serverless
-
Reading Group #149. On-demand Container Loading in AWS Lambda
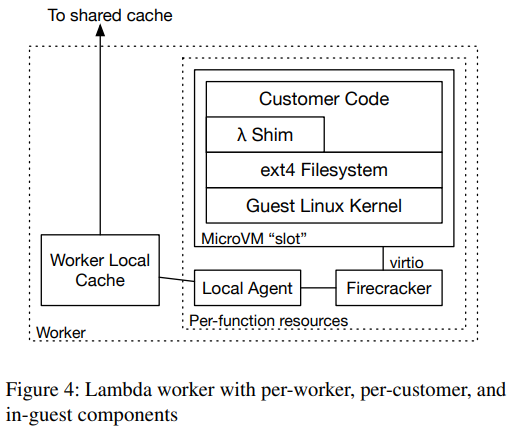
For the 149th paper in the reading group, we read “On-demand Container Loading in AWS Lambda” by Marc Brooker, Mike Danilov, Chris Greenwood, and Phil Piwonka. This paper describes the process of managing the deployment of containers in AWS Lambda. See, when AWS Lambda first came out, its runtime was somewhat limited — users could…
-
Reading Group. Palette Load Balancing: Locality Hints for Serverless Functions
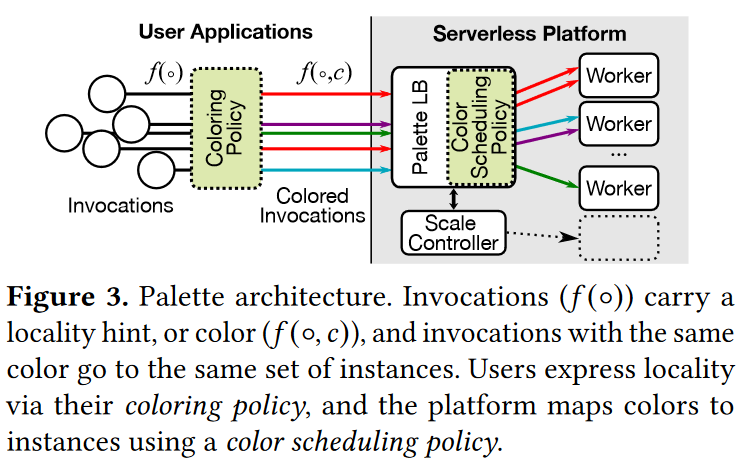
This week, our reading group focused on serverless computing. In particular, we looked at the “Palette Load Balancing: Locality Hints for Serverless Functions” EuroSys’23 paper by Mania Abdi, Sam Ginzburg, Charles Lin, Jose M Faleiro, Íñigo Goiri, Gohar Irfan Chaudhry, Ricardo Bianchini, Daniel S. Berger, Rodrigo Fonseca. I did a short improvised presentation since the…
-
Reading Group. Faster and Cheaper Serverless Computing on Harvested Resources
The 83rd paper in the reading group continues with another SOSP’21 paper: “Faster and Cheaper Serverless Computing on Harvested Resources” by Yanqi Zhang, Íñigo Goiri, Gohar Irfan Chaudhry, Rodrigo Fonseca, Sameh Elnikety, Christina Delimitrou, Ricardo Bianchini. This paper is the second one in a series of harvested resources papers, with the first one appearing in…
-
One Page Summary. Photons: Lambdas on a diet
Recently, to prepare for a class I teach this semester, I went through the “Photons: Lambdas on a diet” SoCC’20 paper by Vojislav Dukic, Rodrigo Bruno, Ankit Singla, Gustavo Alonso. This is a very well-written paper with a ton of educational value for people like me who are only vaguely familiar with serverless space! The…
Search
Recent Posts
- Paper #196. The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling
- Paper #193. Databases in the Era of Memory-Centric Computing
- Paper #192. OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck
- Paper #191: Occam’s Razor for Distributed Protocols
- Spring 2025 Reading List (Papers ##191-200)
Categories
- One Page Summary (10)
- Other Thoughts (10)
- Paper Review and Summary (14)
- Pile of Eternal Rejections (2)
- Playing Around (14)
- Reading Group (103)
- RG Special Session (4)
- Teaching (2)