ZooKeeper is not new, it has been around for quite some time now, yet I feel like not many people who use it in one way or another do understand what it is. ZooKeeper is used by so many distributed systems at the moment that it became a crucial part of the distributed computing, and I feel like it is time for me to learn what it really is and how it works. The service is described in “ZooKeeper: Wait-free coordination for Internet-scale systems” paper.
ZooKeeper is a system used to coordinate processes in distributed applications. According to the authors of the paper, one of the simplest types of coordination is configuration, so it makes absolute sense why ZooKeeper is used to configure so many different distributed applications, but of course, the true strength of ZooKeeper is in much more complicated coordination scenarios. ZooKeeper service itself is running on multiple servers and uses replication to achieve high availability and improve performance.
ZooKeeper does not use locks or any other blocking constructs to achieve coordination, because such blocking primitives can significantly reduce the performance. Instead, it utilizes a non-blocking pipe line architecture with a hierarchical data structure to which clients, or users of ZooKeeper service, can read and write data. Such data structure needs to provide certain guarantees in order to provide coordination capabilities:
- FIFO client ordering
- Linearizable write operations.
Data Structure
ZooKeeper’s hierarchical data structure is similar to the file system as each data object, called znode, can be accessed for read or write using a hierarchical path name. The figure below, taken form the paper, illustrates the concept of file-system like hierarchical data model.
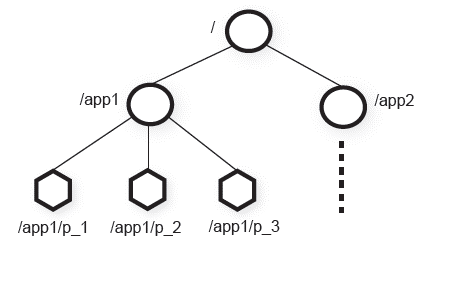
Figure 1. Hierarchical data model
There are two types of znodes: Regular and Ephemeral. Both types store data, but only regular znodes can have children. Another difference between regular and ephemeral znodes is who gets to delete it. Regular znodes can only be deleted by the client, while ephemeral have a shorter lifespan and can be removed by ZooKeeper server when client session terminates. Znodes are not meant for general data storage, although depending on the application some information can be preserved for prolonged time.
A client can manipulate znodes using the following set of commands:
- create – creates a new znode
- delete – removes an existing znode
- exists – checks whether a znode exists at specified path
- getData – gets data of a
- setData – writes data to a znode
- getChildren – lists the children of a znode
- sync – waits for updates propagation to the server
Each of the operation above can execute in a synchronous or asynchronous mode. If client executes a command synchronously, it will block and wait for ZooKeeper to respond to the operation. More interesting is the asynchronous execution. In this mode client can issue multiple requests to the ZooKeeper service and perform some other operation while waiting on the response. The responses are guaranteed to arrive to the client in the order of the requests issues.
Actions of checking the existence of a znode or getting data and getting children can have watches associated with them. If a watch is created for an action, in addition to normally completing the requests, ZooKeeper will issue a notification to the client when the data is changed on a znode with a watch.
ZooKeeper API allows client programmer to implement various kinds of more complex coordination primitives of their choice including the blocking constructs, such as locks and barriers.
Guarantees
Zookeeper has two event ordering guarantees that allow it to be used for coordination. First-in-First-out client order guarantee enforces the order in which a client receives the responses to multiple a synchronous calls issued to the service. This guarantee establishes that all requests from a client are executed in the same order as a client issued the requests. ZooKeeper also enforces the Linearizability of write operation, meaning that all state changes are serializable and respect precedence. In other words, all write operations get replicated to all ZooKeeper servers in the same order they have been received from the client.
Implementation
ZooKeeper is built in a distributed manner and runs on multiple servers to provide high availability. ZooKeeper’s data is replicated across all the servers used by the service.
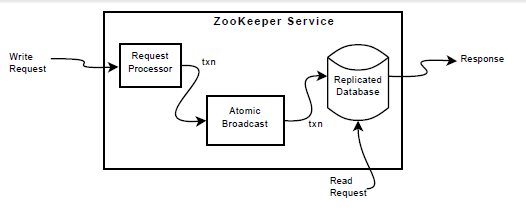
Figure 2. ZooKeeper Service (Source: ZooKeeper: Wait-free coordination for Internet-scale systems)
The figure above is a high level illustration of a ZooKeeper service. Read and Write requests scenarios are depicted in the figure. When a write request comes into the system, it is being processed, forwarded to a single “leader” server, state changes are coordinated among the servers and finally the request data is saved to the replicated database. Read requests need no coordination and since each ZooKeeper server has entire replica of all the data, the information is simply read from the local copy and sent back to the client.
Coordination among ZooKeeper servers is a very important as it ensures each copy has correct state and data read from a database copy on one server is the same as on other servers in the system. The coordination protocol also provides fault tolerance for the system, and in theory the system can continue correct operation as long as the majority of ZooKeeper servers are not faulty. The coordination step between ZooKeeper machines is depicted in the “Atomic broadcast” step in the Figure 2.
Replicated database is another important pieces of ZooKeeper service. Database is in used to store all znodes. It is in-memory and fully replicated, meaning that each properly operating server has a full replica of all ZooKeeper data. Snapshots of the database are periodically written to the disk to facilitate database recover if the server crashes for any reason and is restored later.
With an easy and intuitive API ZooKeepers allows to coordinate large scale distributed system, all while maintaining high availability and fault tolerance. In this little summary I tried to depict the basics of the service, without going into details on API or how coordination between ZooKeeper servers happen, as these are immense topics on their own.