epaxos
-
Scalable but Wasteful or Why Fast Replication Protocols are Actually Slow
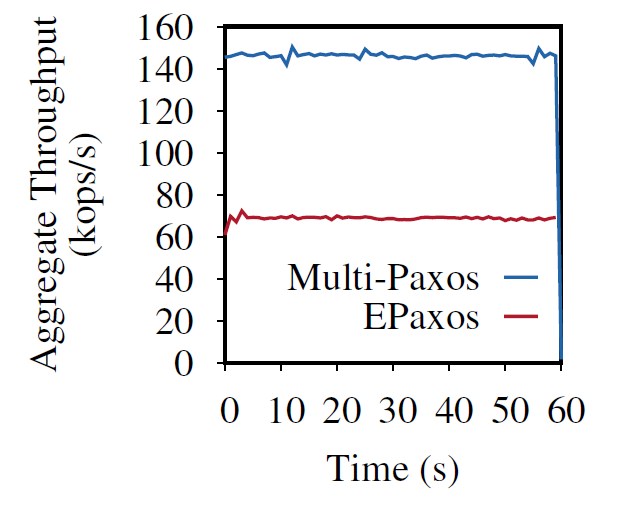
In the last decade or so, quite a few new state machine replication protocols emerged in the literature and the internet. I am “guilty” of this myself, with the PigPaxos appearing in this year’s SIGMOD and the PQR paper at HotStorage’19. There are better-known examples as well — EPaxos inspired a lot of development in…
-
Paper Summary: Bolt-On Global Consistency for the Cloud
This paper appeared in SOCC 2018, but caught my Paxos attention only recently. The premise of the paper is to provide strong consistency in a heterogeneous storage system spanning multiple cloud providers and storage platforms. Going across cloud providers is challenging, since storage services at different clouds cannot directly talk to each other and replicate the…
-
EPaxos: Consensus with no leader
In my previous post I talked about Raft consensus algorithm. Raft has a strong leader which may present some problems under certain circumstances, for example in case of leader failure or when deployed over a wide area network (WAN). Egalitarian Paxos, or EPaxos, discards the notion of a leader and allows each node to be…
Search
Recent Posts
- Paper #196. The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling
- Paper #193. Databases in the Era of Memory-Centric Computing
- Paper #192. OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck
- Paper #191: Occam’s Razor for Distributed Protocols
- Spring 2025 Reading List (Papers ##191-200)
Categories
- One Page Summary (10)
- Other Thoughts (10)
- Paper Review and Summary (14)
- Pile of Eternal Rejections (2)
- Playing Around (14)
- Reading Group (103)
- RG Special Session (4)
- Teaching (2)