In the last decade or so, quite a few new state machine replication protocols emerged in the literature and the internet. I am “guilty” of this myself, with the PigPaxos appearing in this year’s SIGMOD and the PQR paper at HotStorage’19. There are better-known examples as well — EPaxos inspired a lot of development in this area. However, there seems to be a big disconnect between literature and production. While many sophisticated protocols, such as EPaxos, Atlas, SDPaxos, Comprmentalized Paxos, appear in the literature, and some of them are rather popular in the academic community, the production systems tend to rely on more conservative approaches based on Raft, Multi-Paxos, or primary-backup.
There are probably a few reasons for this disconnect. For instance, as we discussed in Paxos vs Raft reading group meeting, explaining protocols in terminology closer to actual code and having good reliable reference implementations help with adoption. However, the difficulty of implementing some technology should not be a roadblock when this technology offers substantial improvements.
Well, it appears that there are substantial quantitative improvements. Consider EPaxos. The protocol presents a leader-less solution, where any node can become an opportunistic coordinator for an operation. The exciting part is that EPaxos can detect conflicts, and when operations do not conflict with each other, both of them can succeed in just one round trip time to a fast quorum. The original paper claims better throughput than Multi-Paxos, and this is not surprising, as EPaxos avoids a single-leader bottleneck of Multi-Paxos and allows non-conflicting operations to proceed concurrently. This is a big deal!
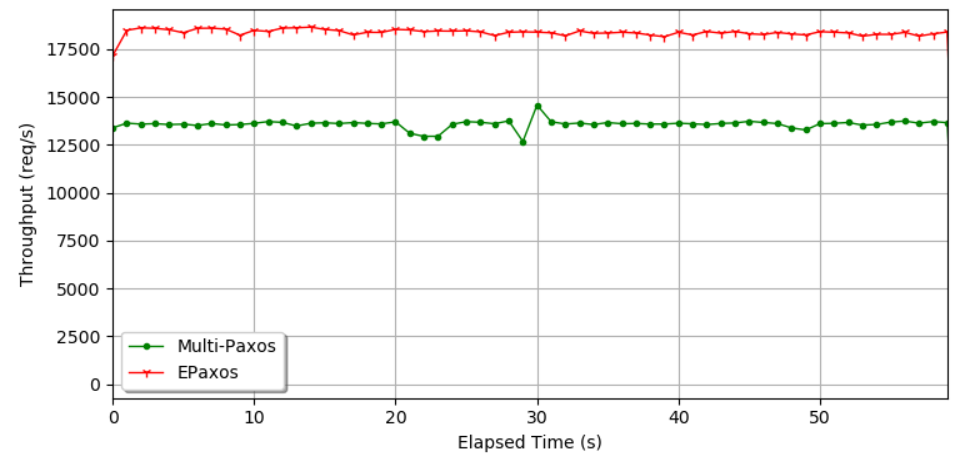
I wanted to find the truth here, so I and a couple of colleagues worked on experimentally testing Multi-Paxos and EPaxos. We performed a simple experiment, shown in the figure here, to confirm EPaxos’ performance advantage, and we achieved somewhere between 15-25% better throughput in 5 nodes EPaxos than Multi-Paxos when running on identical VMs (EC2 m5a.large with 2vCPUs and 8 GiB of RAM). Original EPaxos paper has a bit larger performance difference in some situations, but we have spent significantly more time on our Multi-Paxos implementation and optimizations than EPaxos. Anyway, we see a substantial improvement that was stable, reproducible, and quite large to make a real-world difference. Not to mention that EPaxos has a few other advantages, such as lower latency in geo-distributed deployments. So what gives?
I have a theory here. I think many of these “faster” protocols are often slower in real life. This has to do with how the protocols were designed and evaluated in the first place. So bear with me and let me explain.
Most evaluations of these consensus-based replication protocol papers are conducted in some sort of dedicated environment, be it bare-metal servers in the lab or VMs in the cloud. These environments have fixed allocated resources, and to improve the performance we ideally want to maximize the resource usage of these dedicated machines. Consider Multi-Paxos or Raft. These protocols are skewed towards the leader, causing the leader to do disproportionately more work than the followers. So if we deploy Multi-Paxos in five identical VMs, one will be used a lot more than the remaining four, essentially leaving unused resources on the table. EPaxos, by design, avoids the leader bottleneck and harvests all the resources at all nodes. So naturally, EPaxos outperforms Multi-Paxos by using the resources Multi-Paxos cannot get a hold of ue to its design. Such uniform resource usage across nodes is rather desirable, as long as avoiding the leader bottleneck and allowing each node to participate equally comes cheaply.
