in an interesting discussion on skills, traits, and qualities needed for a PhD. This discussion came as a follow-up to Murat’s recent blog on “The Invisible Curriculum of Research.” In his blog, Murat discusses “Curiosity, Clarity, Craft, Community, and Courage” as skills/qualities of a good
-
HoliPaxos: Towards More Predictable Performance in State Machine Replication

I will be presenting our new paper, “HoliPaxos: Towards More Predictable Performance in State Machine Replication,” at the VLDB’25. Feel free to ping me if you are there and want to chat! This paper explores several orthogonal optimizations to the classical MultiPaxos state machine replication protocol to improve its performance stability in the presence of
-
Cloudy Forecast: How Predictable is Communication Latency in the Cloud?
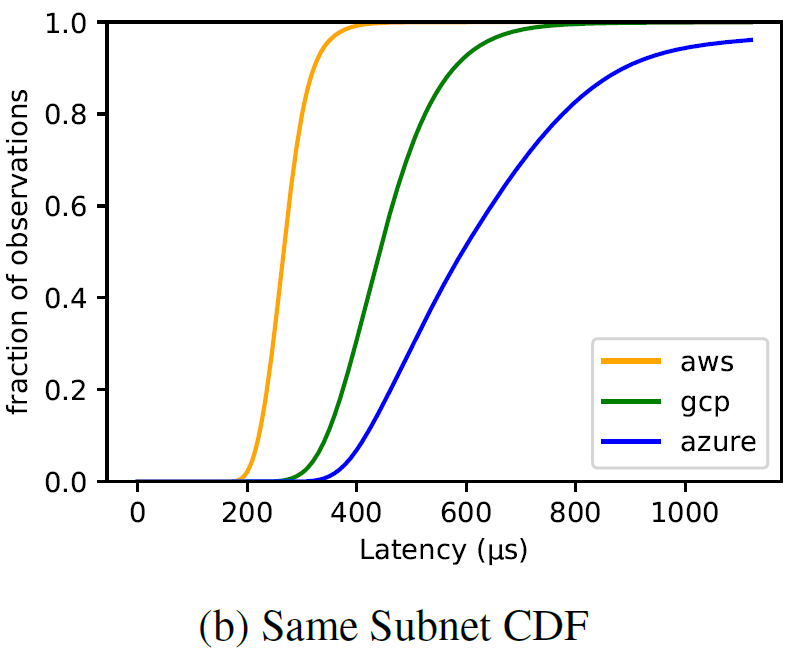
Many, if not all, practical distributed systems rely on partial synchrony in one way or another, be it a failure detection, a lease mechanism, or some optimization that takes advantage of synchrony to avoid doing a bunch of extra work. These partial synchrony approaches need to know some crucial parameters about their world to estimate
-
Metastable Failures in the Wild
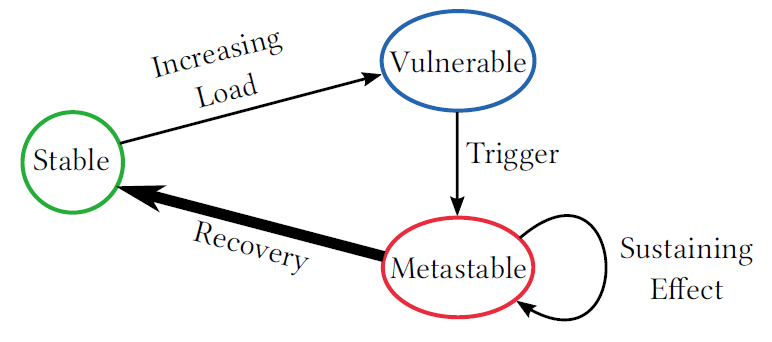
Metastable failures in distributed systems are failures that “feed” and strengthen their own “failed” condition. The main characteristic of a metastable failure is a positive feedback loop that keeps the system in a degraded/failed state. These failures are hard to spot, as they always start with some other distraction — some trigger event that nudges
-
How to Read Computer Science (Systems) Papers using Shampoo Algorithm
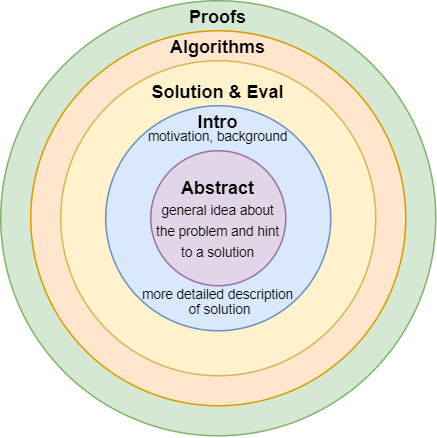
I think most academics had to answer a question on how to approach papers. It is the beginning of the semester and a new academic year, and I have heard this question quite a lot in the past two weeks. Interestingly enough, I believe that almost every academic active on the Internet has written about
-
Scalable but Wasteful or Why Fast Replication Protocols are Actually Slow
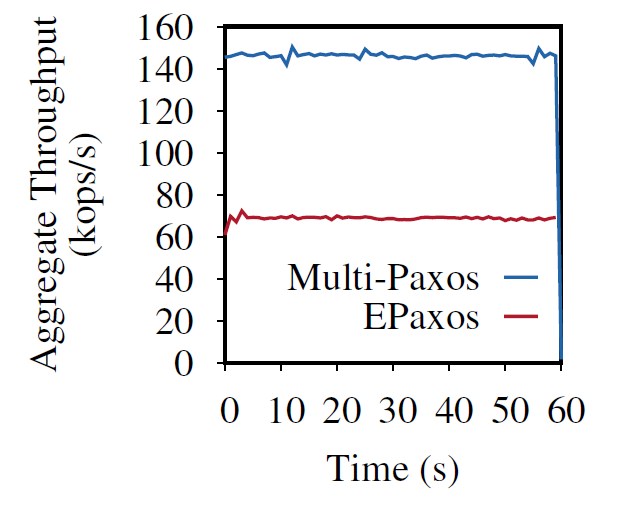
In the last decade or so, quite a few new state machine replication protocols emerged in the literature and the internet. I am “guilty” of this myself, with the PigPaxos appearing in this year’s SIGMOD and the PQR paper at HotStorage’19. There are better-known examples as well — EPaxos inspired a lot of development in
Search
Recent Posts
- Metastability in Recovery: Cascading Recovery with a Loop
- Murat and Aleksey Read Papers: “Self-Defining Systems”
- Murat and Aleksey Read Papers: “Cloudspecs: Cloud Hardware Evolution Through the Looking Glass”
- Murat and Aleksey Read Papers: “Rethinking the Cost of Distributed Caches for Datacenter Services”
- On Metastable Failures and Interactions Between Systems
Categories
- One Page Summary (12)
- Other Thoughts (16)
- Paper Review and Summary (16)
- Pile of Eternal Rejections (2)
- Playing Around (14)
- Reading Group (104)
- RG Special Session (4)
- Teaching (2)