In the 127th meeting, we discussed the “DeepScaling: microservices autoscaling for stable CPU utilization in large scale cloud systems” SoCC’22 paper by Ziliang Wang, Shiyi Zhu, Jianguo Li, Wei Jiang, K. K. Ramakrishnan, Yangfei Zheng, Meng Yan, Xiaohong Zhang, Alex X. Liu.
This paper argues that current Autoscaling solutions for Microservice applications are lacking in several ways. The first one is the timing of autoscaling. For example, rule-based systems use some threshold boundaries on performance metrics to decide whether to scale up or down. This reactive approach adjusts to the behaviors of the system that already happened, and this means that thresholds have to account for that — one may set the thresholds more conservatively to allow the autoscaling systems to “spool up” once the threshold is hit, but before the system is in real danger violating SLAs or needed additional resources. Naturally, this threshold manipulation also requires some expert knowledge of systems to autoscale. An alternative to rule-based solutions is learning-based autoscaling, which relies on machine learning. This can reduce the requirement for domain knowledge, as the autoscaling system can learn the patterns itself. However, current learning-based solutions have another limitation — they rarely consider resource usage due to frequent variations in utilization. Naturally, maximizing resource utilization can lead to monetary savings, so it is important for an autoscaling system to accurately provision resources in a dynamic system.
The paper proposes DeepScaling, a system that optimizes resource usage (in this case it is CPU utilization) while meeting SLO constraints. DeepScaling does so by focusing on forecasting the future workload based on historical data. From this prediction, it estimates the resource requirements for the system in the near future and provisions or decommissions resources as needed. These tasks are separated into 3 components: Workload Forecaster, CPU Utilization Estimator, and