metastabiilty
-
Reading Group #152. Blueprint: A Toolchain for Highly-Reconfigurable Microservice Applications

The 152nd reading group meeting continued the microservices discussion started in the 151st paper. We read the “Blueprint: A Toolchain for Highly-Reconfigurable Microservice Applications” SOSP’23 paper by Vaastav Anand, Deepak Garg, Antoine Kaufmann, and Jonathan Mace. The premise of the Blueprint is the separation of the app’s logic and most of the infrastructure/ops concerns. This…
-
Metastable Failures in the Wild
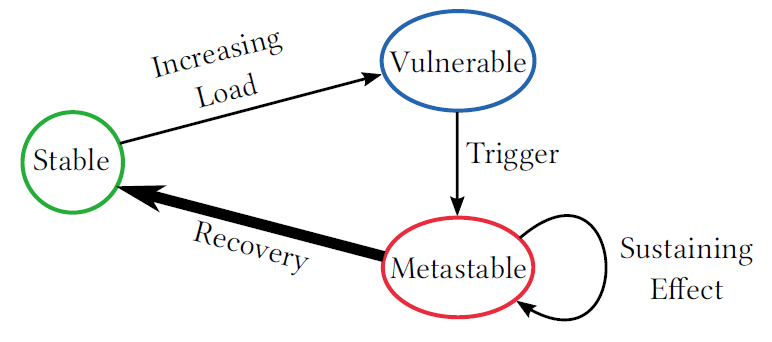
Metastable failures in distributed systems are failures that “feed” and strengthen their own “failed” condition. The main characteristic of a metastable failure is a positive feedback loop that keeps the system in a degraded/failed state. These failures are hard to spot, as they always start with some other distraction — some trigger event that nudges…
-
Metastable Failures in Distributed Systems
Metastability is a stable state of a dynamical system other than the system’s state of least energy. – Wikipedia Distributed systems often fail spectacularly and unpredictably. They are a cause for a headache and sleepless on-call nights for way too many engineers. And this is despite lots of efforts to understand the failures, and all…
Search
Recent Posts
- Paper #196. The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling
- Paper #193. Databases in the Era of Memory-Centric Computing
- Paper #192. OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck
- Paper #191: Occam’s Razor for Distributed Protocols
- Spring 2025 Reading List (Papers ##191-200)
Categories
- One Page Summary (10)
- Other Thoughts (10)
- Paper Review and Summary (14)
- Pile of Eternal Rejections (2)
- Playing Around (14)
- Reading Group (103)
- RG Special Session (4)
- Teaching (2)