consensus
-
Paper #191: Occam’s Razor for Distributed Protocols

We have been doing a Zoom distributed systems paper reading group for 5 years and have covered around 190 papers. This semester, we should reach the milestone of 200 papers. Over the years, my commitment to the group has varied — at some point, I was writing paper reviews, and more recently, I’ve had less…
-
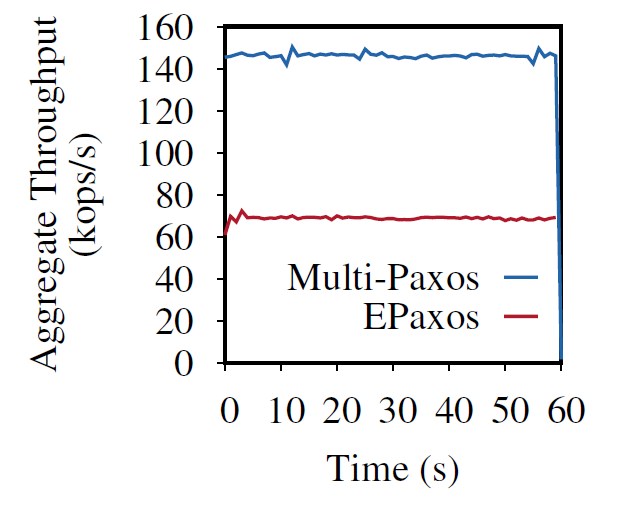
Reading Group. EPaxos Revisited.
In the 88th DistSys meeting, we discussed the “EPaxos Revisited” NSDI’21 paper by Sarah Tollman, Seo Jin Park, and John Ousterhout. We had an improvised presentation, as I had to step in and talk about the paper on short notice without much preparation. EPaxos Background Today’s paper re-evaluates one very popular in academia state machine…
-
Reading Group. Rabia: Simplifying State-Machine Replication Through Randomization
We covered yet another state machine replication (SMR) paper in our reading group: “Rabia: Simplifying State-Machine Replication Through Randomization” by Haochen Pan, Jesse Tuglu, Neo Zhou, Tianshu Wang, Yicheng Shen, Xiong Zheng, Joseph Tassarotti, Lewis Tseng, Roberto Palmieri. This paper appeared at SOSP’21. A traditional SMR approach, based on Raft or Multi-Paxos protocols, involves a…
-
Reading Group. Impossibility of Distributed Consensus with One Faulty Process
Our reading group is on a short winter break, and I finally have some time to catch up with reading group writing and videos. Our 81st paper was a foundational paper in the field of consensus — we looked at the famous FLP impossibility result. The “Impossibility of Distributed Consensus with One Faulty Process” paper…
-
Reading Group. Viewstamped Replication Revisited
Our 74th paper was a foundational one — we looked at Viestamped Replication protocol through the lens of the “Viewstamped Replication Revisited” paper. Joran Dirk Greef presented the protocol along with bits of his engineering experience using the protocol in practice. Viestamped Replication (VR) solves the problem of state machine replication in a crash fault…
-
Reading Group. Fault-Tolerant Replication with Pull-Based Consensus in MongoDB
In the last reading group meeting, we discussed MongoDB‘s replication protocol, as described in the “Fault-Tolerant Replication with Pull-Based Consensus in MongoDB” NSDI’21 paper. Our reading group has a few regular members from MongoDB, and this time around, Siyuan Zhou, one of the paper authors, attended the discussion, so we had a perfect opportunity to…
-
Scalable but Wasteful or Why Fast Replication Protocols are Actually Slow
In the last decade or so, quite a few new state machine replication protocols emerged in the literature and the internet. I am “guilty” of this myself, with the PigPaxos appearing in this year’s SIGMOD and the PQR paper at HotStorage’19. There are better-known examples as well — EPaxos inspired a lot of development in…
-
Reading Group. XFT: Practical Fault Tolerance beyond Crashes
In the 57th reading group meeting, we continued looking at byzantine fault tolerance. In particular, we looked at “XFT: Practical Fault Tolerance beyond Crashes” OSDI’16 paper. Today’s summary & discussion will be short, as I am doing it way past my regular time. The paper talks about a fault tolerance model that is stronger than…
-
Reading Group. Paxos vs Raft: Have we reached consensus on distributed consensus?
In our 54th reading group meeting, we were looking for an answer to an important question in the distributed systems community: “What about Raft?” We looked at the “Paxos vs Raft: Have we reached consensus on distributed consensus?” paper to try to find the answer. As always, we had an excellent presentation, this time by…
-
Reading Group. Microsecond Consensus for Microsecond Applications
Our 43rd reading group paper was about an extremely low-latency consensus using RDMA: “Microsecond Consensus for Microsecond Applications.” The motivation is pretty compelling — if you have a fast application, then you need fast replication to make your app reliable without holding it back. How fast are we talking here? Authors go for ~1 microsecond…
Search
Recent Posts
- Paper #196. The Sunk Carbon Fallacy: Rethinking Carbon Footprint Metrics for Effective Carbon-Aware Scheduling
- Paper #193. Databases in the Era of Memory-Centric Computing
- Paper #192. OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck
- Paper #191: Occam’s Razor for Distributed Protocols
- Spring 2025 Reading List (Papers ##191-200)
Categories
- One Page Summary (10)
- Other Thoughts (10)
- Paper Review and Summary (14)
- Pile of Eternal Rejections (2)
- Playing Around (14)
- Reading Group (103)
- RG Special Session (4)
- Teaching (2)