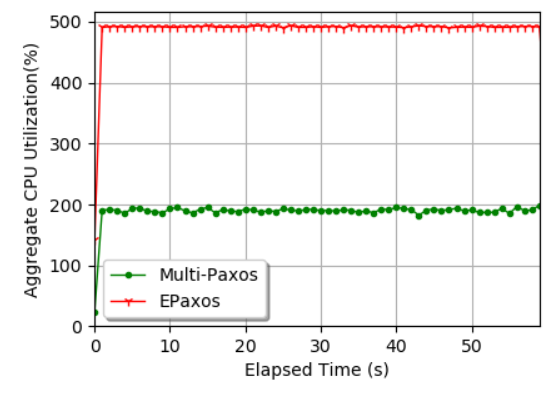
Unfortunately, it is not the case, and EPaxos’ ability to use resources that would have been left idle by Multi-Paxos comes at a steep penalty! Intuitively, EPaxos needs to do a lot more work to maintain safety and remain leader-less — it needs to communicate the dependencies, compute dependency graphs, check for conflicts in these graphs, and resolve the conflicts as needed. This added complexity contrasts with Multi-Paxos that provides most of its safety via a few simple comparisons both at the leader and followers. To try to estimate the cost of EPaxos’ role uniformity, we need to look at resource usage. In the same experimental run as in the absolute performance figure earlier, we have measured CPU usage across all VMs. Expectedly, we were able to observe that EPaxos is very good at using all available resources, and Multi-Paxos consumes the entire CPU only at one node – the leader. However, it does not take long to spot something odd if we start looking at the aggregate resource usage, shown in the figure here. It turns out that Multi-Paxos achieved nearly 14k ops/s of throughput consuming roughly 200% CPU (and leaving 300% unused), while EPaxos did a bit over 18k ops/s with all 500% of aggregate CPU utilization.

This suggests that EPaxos needs overall more CPU cycles across all nodes to finish each operation. We can see this better if we normalize the throughput per the amount of CPU consumed. As seen in the figure, this normalized throughput presents a big gap in the efficiency of protocols. Of course, this gap may vary and will depend on the implementation. It may even shrink if some better engineers implement EPaxos, but I also think there is a fundamental issue here. EPaxos and many other protocols were designed to take advantage of all allocated resources in the cluster since allocated but unused resources are wasted. This resource usage paradigm is common when we have dedicated servers or VMs. However, technology has moved on, and we rarely deploy replicated services or systems all by themselves in isolation. With the advances in virtualization and containerization, we increasingly deploy replicated systems in resource-shared environments that are designed to pack applications across clusters of servers in a way to avoid having idle physical resources.
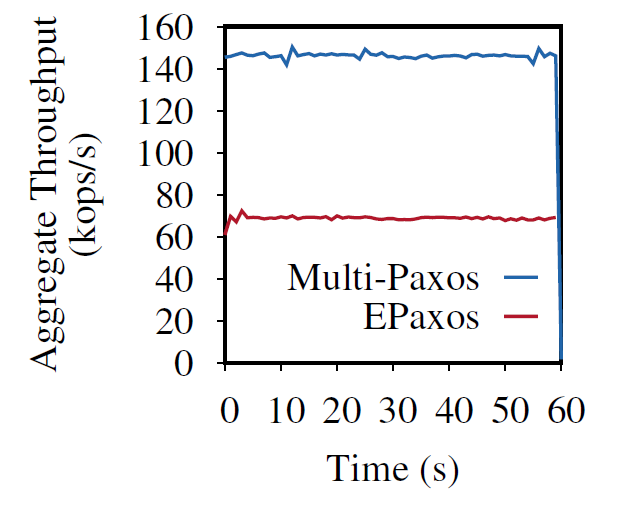
Moreover, most replicated systems are sharded, so we normally have multiple instances of the replication protocol supporting shards of one larger system. This makes task-packing simpler as we have many relatively uniform tasks to schedule between machines. Consider Yugabyte DB for example. Karthik Ranganathan in his talk described how the system schedules raft groups across a cluster such that some server has a few resource-heavy raft leaders and plenty more resource-light raft followers. This type of packing allows Yugabyte (and Cockroach DB, Spanner, Cosmos DB, and so on) to achieve uniform resource usage on VMs or dedicated servers while having non-uniform, but efficient replication protocols. Here I show how 5 instances of Multi-Paxos compare with 5 instances of EPaxos when deployed on larger servers (32 GiB RAM and 8 vCPUs). This drastic difference compared to the dedicated environment is due to the fact that we were able to pack multiple instances of Multi-Paxos to consume all the resources of the cluster, and clock-for-clock, EPaxos has no chance of winning due to its lower efficiency.
Ok, so I think there are quite a few things to unpack here.
- Absolute performance as measured on dedicated VMs or bare-metal servers is not necessarily a good measure of performance in real-life, especially in resource-shared setting (aka the cloud)
- We need to consider efficiency when evaluating protocols to have a better understanding of how well the protocol may behave in the resource-shared, task-packed settings
- The efficiency of protocols is largely under-studied, as most evaluations from academic literature simply focus on absolute performance.
- The efficiency (or the lack of it) may be the reason why protocols popular in academia stay in academia and do not get wide adoption in the industry.
In conclusion, I want to stress that I am not picking on EPaxos. It is a great protocol that has inspired a lot of innovation in the area distributed consensus. Moreover, I am sure there are use cases for EPaxos (or more recent extensions, such as Atlas), especially in the WAN setting when trading of some efficiency for better latency may be acceptable. Many other protocols (mine included) may have similar efficiency problems, as they approach the performance issue similarly – find the bottlenecked node and move its work elsewhere. The fundamental issues at play here are that (1) moving the work elsewhere comes at an efficiency penalty, and (2) in many modern environments there may not be any resource available for such “moved” work due to resource budgets and tight task-packing.
I, Abutalib Aghayev, and Venkata Swaroop Matte discuss the efficiency issues in a bit more detail in our upcoming HotStorage’21 paper: “Scalable but Wasteful: Current State of Replication in the Cloud.”