Scaling Decider. There are a few other components, such as load balancers, controllers, and monitors to ensure predictable load spread in the cluster, perform data collection and enact the scalability decisions. The predictive manner allows DeepScaling to anticipate load increases and provision enough new capacity ahead of time, eliminating the need for overly conservative autoscaling bounds.
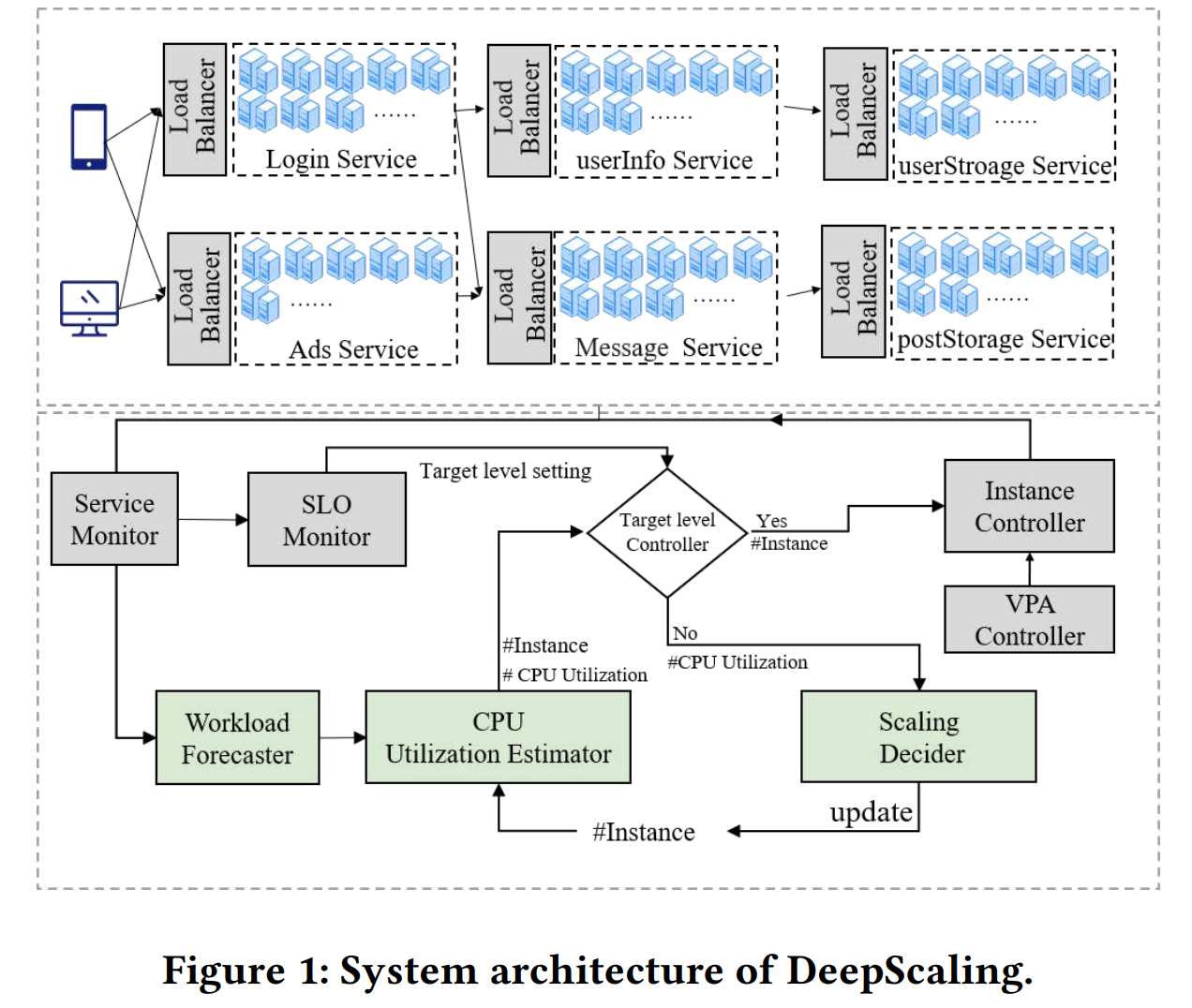
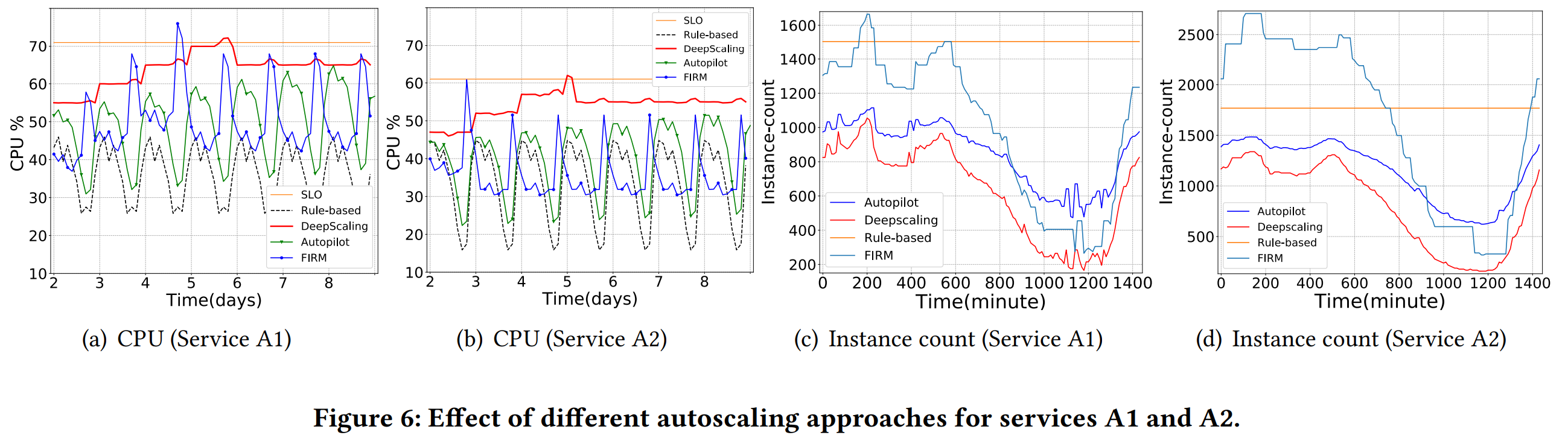
The paper provides significantly more details on the machine learning components, but I am less interested in these as a systems person. The paper also provides a good evaluation of these components, so it is actually worth the read, especially for more ML-inclined folks.
Discussion
1) Multiple steps. The DeepScaling system tries to see how many resources it will need in the near future to predict scaling demands and satisfy these future needs. It does so by estimating CPU utilization, but it does so indirectly, as it first tries to predict the workloads and then converts these workload estimates into CPU requirements. Why not build a CPU model directly and learn it that way? Our understanding is that decoupling the two processes has several advantages. The workloads for different services can be learned and predicted separately. Adding or removing services from the cluster does not require retraining the model if the CPU requirement can be estimated from the sum of these predicted workloads. Similarly, if a service changes significantly and requires a different amount of resources for the same work, the system can adjust that in the CPU estimator. In the worst case, if the workload characteristics have changed as well, again, only the model for a service needs to be retrained.
2) Backup autoscaling. One possible problem we discussed was the ability to react to unexpected changes. With a purely predictive system, we believe there is a need for a rule-based backup that can kick in if the predictive model failed.