efficiency
-
Paper #196. The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling

The last paper we covered in the Distributed Systems Reading group discussed CPUs, data centers, scheduling, and carbon emissions—we read “The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling.” Below is my improvised presentation of this paper for the reading group. This paper was an educational read for me, as I learned…
-
Reading Group 151. Towards Modern Development of Cloud ApplicationsReading Group 151.
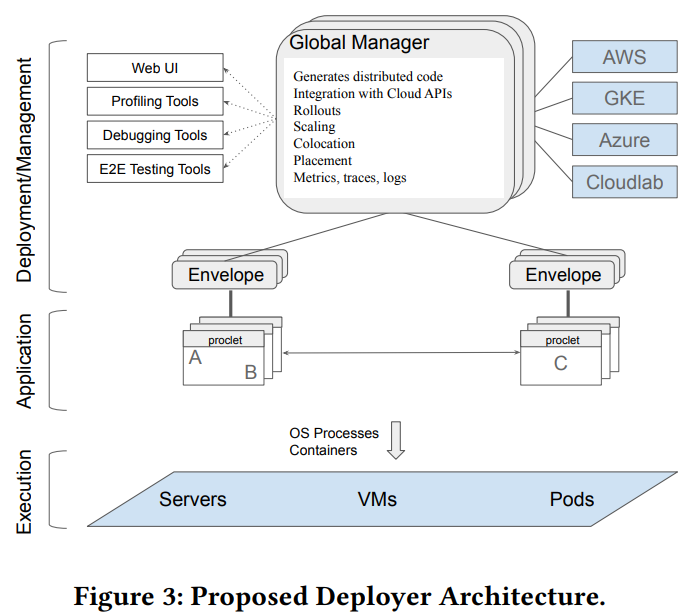
We kicked off the winter term set of papers in the reading group with the “Towards Modern Development of Cloud Applications” HotOS’23 paper. The paper proposes a different approach to designing distributed applications by replacing the microservice architecture style with something more fluid. The paper argues that splitting applications into microservices from the get-go can…
-
Reading Group. CompuCache: Remote Computable Caching using Spot VMs
In the 92nd reading group meeting, we have covered “CompuCache: Remote Computable Caching using Spot VMs” CIDR’22 paper by Qizhen Zhang, Philip A. Bernstein, Daniel S. Berger, Badrish Chandramouli, Vincent Liu, and Boon Thau Loo. Cloud efficiency seems to be a popular topic recently. A handful of solutions try to improve the efficiency of the…
-
Reading Group. Faster and Cheaper Serverless Computing on Harvested Resources
The 83rd paper in the reading group continues with another SOSP’21 paper: “Faster and Cheaper Serverless Computing on Harvested Resources” by Yanqi Zhang, Íñigo Goiri, Gohar Irfan Chaudhry, Rodrigo Fonseca, Sameh Elnikety, Christina Delimitrou, Ricardo Bianchini. This paper is the second one in a series of harvested resources papers, with the first one appearing in…
Search
Recent Posts
- Paper #196. The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling
- Paper #193. Databases in the Era of Memory-Centric Computing
- Paper #192. OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck
- Paper #191: Occam’s Razor for Distributed Protocols
- Spring 2025 Reading List (Papers ##191-200)
Categories
- One Page Summary (10)
- Other Thoughts (10)
- Paper Review and Summary (14)
- Pile of Eternal Rejections (2)
- Playing Around (14)
- Reading Group (103)
- RG Special Session (4)
- Teaching (2)